微博榜单爬虫

本文主要是介绍关于微博榜单的博文以及转发、评论等各种信息爬取。
榜单博文爬取方面,使用的是微博移动端(https://m.weibo.cn)。
因为对于该页面中微博移动版中热门内容、榜单的爬取,不需要使用到cookies。
榜单和微博热门的爬取中,具体的内容细节抓取基本差不多,本文以爬取汽车榜单为例进行解析。
微博—汽车榜单博文爬取
首先进入微博移动端(https://m.weibo.cn),打开开发者模式在网络中找到如下包

对应请求网址如下:
https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_5188_-_ctg1_5188
这个请求网址里面代表的是汽车榜单中的相关内容,由于里面内容是随即滚动的,并且带一定的推荐功能,会随登陆账号的不同显示不一样,每次刷新也都会有不同的数据出现。
进去后可以看到,移动端是用滑动的模式,而不是翻页的模式,那么怎么获取下一页的内容呢?
该页面是可以直接用页数&page加一的操作来更新的,但是在后面的用户评论的爬取却不是这个规则,当然这是后话了。
爬取过程详解
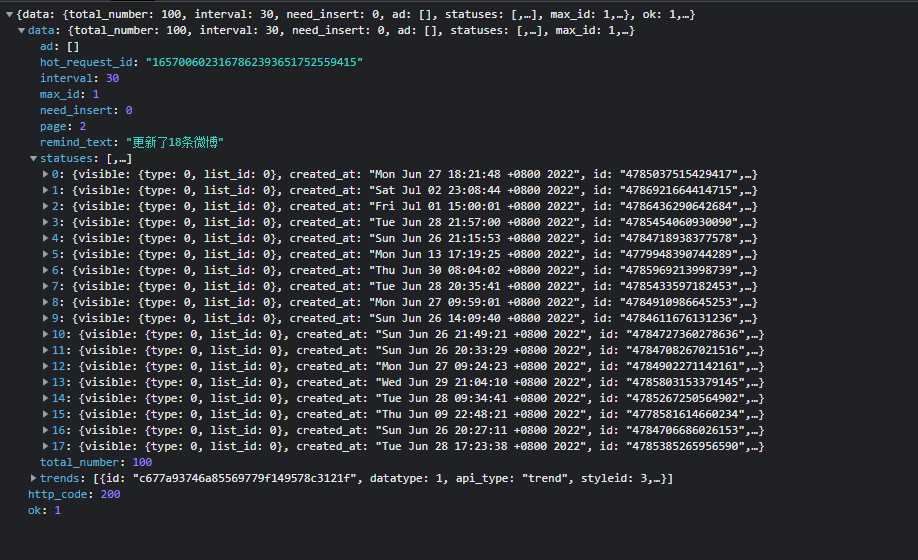
首先依据将前面找到的数据接口爬下数据,看看数据格式。
在预览中可以看到包中的数据内容,直接使用requests就可以拿到页面数据,再提取对应的值,再将数据以Json格式存储就可以了。
def crawler(url,page,name):
num=1
c=1
allData=[]
for i in range(page):
res=requests.get("{}&page={}".format(url,i))
data=res.json()['data']['statuses']
包中的具体数据解析
博文等相关数据存储在data->statuses中,里面0~17代表了,该页有18条微博,我们再点进去观察数据表示的含义
ab_switcher: 4
attitudes_count: 89
bid: "LAteeiwt5"
bmiddle_pic: "http://wx3.sinaimg.cn/bmiddle/7fd514fdly1h3szgp0feaj235s2dchdv.jpg"
buttons: [{type: "follow", name: "关注",…}]
can_edit: false
comment_manage_info: {comment_permission_type: -1, approval_comment_type: 0, comment_sort_type: 0}
comments_count: 16
content_auth: 0
created_at: "Sat Jul 02 23:08:44 +0800 2022"
darwin_tags: []
extern_safe: 0
falls_pic_focus_point: []
favorited: false
from_cateid: "5188"
hot_ext: "source_type:5188|recommend_source:87|isPageUp:1|position:2"
hot_page: {fid: "232532_mblog", feed_detail_type: 0}
id: "4786921664414715"
isLongText: false
is_paid: false
mblog_buttons: [{type: "mblog_buttons_forward", name: "转发", pic: "",…},…]
mblog_vip_type: 0
mblogtype: 0
mid: "4786921664414715"
mlevel: 0
