Word2Vec

Word2Vec
Word2Vec是常用的词嵌入模型之一。Word2Vec实际是一种浅层的神经网络模型,它有两种网络结构,分别是CBOW(Continues Bag of Words)连续词袋和Skip-gram。 我们可以选择其中一个方法来获得文本的词向量结果。
《word2vec Parameter Learning Explained》:https://arxiv.org/pdf/1411.2738.pdf
Skip-gram
Skip-gram是通过当前词来预测窗口中上下文词出现的概率模型。如果滑动窗口为n,那么就是将中心词的前n个词和后n个词作为样本带入进行训练,每次迭代训练2*n个样本。(通常是该词前k/2个词,该词后k/2个词,但从推导来看由于权重不同,对于窗口和词位置的关系并没有太大关系,前后词数不一定要对称)
例如:
句子:我 下午 准备 去 打 篮球
设置滑动窗口为2,那么滑动窗口为:
第一次输入:准备 ->来预测"我 下午 去 打",
第二次输入: 去 ->来预测"下午 准备 打 篮球"
每次训练4个样本
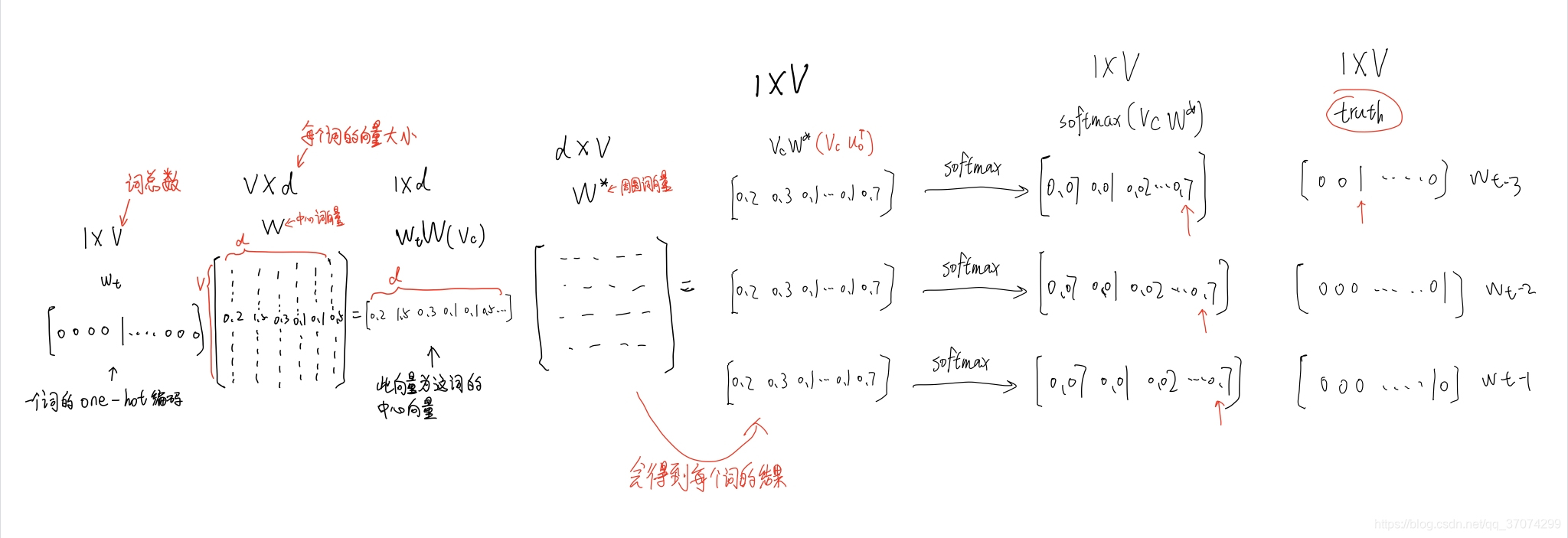
原理如下:

