依存语法分析

语法分析(syntactic parsing )其目标是分析句子的语法结构并将其表示为容易理解的结构(通常是树形结构)。
短语结构树
语言具备有自顶而下的层级关系,固定数量的语法结构能够生成无数句子。
比如,通过下列两个语法规律,我们就能够生成所有名词短语。
- 名词短语可以由名词和名词短语组成。eg:“上海+浦东”,“机场+航站楼”
- 名词短语还可以由名词和名词组成。eg:“上海+浦东+机场+航站楼”
在语言学中,这样的语法被称为上下文无关文法,它由如下组件构成:
- 终结符结合 Σ,比如汉语的一个词表。
- 非终结符集合 V,比如“名词短语”“动词短语”等短语结构组成的集合。V 中至少包含一个特殊的非终结符,即句子符或初始符,计作 S。
- 推导规则 R,即推导非终结符的一系列规则: V -> V U Σ。
我们可以从 S 出发,逐步推导非终结符。一个非终结符至少产生一个下级符号,如此一层一层地递推下去,我们就得到了一棵语法树。但在NLP中,我们称其为短语结构树。
短语结构语法描述了如何自顶而下的生成一个句子,反过来,句子也可以用短语结构语法来递归的分解。
例如“上海 浦东 开发 与 法制 建设 同步”,分解成如下图的短语结构树:
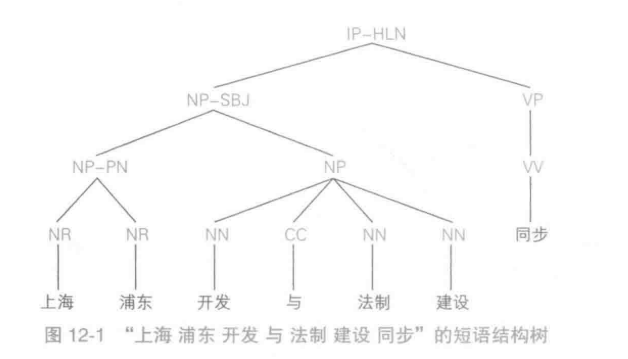
解释:句子中主语为由两个名词组成“上海 浦东”“开发 与 法制 建设”,谓语为”同步“,再将每个名词进行分解为词语,即可得。
图中的字母标记含义如下:
| 标记 | 释义 |
|---|---|
| IP-HLN | 单句-标题 |
| NP-SBJ | 名词短语-主语 |
| NP-PN | 名词短语-代词 |
| NP | 名词短语 |
| VP | 动词短语 |
依存语法树
不同于短语结构树,依存句法树关注的是句子中词语之间的语法联系,并且将其约束为树形结构。
依存句法理论:词与词之间存在主从关系。在句子中,如果一个词修饰另一个词,则称修饰词为从属词,被修饰的词语称为支配词,两者之间的语法关系称为依存关系。比如句子“大梦想”中形容词“大”与名词“梦想"之间的依存关系如图所示:

图中的箭头方向由支配词指向从属词,如果将一个句子中所有词语的依存关系以有向边的形式表示出来,就会得到一棵树,称为依存句法树。
比如句子“弱小的我也有大梦想”的依存句法树如图所示。
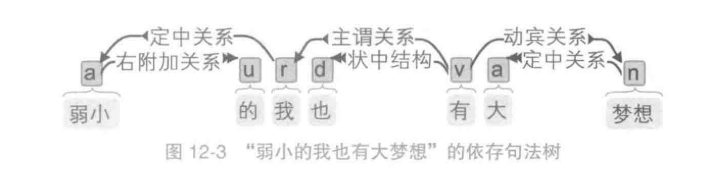
依存句法树也有 4 个约束性的公理。
- 有且只有一个词语(ROOT,虚拟根节点,简称虚根)不依存于其他词语。
- 除此之外所有单词必须依存于其他单词。
- 每个单词不能依存于多个单词。
- 如果单词 A 依存于 B,那么位置处于 A 和 B 之间的单词 C 只能依存于 A、B 或 AB 之间的单词。
这 4 条公理分别约束了依存句法树的根节点唯一性、 连通、无环和投射性。
中文依存句法树库
目前最有名的开源自由的依存树库有:
- UD( Universal Dependencies),官网:https://universaldependencies.org
- CTB,只不过需要额外利用一些工具将短语结构树转换为依存句法树,官网:https://catalog.ldc.upenn.edu/LDC2005T01
依存句法树的可视化
工具如下:
- 南京大学汤光超开发的 Dependency Viewer。导入 .conll 扩展名的树库文件即可。
- brat 标注工具。
可视化工具可以帮助我们理解句法树的结构,比较句子之间的不同。
依存句法分析的方法
通常输入词语和词性,输出一棵依存句法树。
基于图的依存句法分析
依存句法树其实是完全图的一个子图,如果为完全图中的每条边是否属于句法树的可能性打分,然后就可以利用 Prim 算法找出最大生成树,作为依存句法树。这样将整棵树的分数分解( factorize )为每条边上的分数之和,然后在图上搜索最优解的方法统称为基于图的算法。
基于转移的依存句法分析
我们以“人 吃 鱼”这个句子为例子,手动构建依存句法树。
- 从“吃”连线到“人”建立依存关系,主谓关系。
- 从“吃”连线到“鱼”建立依存关系,动宾关系。
如果机器学习模型能够根据句子的某些特征准确地预测这些转移动作,那么计算机就能够根据这些动作拼装出正确的依存句法树了。这种拼装动作称为转移( transition),而这类算法统称为基于转移的依存句法分析。
Arc-Eager 转移系统
一个转移系统 S 由 4 个部件构成: S = (C,T,Cs,Ct),其中:
- C 是系统状态的集合
- T 是所有可执行的转移动作的集合。