negative_tags: [{tag: "1042015:carBrand_c3f70203da24f043de5d59bf97bfc12d", type: "3", name: "大众",…},…]
new_comment_style: 0
number_display_strategy: {apply_scenario_flag: 3, display_text_min_number: 1000000, display_text: "100万+"}
original_pic: "https://wx3.sinaimg.cn/large/7fd514fdly1h3szgp0feaj235s2dchdv.jpg"
pending_approval_count: 0
picStatus: "0:1"
pic_flag: 1
pic_focus_point: [{focus_point: {left: 0.3942028880119324, top: 0.3861003816127777, width: 0.28985506296157837,…},…}]
pic_ids: ["7fd514fdly1h3szgp0feaj235s2dchdv"]
pic_num: 1
pic_rectangle_object: []
pics: [{pid: "7fd514fdly1h3szgp0feaj235s2dchdv",…}]
recommend_source: 87
region_name: "发布于 北京"
region_opt: 1
reposts_count: 0
reprint_cmt_count: 0
reward_scheme: "sinaweibo://reward?bid=1000293251&enter_id=1000293251&enter_type=1&oid=4786921664414715&seller=2144670973&share=18cb5613ebf3d8aadd9975c1036ab1f47&sign=95f1971a1f966218fee334dd90f4fb43"
rid: "1_0_0_6666695739198377824_0_0_0"
show_additional_indication: 0
source: "OPPO Find X5 Pro"
text: "帅就完了,终于低下来了! "
textLength: 24
thumbnail_pic: "https://wx3.sinaimg.cn/thumbnail/7fd514fdly1h3szgp0feaj235s2dchdv.jpg"
title: {text: ""}
user: {id: 2144670973, screen_name: "说车的小宇",…}
visible: {type: 0, list_id: 0}
包含了十分完整且丰富的数据,在本文中所需的数据主要有:
id=singleMess['user']['id'] //用户id
messageid=singleMess['id'] //博文id
mid=singleMess['mid'] //微博在web系统中的id值
username=singleMess['user']['screen_name'] //博主用户名
messagetime=singleMess['created_at'] //发博时间
messagetime=getStandard(messagetime)
message=singleMess['text'] //博文内容
like=singleMess['attitudes_count'] //点赞数
transmit=singleMess['reposts_count'] //转发数
commentNum=singleMess['comments_count'] //评论数
