信息抽取及其实现

本文分别介绍抽取新词、关键词、关键短语和自动摘要的无监督学习方法。
信息抽取是一个宽泛的概念,指的是从非结构化文本中提取结构化信息的一类技术。这类技术依然分为基于规则的正则匹配、有监督学习和无监督学习等各种实现方法。我们将使用一些简单实用的无监督学习方法。由于不需要标注语料库,所以可以利用海量的非结构化文本。
新词抽取
所谓新词,就是处于语料库外的词汇
抽取步骤
- 提取出文本中的词语,无论新旧。
- 用词典过滤掉已有的词语,于是得到新词。
其中,提取出文本中的词语是关键的一步,如何能够让计算机识别词语呢?
例如:“小提琴”究竟算一个词语,还是“小+提琴”两个词语呢?
解决思路:
给定一段文本,随机取一个片段,如果这个片段左右的搭配很丰富,并且片段内部成分搭配很固定,则可以认为这是一个词。将这样的片段筛选出来,按照频次由高到低排序,排在前面的有很高概率是词。
如果文本足够大,再用通用的词典过滤掉“旧词”,就可以得到“新词”。
片段外部左右搭配的丰富程度,可以用信息熵来衡量,而片段内部搭配的固定程度可以用子序列的互信息来衡量。
信息熵
信息熵(entropy)指的是某条消息所含的信息量
对于离散型的随机变量X,信息熵的计算方法如下:
若log的底数为2的话,则信息熵的单位恰好为比特
例子:若抛硬币正面概率为p(x=正)=0.5,则单次抛硬币实验结果的信息熵为:
因此,需要1比特的信息量来存储每次抛硬币实验的结果。
具体到新词的提取中:
给定字符串 S 作为词语备选,X 定义为该字符串左边可能出现的字符(左邻字),则称 H(X) 为 S 的左信息熵,类似的,定义右信息熵 H(Y),例如语料库含有如下句子:
-
两只蝴蝶飞啊飞
-
这些蝴蝶飞走了
对于“蝴蝶”,它的左邻字及其频次为“只”为1次,"些"为1次,有两种,和上例中硬币信息熵一样,因此它的左信息熵为1,而右边只为“飞”,因此右信息熵为0。
当然,如果语料库中句子越多,那么左右信息熵也会不同。如果语料库中再收集一些句子,比如“蝴蝶效应”“蝴蝶蜕变”之类,就会观察到右信息熵会增大不少。
左右信息熵越大,说明字符串可能的搭配就越丰富,该字符串就是一个词的可能性就越大。
光考虑左右信息熵是不够的,比如“吃了一顿”“看了一遍”“睡了一晚”“去了一趟”中的了一的左右搭配也很丰富。为了更好的效果,我们还必须考虑词语内部片段的凝聚程度,这种凝聚程度由互信息衡量。
互信息
互信息指的是离散变量X,Y相关程度,定义如下:
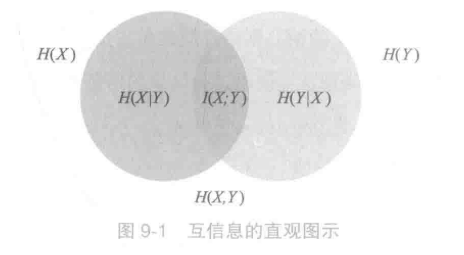
左圆圈表示H(X),右圆圈表示H(Y)。它们的并集是联合分布的信息熵H(X,Y),差集为条件嫡,交集就是互信息。可见互信息越大,两个随机变量的关联就越密切,或者说同时发生的可能性越大。
具体到新词的提取中:
例如语料库含有如下句子:
-
两只蝴蝶飞啊飞
-
这些蝴蝶飞走了
互信息X代表字符串的前缀子串,Y代表句子去掉前缀剩下的后缀。例如”蝴蝶“,X=”蝴“,Y=”蝶“。此时两者的联合分布只有一个取值,”蝴蝶“,此时期望为1,那么互信息为:
解释: 语料库总字数为16,count(蝴)=count(蝶)=2,因此p(蝴)=p(蝶)=0.125,count(蝴蝶)=2,而考虑语料库的字数,我们可以取总词频就为16。因此p(蝴,蝶)=0.125
片段可能有多种组合方式,计算上可以选取所有组合方式中互信息最小的那一种为代表。有了左右信息熵和互信息之后,将两个指标低于一定阈值的片段过滤掉,剩下的片段按频次降序排序,截取最高频次的 N 个片段即完成了词语提取流程。
实现
通过对《红楼梦》的新词抽取,提取前100个高频词,并将处于语料库中的词语进行剔除
from pyhanlp import *
import zipfile
import os
from pyhanlp.static import download, remove_file, HANLP_DATA_PATH
# 获取测试数据路径,位于$root/data/test,根目录由配置文件指定。
def test_data_path():
data_path = os.path.join(HANLP_DATA_PATH, 'test')
if not os.path.isdir(data_path):
os.mkdir(data_path)
return data_path