其中:V为词的数量;D为设定的词向量的维度;W为词的中心词矩阵;w*为词的周围词矩阵。
softmax
其中为通过c预测词为的概率,分别为窗口内上下文词向量和中心词向量
损失函数
总体流程如下:
- 随机生成中心词矩阵w和周围词矩阵w*
- 对词wi生成ont hot向量,将向量与中心词矩阵W相乘,获得中心词向量
- 将中心词向量与周围词矩阵w相乘,作为周围词向量*
- 将周围词向量经过softmax作为输出向量也就是所预测的每个词的概率
- 接下来就是反向传播来调整W和W’这两个矩阵数据进行优化,使得目标词的概率最大,损失函数最小
- 最后将中心词矩阵W作为词的最终词向量
CBOW
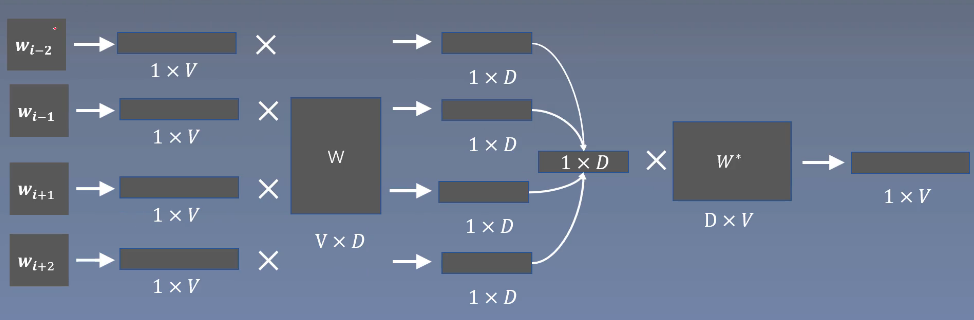
CBOW原理与Skip-gram相反,是通过设置滑动窗口获得中间词两边的的上下文,然后用周围的词去预测中间的词。
softmax
其中为通过中性词向量o预测词为的概率,为中心词向量,为窗口内上下文向量
损失函数
- 随机生成中心词矩阵w*和窗口上下文词矩阵w中的参数
- 当前词的上下文词语的one-hot编码输入到输入层。
- 这些上下文词分别乘以同一个窗口上下文词矩阵W后分别得到各自的1*D向量。
- 将这些1*D向量相加取平均作为窗口上下文向量。
- 将这个1*D向量乘 中心词矩阵w*,作为中心词向量。
- 将中心词向量softmax归一化后输出取每个词的概率向量1*V。
- 接下来就是反向传播来调整中心矩阵W和上下文词矩阵w*这两个矩阵数据进行优化,使得目标词的概率最大,损失函数最小
- 最后将中心词矩阵W作为词的最终词向量
Word2Vec优化策略
论文提供了对Skip-gram模型两种优化的策略,分别是分层softmax和负样本
同时也可以运用在CBOW模型中
也告诉了我们在训练词向量的时候的关键超参数:choice of the model architecture, the size of the vectors, the subsampling rate and the size of the training window.(模型的选择,向量的维度,子采样率和滑动窗口的大小)
层次Softmax
层次softmax将softmax变为多个sigmod函数,进行多分类而减少softmax的计算,提升的效率。

层次softmax首先利用树结构的叶节点表示词库中的每一个词,从根节点到叶节点的路径,每一个中间路径都对应着一个概率,某个词出现的概率的计算方式改为路径上所有中间路径概率的乘积。
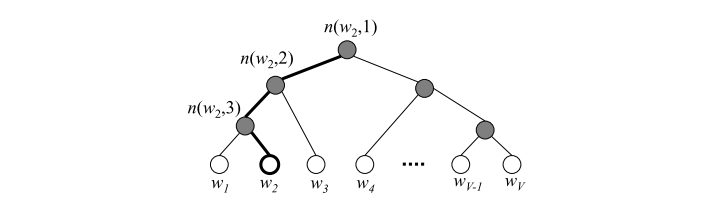
每一个中间路节点(上图中实心球)对应一个D*1的向量,然后上面得到的1*D的向量与中间路径向量相乘,得到一个数值z,z输入到sigmod函数得到一个0-1的数值,就是该节点到下一节点向左的概率,另外一侧概率是1-sigmod(z),这样就得到了中间路径的概率。最后某个词的概率就是从根节点到叶子节点中间路径概率的乘积。
同时层次softmax的目标函数也做出了改变为了最大化目标词的路径概率,就是只关注目标词所在路径的概率,其他路径不再关注,也无需计算。
具体
通过词出现在语料库中的频率进行排序,构建出哈夫曼树,频率越高则离根节点越近
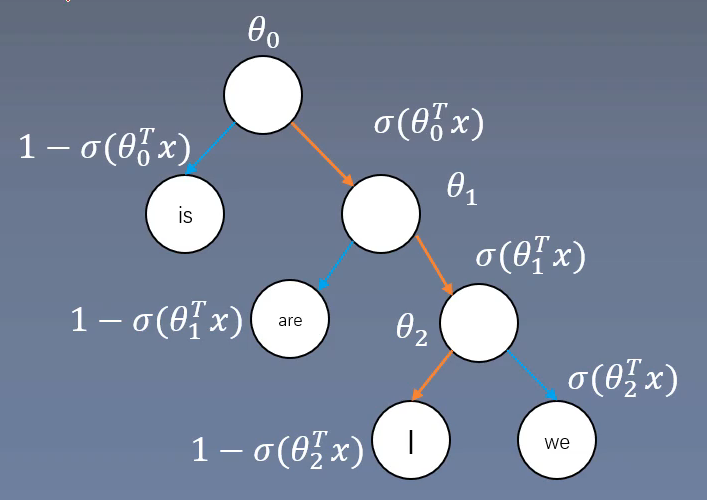
输入词c而输出为i的概率为:
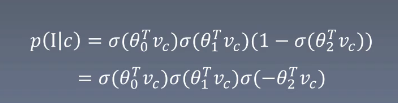
层次Softmax构建公式
表示词w在树的第j个节点,L(w)表示树的高度表示中心词向量表示词w在树的第j个节点的向量
损失函数
负采样
负采样是将层次softmax进一步优化,从多分类变为了二分类
负采样每次训练样本仅仅更新一小部分的权重,这样就会极大梯度下降过程中的计算量。
举个例子