至此,榜单的博文等信息便可以抓取完毕,接下来是博文中的评论和转发信息。
微博—博文评论抓取
我们在汽车榜单中,随便点进去一个微博
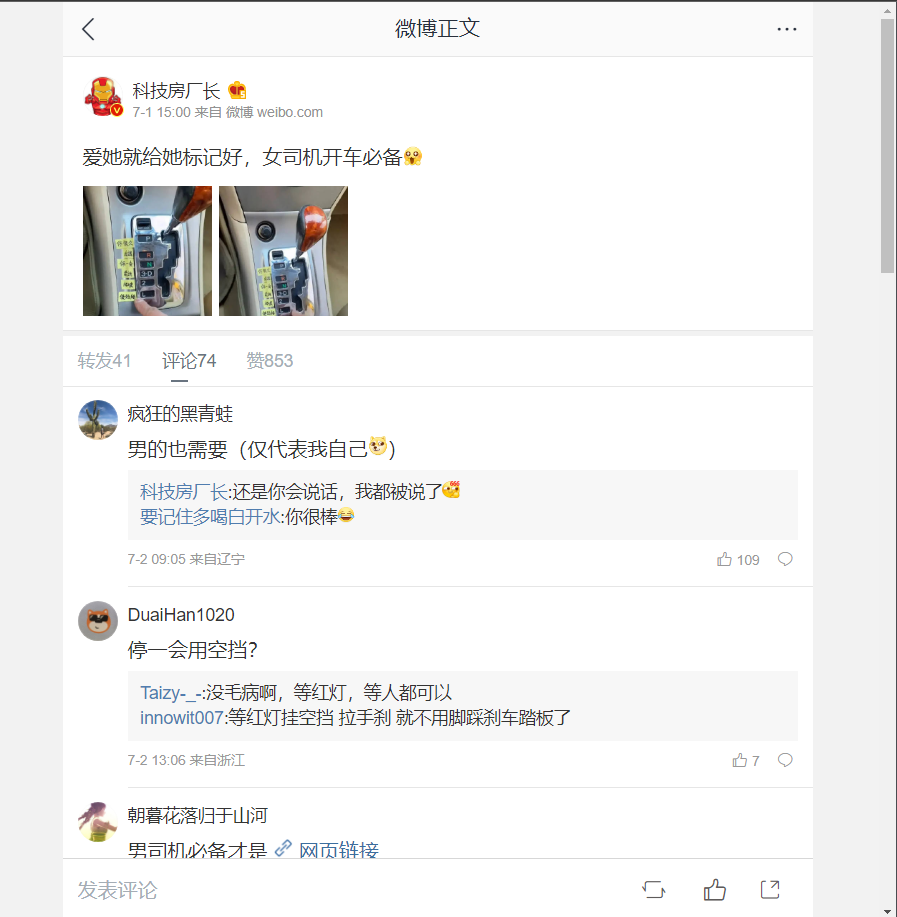
在开发者模式中找到如下请求包

请求网址为:
https://m.weibo.cn/comments/hotflow?id=4786436290642684&mid=4786436290642684&max_id_type=0
通过对请求网址的分析,id和mid对应为上节中爬取的相关数据,因此便可以通过将榜单中的博文的id和mid提取出来,然后修改该请求头的id和mid为提取的数值就可以实现对评论的爬取了。
那么如何进行翻页的操作呢?
我们观察这两个请求网址有什么不一样
https://m.weibo.cn/comments/hotflow?id=4786436290642684&mid=4786436290642684&max_id_type=0//第一页
https://m.weibo.cn/comments/hotflow?id=4786436290642684&mid=4786436290642684&max_id=138173583930408&max_id_type=0 //第二页
发现多了一个&max_id的数据,那么这个数据是如何获取的呢?
我们再次回到第一页的网络包中,在预览中查看包中的数据
{ok: 1, data: {data: [,…], total_number: 74,…}}
data: {data: [,…], total_number: 74,…}
data: [,…]
max: 4
max_id: 138173583930408
max_id_type: 0
status: {comment_manage_info: {comment_permission_type: -1, approval_comment_type: 0, comment_sort_type: 0}}
total_number: 74
ok: 1
里面的max_id的数据是不是就出来了呢?
总结:评论的翻页是通过对该页面的包中max_id 而对应到下一页的
爬取过程详解
通过构造请求头,进行数据网址的请求,然后进行数据的解析就可以了,然后通过本页的max_id 的值来进行翻页操作。
爬取代码如下:
def getSingleMicroblogInfo(id,mid):
headers = {
"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Mobile Safari/537.36",
"cookie":'input your cookie'
}
microblog=[]
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0'.format(id,mid)
num=1
while num<=200:
res = requests.get(url,headers=headers)
data = res.json()['data']
max_id = data['max_id']
user_info = data['data']
for single_info in user_info:
Retext=single_info['text']
Retext_id=single_info['id']
user_id=single_info['user']['id']
user_name=single_info['user']['screen_name']
user_messagetime = single_info['created_at']
user_messagetime=getStandard(user_messagetime)