## 验证是否存在 MSR语料库,如果没有自动下载
def ensure_data(data_name, data_url):
root_path = test_data_path()
dest_path = os.path.join(root_path, data_name)
if os.path.exists(dest_path):
return dest_path
if data_url.endswith('.zip'):
dest_path += '.zip'
download(data_url, dest_path)
if data_url.endswith('.zip'):
with zipfile.ZipFile(dest_path, "r") as archive:
archive.extractall(root_path)
remove_file(dest_path)
dest_path = dest_path[:-len('.zip')]
return dest_path
HLM_PATH = ensure_data("红楼梦.txt", "http://file.hankcs.com/corpus/红楼梦.zip")
def extract(corpus):
word_info_list = HanLP.extractWords(IOUtil.newBufferedReader(corpus), 100)
print(word_info_list)
word_info_list = HanLP.extractWords(IOUtil.newBufferedReader(corpus), 100, True)
print(word_info_list)
if __name__ == '__main__':
extract(HLM_PATH)
其中函数 HanLP.extractWords() 的参数如下
# reader: 文本数据源
# size: 控制返回多少个词
# newWordsOnly: 为真时,程序将使用内部词库过滤掉“旧词”。
# max_word_len: 控制识别结果中最长的词语长度
# min_freq: 控制结果中词语的最低频率
# min_entropy: 控制结果中词语的最低信息熵的值,一般取 0.5 左右,值越大,越短的词语就越容易提取
# min_aggregation: 控制结果中词语的最低互信息值,一般取 50 到 200.值越大,越长的词语越容易提取
输出
[什么, 凤姐, 贾母, 黛玉, 姑娘, 宝钗, 怎么, 丫头, 如今, 老太太, 贾政, 奶奶, 自己, 贾琏, 平儿, 老爷, 东西, 告诉, 咱们, 姨妈, 薛姨妈, 所以, 探春, 紫鹃, 鸳鸯, 湘云, 如此, 妹妹, 婆子, 贾珍, 李纨, 答应, 尤氏, 晴雯, 媳妇, 屋里, 打发, 刘姥姥, 小丫头, 林黛玉, 薛蟠, 香菱, 孩子, 姊妹, 到底, 连忙, 明白, 丫鬟, 麝月, 姨娘, 哥哥, 贾蓉, 小厮, 果然, 意思, 周瑞, 怎么样, 主意, 已经, 越发, 跟前, 瞧瞧, 房中, 喜欢, 贾赦, 惜春, 句话, 雨村, 贾芸, 吩咐, 况且, 悄悄, 嫂子, 兄弟, 素日, 芳官, 金桂, 贾环, 言语, 雪雁, 时候, 多少, 许多, 嬷嬷, 迎春, 林之孝, 糊涂, 十分, 女孩, 伏侍, 奴才, 预备, 衣服, 请安, 林姑娘, 收拾, 赵姨娘, 莺儿, 年纪, 父亲]#未剔除旧词
[薛姨妈, 贾珍, 刘姥姥, 麝月, 贾蓉, 周瑞, 贾赦, 雨村, 贾芸, 芳官, 贾环, 林姑娘, 赵姨娘, 莺儿, 宝蟾, 两银子, 溃骸, 秦钟, 薛蝌, 几句, 岫烟, 赖大, 听了这话, 茗烟, 递与, 钏儿, 士隐, 荣府, 贾蔷, 冯紫英, 焙茗, 请了安, 宁府, 包勇, 金钏, 鲍二, 代儒, 嗳哟, 从小儿, 在床上, 既这么, 十六, 让坐, 李贵, 打谅, 既这样, 金钏儿, 日一早, 李嬷嬷, 族中, 唬了一跳, 蘅芜, 还了得, 王仁, 在炕上, 间屋, 藕官, 几句话, 尤三姐, 五百, 也未可知, 警幻, 越性, 手帕子, 十两银子, 李婶, 忽然想起, 小蹄子, 熙凤, 六十, 十九, 琏二奶奶, 珍大爷, 往那里去, 要知端, 些闲话, 孙女儿, 蒋玉菡, 榻上, Φ溃骸, 罢咧, 八九, 乱嚷, 几个钱, 点点头儿, 自己房中, 李十儿, 犹未, 既如此, 忙陪笑, 千万, 十七, 沁芳, 在外间, 几两银子, 王子腾, 马道婆, 铁槛寺, 李纹, 若论]#剔除旧词