训练样本 ( input word: "fox",output word: "quick")
训练我们的神经网络时,“ fox”和“quick”都是经过one-hot编码的。如果我们的语料库有10000个词,在输出层,我们期望对应“quick”单词的输出概率为1,其余9999个都应该输出0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称为 "negative"word 。
再选择一小部分的negative words和目标词来更新对应的权重。
在论文中,作者指出:
对于小规模数据集,选择5-20个negative words会比较好,
对于大规模数据集可以仅选择2-5个negative words

如果隐层-输出层拥有300 x 10000的权重矩阵。如果使用了负采样的方法我们仅仅去更新我们的positive word-“quick”的和我们选择的其他5个negative words的结点对应的权重,共计6个输出神经元,相当于每次只更新300×6=1800个权重。对于3百万的权重来说,相当于只计算了0.06% 的权重,这样计算效率就大幅度提高。
具体
负样本抽取公式为:
就是对词w的出现频率进行3/4次方再进行归一化操作
举个例子:
假设
一个单词的出现频次低,则增加其作为负采样的概率,使单词越容易作为负样本。
一个单词的出现频率高,则减少其作为负采样的概率,使单词不容易作为负样本
因为一些重要的词出现的频率较少,但信息量很大;而不重要的词出现的频率高,信息量却少
损失函数
其中是中心词向量,是周围词向量,是负采样周围词向量
实现方式
gensim库
Gensim是在做自然语言处理时较为经常用到的一个工具库 它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法。
对于word2vec模型,模型的输入是分完词的语料库,形式类似于list
class gensim.models.word2vec.Word2Vec(sentences=None, corpus_file=None, vector_size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=<built-in function hash>, epochs=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False, callbacks=(), max_final_vocab=None)
-
sentences: 训练语料库,也可以通过LineSentence(分词后语料库)来读取。
-
vector_size: 生成词向量的维度,默认值是100。
-
window: 滑动窗口的大小。
-
sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型;是1则是Skip-Gram模型;默认是CBOW模型。
-
hs: 即我们的word2vec两个优化策略的选择。如果是0, 则是层次Softmax;是1的话并且负采样个数negative大于0, 则是负采样。默认是负采样。
-
negative: 即选取负采样词的个数,默认是5。
-
alpha: 在随机梯度下降法中迭代的初始步长。默认是0.025。
实例
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
def A():
#首先打开需要进行训练的提前进行分词后的语料库
shuju = open('./gushi.txt', 'rb')
#通过Word2vec进行训练
model = Word2Vec(LineSentence(shuju), vector_size=60, window=5,sg=1, hs=1,negative=5,alpha=0.025)
#保存训练好的模型
model.save('./SanGuoYanYiTest.word2vec')
print('训练完成')
if __name__ == '__main__':
A()
model=Word2Vec.load('./SanGuoYanYiTest.word2vec')
print(model.wv['张飞'])
E:\python310\python.exe E:\word2vec\run.py
[ 0.40019155 0.15926215 -0.17247036 0.41934988 0.08891562 -0.3912016
0.36244896 -0.13611287 -0.04305122 -0.05948525 0.6624021 0.19892757
-0.26073712 0.18728831 -0.07860013 -1.0155997 0.30067584 0.19669221
-0.29462233 -0.4473715 0.01844584 0.22937016 0.30038676 0.37411225
0.56089747 -0.03240279 -0.06159927 0.07859133 0.30643627 0.18028829
-0.19900236 -0.05217438 0.03655851 -0.7016526 0.11351124 -0.28412226
-0.27930066 -0.51100993 0.10102482 0.00141967 0.04916065 -0.46889248
-0.46942952 -0.15252821 0.13466035 -0.32120392 0.06884138 0.47682145
0.22563507 0.4833642 -0.44313872 -0.05569039 -0.10548913 0.34712958
0.30353147 0.14394882 0.07643879 0.3689174 0.4029759 -0.04832706]
进程已结束,退出代码0