comment_flag = 1
user_comment=[user_messagetime,user_id,user_name,Retext_id,Retext,comment_flag]
microblog.append(user_comment)
num+=1
time.sleep(1)
if max_id!=0:
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id={}&max_id_type=0'.format(id, mid, max_id)
else:
break
return microblog
微博—转发信息抓取
点进转发界面
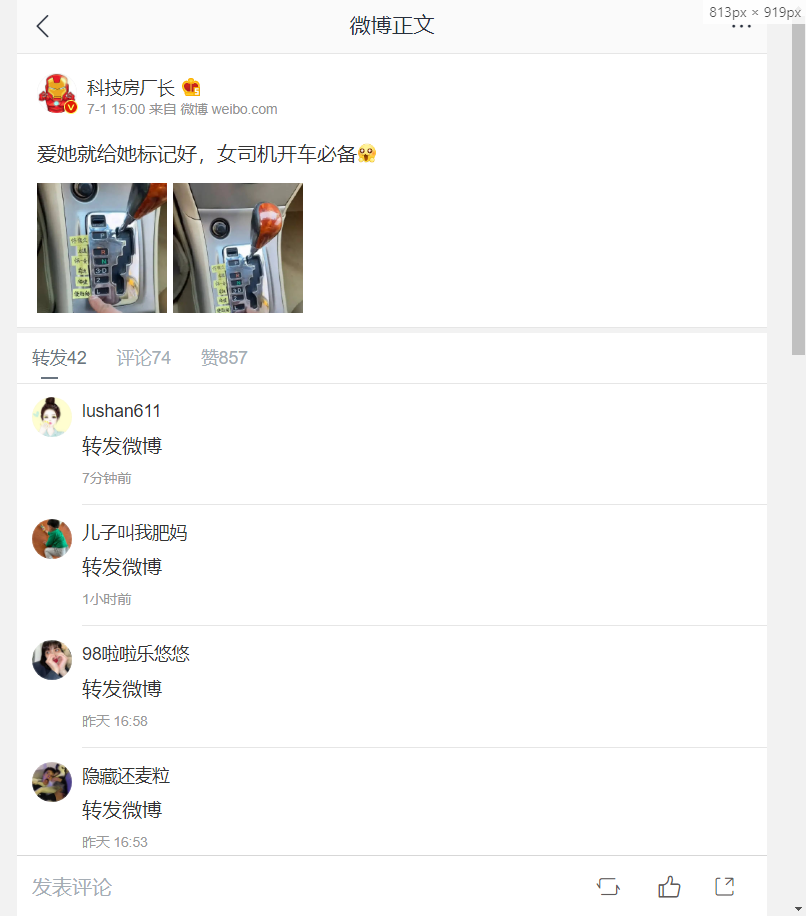
同样如上节,到如下请求包
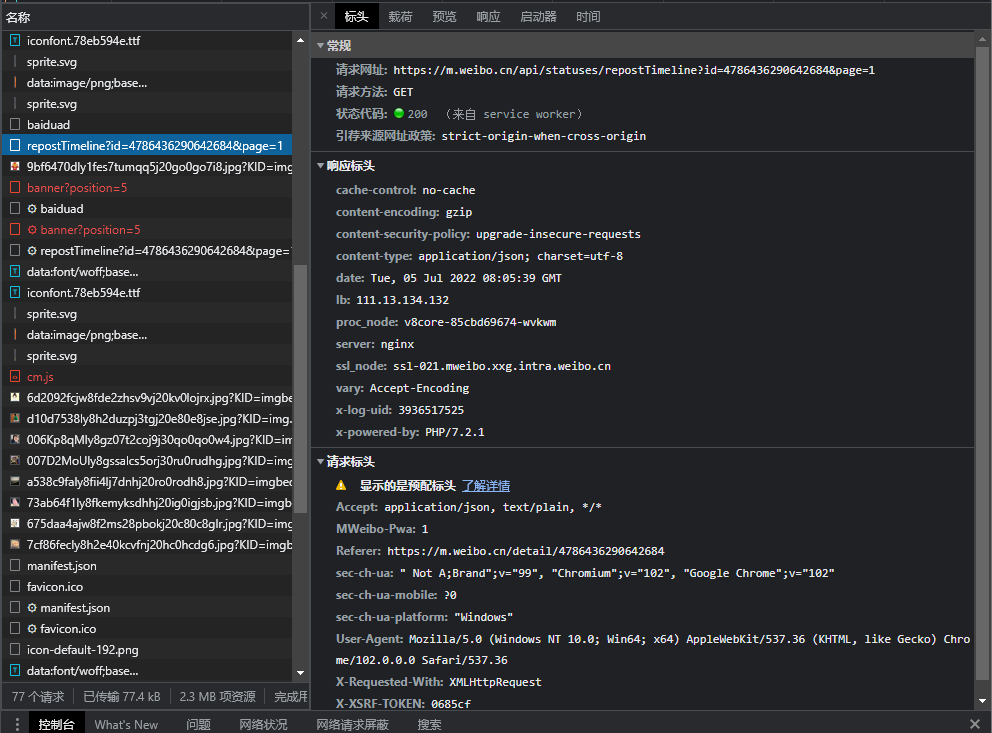
转发的翻页和博文爬取一样通过&page操作来进行
具体数据的提取操作和评论的爬取相同,传入博文的id,也就不累赘了,直接上代码:
def getTranspondInfo(id):
headers = {
"user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Mobile Safari/537.36",
"cookie": 'input your cookie'
}
url = 'https://m.weibo.cn/api/statuses/repostTimeline?id={}&page=1'.format(id)
res = requests.get(url, headers=headers)
data = res.json()['data']
page = data['max']
current_page = 1
num = 1
total_number = data['total_number']
microblog = []
transpondInfo = data['data']
while num <= 100 and num<total_number:
if current_page!=1:
res = requests.get(url, headers=headers)
data = res.json()['data']
total_number = data['total_number']
transpondInfo = data['data']
else:
pass
for single_info in transpondInfo:
Retext = single_info['text']
Retext_id = single_info['id']
user_id = single_info['user']['id']
user_name = single_info['user']['screen_name']
user_messagetime = single_info['created_at']
user_messagetime = getStandard(user_messagetime)
transpond_flag=2
user_comment = [user_messagetime, user_id, user_name, Retext_id, Retext, transpond_flag]
microblog.append(user_comment)
num += 1
time.sleep(1)
if current_page <= page:
current_page += 1
url = 'https://m.weibo.cn/api/statuses/repostTimeline?id= {}&page={}'.format(id, current_page)