关键词提取
关键词提取就是提取文章中重要的单词,常见的方法有词频、TF-IDF,TextRank算法
单文档提起可以用词频和TextRank,多文档可以使用TF-IDF来提取关键词。
词频统计
通过统计文章中每种词语的词频并排序,可以初步获取部分关键词。
不过文章中反复出现的词语却不一定是关键词,例如“的”。所以在统计词频之前需要去掉停用词。
流程:分词、停用词过滤、按词频顺序取前 n 个。其中,求 m 个元素中前 n (n<=m) 大元素的问题通常通过最大堆解决,复杂度为 O(mlogn)。同时HanLP提供了相关的接口。
实现
from pyhanlp import *
TermFrequency = JClass('com.hankcs.hanlp.corpus.occurrence.TermFrequency')
TermFrequencyCounter = JClass('com.hankcs.hanlp.mining.word.TermFrequencyCounter')
from pyhanlp import *
TermFrequency = JClass('com.hankcs.hanlp.corpus.occurrence.TermFrequency')
TermFrequencyCounter = JClass('com.hankcs.hanlp.mining.word.TermFrequencyCounter')
if __name__ == '__main__':
counter = TermFrequencyCounter()
counter.add("加油加油中国队!") # 第一个文档
counter.add("中国观众高呼加油中国") # 第二个文档
for termFrequency in counter: # 输出每个词与词频
print("%s=%d" % (termFrequency.getTerm(), termFrequency.getFrequency()))
print(counter.top(2)) # 取前两个
print(TermFrequencyCounter.getKeywordList("加油加油中国队!中国观众高呼加油中国", 3))
输出
中国=2
中国队=1
加油=3
观众=1
高呼=1
[加油=3, 中国=2]
[加油, 中国, 高呼]
TF-IDF
所谓TF-IDF就是,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF具体可以看这篇文章:TF-IDF与余弦相似性的应用
实现
from sklearn.feature_extraction.text import TfidfVectorizer
documents=['This is the second document.',
'And the third one.',
'Is this the first document?']#语料库
tf_idf=TfidfVectorizer()
tf_idfMatrix=tf_idf.fit_transform(documents)
tf_idfarray=tf_idfMatrix.toarray()
# 得到语料库所有不重复的词
print(tf_idf.get_feature_names_out())
# 得到每个单词对应的id值
print(tf_idf.vocabulary_)
# 得到每个句子所对应的向量,向量里数字的顺序是按照词语的id顺序来的
print(tf_idfarray)
输出
['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
{'this': 8, 'is': 3, 'the': 6, 'second': 5, 'document': 1, 'and': 0, 'third': 7, 'one': 4, 'first': 2}
[[0. 0.43306685 0. 0.43306685 0. 0.56943086
0.33631504 0. 0.43306685]
[0.54645401 0. 0. 0. 0.54645401 0.