- Cs 是一个初始化函数
- Ct 为一系列终止状态,系统进入该状态后即可停机输出最终的动作序列。
而系统状态又由 3 元祖构成: C = (σ,β,A) 其中:
- σ 为一个存储单词的栈。
- β 为存储单词的队列
- A 为已确定的依存弧的集合。
Arc-Eager 转移系统的转移动作集合详见下表:
| 动作名称 | 条件 | 解释 |
|---|---|---|
| Shift | 队列 β 非空 | 将β队首单词 i 压栈 |
| LeftArc | 栈顶单词 i 没有支配词 | 将σ栈顶单词 i 的支配词设为队首单词 j,即 i 作为 j 的子节点 |
| RightArc | 队首单词 j 没有支配词 | 将β队首单词 j 的支配词设为栈顶单词 i,即 j 作为 i 的子节点 |
| Reduce | 栈顶单词 i 已有支配词 | 将σ栈顶单词 i 出栈 |
实例:以“人 吃 鱼”案例,Arc-Eager 的执行步骤如下:

此时集合 A 中的依存弧为一颗依存句法树。
训练
对基于转移的依存句法分析器而言,它学习和预测的对象是一系列转移动作。然而依存句法树库是一棵树,并不是现成的转移动作序列。这时候就需要一个算法将语料库中的依存句法树转移为正确地转移动作序列。
可以使用感知机进行训练得到转移动作序列,感知机能够迭代的优化模型,使得分值最高的可以正确的抵达句法树的转义序列。
训练步骤如下:
-
读入一个训练样本,提取特征,创建 ArcEager 的初始系统状态集合C。
-
若 C 不是终止状态,反复进行转移序列,修正参数。

- 算法终止,返回返回模型参数 w。
实现
HanLP中对依存句法分析提供了API
from pyhanlp import *
import zipfile
import os
from pyhanlp.static import download, remove_file, HANLP_DATA_PATH
##获取测试数据路径,根目录由配置文件指定
def test_data_path():
data_path = os.path.join(HANLP_DATA_PATH, 'test')
if not os.path.isdir(data_path):
os.mkdir(data_path)
return data_path
## 验证是否存在语料库,如果没有自动下载
def ensure_data(data_name, data_url):
root_path = test_data_path()
dest_path = os.path.join(root_path, data_name)
if os.path.exists(dest_path):
return dest_path
if data_url.endswith('.zip'):
dest_path += '.zip'
download(data_url, dest_path)
if data_url.endswith('.zip'):
with zipfile.ZipFile(dest_path, "r") as archive:
archive.extractall(root_path)
remove_file(dest_path)
dest_path = dest_path[:-len('.zip')]
return dest_path
## 模型,语料库加载
KBeamArcEagerDependencyParser = JClass('com.hankcs.hanlp.dependency.perceptron.parser.KBeamArcEagerDependencyParser')
CTB_ROOT = ensure_data("ctb8.0-dep", "http://file.hankcs.com/corpus/ctb8.0-dep.zip")
CTB_TRAIN = CTB_ROOT + "/train.conll"
CTB_DEV = CTB_ROOT + "/dev.conll"
CTB_TEST = CTB_ROOT + "/test.conll"
CTB_MODEL = CTB_ROOT + "/ctb.bin"
BROWN_CLUSTER = ensure_data("wiki-cn-cluster.txt", "http://file.hankcs.com/corpus/wiki-cn-cluster.zip")
parser = KBeamArcEagerDependencyParser.train(CTB_TRAIN, CTB_DEV, BROWN_CLUSTER, CTB_MODEL)#模型训练