else:
break
return microblog
数据清洗
爬取中的数据发现存在大量的网址标签等信息,我们需要进行数据的清洗,去除这些不需要的数据
def cleanData(df):
发文=[]
评论=[]
for item,item2 in zip(df['发文/转发内容'],df['转发/评论内容']):
scriptRegex = "<script[^>]*?>[\\s\\S]*?<\\/script>";
styleRegex = "<style[^>]*?>[\\s\\S]*?<\\/style>";
htmlRegex = "<[^>]+>";
spaceRegex = "\\s*|\t|\r|\n";
item=re.sub(scriptRegex,'', str(item)) # 去除网址
item=re.sub(styleRegex,'', str(item))
item=re.sub(htmlRegex,'', str(item))
item=re.sub(spaceRegex,'', str(item))
item=re.sub('网页链接','', str(item))
item2 = re.sub(scriptRegex, '', str(item2))
item2= re.sub(styleRegex, '', str(item2))
item2 = re.sub(htmlRegex, '', str(item2))
item2 = re.sub(spaceRegex, '', str(item2))
item2 = re.sub('网页链接', '', str(item2))
发文.append(item)
评论.append(item2)
df['发文/转发内容']=发文
df['转发/评论内容']=评论
至此,爬取工作也就结束了。
爬取数据展示
常用的榜单请求地址
urls = [
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_8999_-_ctg1_8999_home', ## 榜单
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_2088_-_ctg1_2088', ## 科技
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_4288_-_ctg1_4288', ## 明星
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_3288_-_ctg1_3288', ## 电影
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_5288_-_ctg1_5288', ## 音乐
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_1988_-_ctg1_1988', ## 情感
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_4488_-_ctg1_4488', ## 时尚
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_1588_-_ctg1_1588', ## 美妆
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_4888_-_ctg1_4888', ## 游戏
'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_5188_-_ctg1_5188', ## 数码
]