0.32274454 0.54645401 0. ]
[0. 0.43306685 0.56943086 0.43306685 0. 0.
0.33631504 0. 0.43306685]]
TextRank
TextRank 是 PageRank 在文本中的应用,
PageRank这个算法是基于图的,每个网页可以看作是一个图中的结点,用户可以通过A网页中的链接,跳转到B网页,这种互相跳转关系,可以理解为一种“投票”行为,A网页连接到B网页,表示A网页对B网页的认可,即A网页给B网页投了一票。给B网页投票(链接)的越多,B网页的价值也就越大这样,我们就可以构造出一个有向图了。然后,利用公式:
其中d是一个0~1的常数因子,一般取值为0.85,In(V)表示连接到V的节点集合,Out(V)表示从V连接到的节点的集合。一个网站,如果越多的网站链接到它,说明这个网站越有价值,为什么要加入一个权重呢?公式可以看到,权重是从某个网页链接出去的数量的倒数,数量越多,权重越小,好比是投票,某个人投出的票越多,说明这个人的票越没有含金量。
TextRank就是在PageRank的基础上,将单词视为节点。每个单词的外链来自于自身前后固定大小的窗口内的所有单词。

图中,假设窗口半径为2,词语”处理“的外链来自于”自然“、”语言“、”入门“、”非常“4个单词。
根据窗口进行滑动,最终得到一个有向无权图
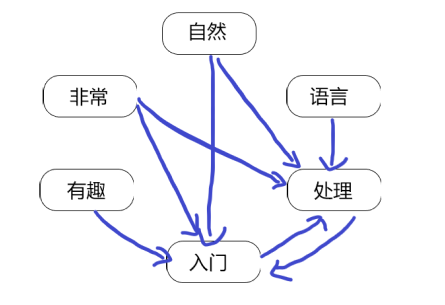
同时也可以建立无向无权图,textRank原论文中对于关键词提取任务主要是构建的无向无权图,对于有向图,论文提到是基于词的前后顺序角度去考虑,即给定窗口。其实来说有向图效果比无向图差一些。
然后用公式进行递归计算,直到最后结果收敛
实现
from pyhanlp import *
content = (
"程序员(英文Programmer)是从事程序开发、维护的专业人员。"
"一般将程序员分为程序设计人员和程序编码人员,"
"但两者的界限并不非常清楚,特别是在中国。"
"软件从业人员分为初级程序员、高级程序员、系统"
"分析员和项目经理四大类。")
TextRankKeyword = JClass("com.hankcs.hanlp.summary.TextRankKeyword")
keyword_list = HanLP.extractKeyword(content, 5)
print(keyword_list)
输出
[程序员, 程序, 分为, 人员, 软件]
短语提取
短语提取,也即固定多字词表达串的识别。短语提取经常用于搜索引擎的自动推荐,文档的简介生成等。
利用互信息和左右信息熵,我们可以轻松地将新词提取算法拓展到短语提取。只需将新词提取时的字符替换为单词, 字符串替换为单词列表即可。为了得到单词,我们依然需要进行中文分词并将停用词进行过滤。
实现
from pyhanlp import *
text = '''新华社北京8月13日电 题:一个中国原则是国际社会的普遍共识——多国人士高度评价《台湾问题与新时代中国统一事业》白皮书
新华社记者
国务院台湾事务办公室、国务院新闻办公室10日发表《台湾问题与新时代中国统一事业》白皮书。多国人士表示,台湾是中国的一部分,一个中国原则是国际社会的普遍共识,这份白皮书展现了中方追求国家统一的坚定意志和坚强决心。