print(parser.parse("人吃鱼"))#进行句法分析
score = parser.evaluate(CTB_TEST)##标准化评测
print("UAS=%.1f LAS=%.1f\n" % (score[0], score[1]))
结果
1 人 人 N NN _ 2 nsubj _ _
2 吃 吃 V VV _ 0 ROOT _ _
3 鱼 鱼 N NN _ 2 dobj _ _
UAS=83.3% LAS=81.0% #83.3的词被准确预测,81的依存弧被准确预测
实例:基于依存句法分析的意见抽取
可以利用依存句法分析实现一个意见抽取的例子,提取下列商品评论中的属性和买家评价。
电池非常棒,机身不长,长的是待机,但是屏幕分辨率不高。
通过依存句法分析,再通过依存弧是否是“属性关系”,寻找支配词的子节点中的主题词,以该主题词作为名词的意见。
from pyhanlp import *
CoNLLSentence = JClass('com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLSentence')
CoNLLWord = JClass('com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLWord')
IDependencyParser = JClass('com.hankcs.hanlp.dependency.IDependencyParser')
KBeamArcEagerDependencyParser = JClass('com.hankcs.hanlp.dependency.perceptron.parser.KBeamArcEagerDependencyParser')
def main():
parser = KBeamArcEagerDependencyParser()
tree = parser.parse("电池非常棒,机身不长,长的是待机,但是屏幕分辨率不高。")
print(tree)
extactOpinion3(tree)
# 检测名词词语的依存弧是否是“属性关系”,
# 如果是,则寻找支配词的子节点中的主题词
# 以该主题词作为名词的意见。
def extactOpinion3(tree):
for word in tree.iterator():
if word.POSTAG == "NN":
if word.DEPREL == "nsubj":
if tree.findChildren(word.HEAD, "neg").isEmpty():
print("%s = %s" % (word.LEMMA, word.HEAD.LEMMA))
else:
print("%s = 不%s" % (word.LEMMA, word.HEAD.LEMMA))
elif word.DEPREL == "attr":
top = tree.findChildren(word.HEAD, "top") # ②主题
if not top.isEmpty():
print("%s = %s" % (word.LEMMA, top.get(0).LEMMA))
if __name__ == '__main__':
main()
输出
1 电池 电池 N NN _ 3 nsubj _ _
2 非常 非常 A AD _ 3 advmod _ _
3 棒 棒 V VA _ 0 ROOT _ _
4 , , P PU _ 3 punct _ _
5 机身 机身 N NN _ 7 nsubj _ _
6 不 不 A AD _ 7 neg _ _
7 长 长 V VA _ 3 conj _ _
8 , , P PU _ 7 punct _ _
9 长 长 V VA _ 11 top _ _
10 的 的 D DEC _ 9 cpm _ _
11 是 是 V VC _ 7 conj _ _
12 待机 待机 N NN _ 11 attr _ _
13 , , P PU _ 3 punct _ _
14 但是 但是 A AD _ 18 advmod _ _
15 屏幕 屏幕 N NN _ 16 nn _ _
16 分辨率 分辨率 N NN _ 18 nsubj _ _
17 不 不 A AD _ 18 neg _ _
18 高 高 V VA _ 3 conj _ _
19 。 。 P PU _ 3 punct _ _
电池 = 棒
机身 = 不长
待机 = 长
分辨率 = 不高
可以看到物品的4 个属性评价被完整正确地提取出来了。