厄瓜多尔外交部前副部长拉斐尔·金特罗表示,中方发表《台湾问题与新时代中国统一事业》白皮书,表明了中国推进国家统一进程的坚定决心。他指出:“了解台湾问题要从真正的历史着手,台湾自古就是中国的一部分,国际关系基本准则应得到遵守。”
韩中城市友好协会会长权起植认为,白皮书明确表达了中方推进实现国家统一的立场和政策。“今天的中国国力不断壮大,国际影响力不断上升,有信心也有能力解决台湾问题,‘以台制华’的图谋注定破产”。
马来西亚新亚洲战略研究中心主席翁诗杰说,美国的焦虑感日益增加,台湾问题长期以来被美方用作遏制中国的地缘政治工具。他指出,白皮书的发表及时而必要,台湾问题是中国的内政,应该由中国人自己解决。
坦桑尼亚执政党革命党主管国际关系的副书记卢宾加代表该党发表声明说,革命党一贯支持一个中国原则,在台湾问题上支持中国反对外部势力挑衅。台湾是中国的一部分,坚决反对任何分裂中国的图谋。
克罗地亚前总统约西波维奇指出,台湾是中国的一部分,支持中国维护国家主权和领土完整,克罗地亚始终坚定奉行一个中国政策。
非洲对华友好协会联合会会长阿萨内·姆本格从白皮书中读出中国争取和平统一的诚意和维护国家主权和领土完整的决心。姆本格表示,非洲对华友好协会联合会坚定支持一个中国原则,强调违背这一原则的行为是危险的。
拉脱维亚《今日报》主编安德烈·什维多夫告诉记者,白皮书发布非常及时,有理有据地表明了中国的一贯立场。联大第2758号决议和大量国际文件充分证明,一个中国原则法理事实清楚,不容曲解。
居住在科威特的黎巴嫩作家和媒体人士哈姆扎·奥拉扬认为,白皮书系统阐述表明台湾过去、现在和将来都是中国的一部分,中方反对分裂行径合理合法。
印度尼西亚国际战略研究中心研究员韦罗妮卡·莎拉斯瓦蒂指出,台湾是中国的一部分,世界各国都应尊重和支持中国维护主权和领土完整的努力,台湾问题不能成为外国势力干涉中国内政的理由或工具。
“一些外部势力试图改变台海现状,支持‘台独’分裂分子,企图破坏地区的和平、安宁和经济发展。”柬埔寨贝尔泰国际大学资深教授约瑟夫·马修斯指出,台湾是中国的一部分,“以台制华”图谋注定失败。'''
phrase_list = HanLP.extractPhrase(text, 5)
print(phrase_list)
输出
[台湾问题, 支持中国, 国家统一, 反对分裂, 中国原则]
自动摘要
由于一篇文章中几乎不可能出现相同的两个句子,所以朴素的 PageRank 在句子颗粒度上行不通。为了将 PageRank 利用到句子颗粒度上去,我们引人 BM25 算法衡量句子的相似度,改进链接的权重计算。相似的句子将得到更高的投票。
BM25
BM25 是TF-IDF的一种改进变种。解决了如何衡量多个词语与文档的关联程度的问题
形式化的定义 Q 为查询语句,由关键字 q1 到 qn 组成,D 为一个被检索的文档,BM25度量如下:
其中IDF和TF与TF-IDF定义相同,k和b是两个常数,avgDL是所有文档的平均长度。
BM25大意是对查询语句Q中所有单词的IDF进行加权求和。k越大则TF对文档得分正面影响越大,b越大则TF对文档得分负面影响越大。
TextRank
有了BM25算法之后,将一个句子视作查询语句,相邻的句子视作待查询的文档,就能得到它们之间的相似度。以此相似度作为 PageRank 中的链接的权重,于是得到一种改进算法,称为TextRank。此时构造的是有权图(有向,无向都可以)。它的形式化计算方法如下:
其中,WS(Vi) 就是文档中第 i 个句子的得分,重复迭代该表达式若干次之后得到最终的分值,排序后输出前 N 个即得到关键句。代码如下:
from pyhanlp import *
text = '''新华社北京8月13日电 题:一个中国原则是国际社会的普遍共识——多国人士高度评价《台湾问题与新时代中国统一事业》白皮书
新华社记者
国务院台湾事务办公室、国务院新闻办公室10日发表《台湾问题与新时代中国统一事业》白皮书。多国人士表示,台湾是中国的一部分,一个中国原则是国际社会的普遍共识,这份白皮书展现了中方追求国家统一的坚定意志和坚强决心。
厄瓜多尔外交部前副部长拉斐尔·金特罗表示,中方发表《台湾问题与新时代中国统一事业》白皮书,表明了中国推进国家统一进程的坚定决心。他指出:“了解台湾问题要从真正的历史着手,台湾自古就是中国的一部分,国际关系基本准则应得到遵守。”
韩中城市友好协会会长权起植认为,白皮书明确表达了中方推进实现国家统一的立场和政策。“今天的中国国力不断壮大,国际影响力不断上升,有信心也有能力解决台湾问题,‘以台制华’的图谋注定破产”。
马来西亚新亚洲战略研究中心主席翁诗杰说,美国的焦虑感日益增加,台湾问题长期以来被美方用作遏制中国的地缘政治工具。他指出,白皮书的发表及时而必要,台湾问题是中国的内政,应该由中国人自己解决。
坦桑尼亚执政党革命党主管国际关系的副书记卢宾加代表该党发表声明说,革命党一贯支持一个中国原则,在台湾问题上支持中国反对外部势力挑衅。台湾是中国的一部分,坚决反对任何分裂中国的图谋。
克罗地亚前总统约西波维奇指出,台湾是中国的一部分,支持中国维护国家主权和领土完整,克罗地亚始终坚定奉行一个中国政策。
非洲对华友好协会联合会会长阿萨内·姆本格从白皮书中读出中国争取和平统一的诚意和维护国家主权和领土完整的决心。姆本格表示,非洲对华友好协会联合会坚定支持一个中国原则,强调违背这一原则的行为是危险的。
拉脱维亚《今日报》主编安德烈·什维多夫告诉记者,白皮书发布非常及时,有理有据地表明了中国的一贯立场。联大第2758号决议和大量国际文件充分证明,一个中国原则法理事实清楚,不容曲解。
居住在科威特的黎巴嫩作家和媒体人士哈姆扎·奥拉扬认为,白皮书系统阐述表明台湾过去、现在和将来都是中国的一部分,中方反对分裂行径合理合法。
印度尼西亚国际战略研究中心研究员韦罗妮卡·莎拉斯瓦蒂指出,台湾是中国的一部分,世界各国都应尊重和支持中国维护主权和领土完整的努力,台湾问题不能成为外国势力干涉中国内政的理由或工具。
“一些外部势力试图改变台海现状,支持‘台独’分裂分子,企图破坏地区的和平、安宁和经济发展。”柬埔寨贝尔泰国际大学资深教授约瑟夫·马修斯指出,台湾是中国的一部分,“以台制华”图谋注定失败。'''
phrase_list = HanLP.extractSummary(text, 2) #输出前两个句子
print(phrase_list)
输出
[一个中国原则是国际社会的普遍共识——多国人士高度评价《台湾问题与新时代中国统一事业》白皮书, 中方发表《台湾问题与新时代中国统一事业》白皮书]
总结
同时我们也看到,新词提取与短语提取,关键词与关键句的提取,在原理上都是同一种算法在不同文本颗粒度上的应用。值得一提的是,这些算法都不需要标注语料的参与,然而必须指出的是,对于同一个任务,监督学习方法的效果通常远远领先于无监督学习方法。