Scaling Transformer to 1M tokens and beyond with RMT

当我还在用最大一次只能处理1024个上下文的BART模型做实验时,已经有能处理上百万上下文的方法了🤡
概述
提出了 Recurrent Memory Transformer 架构,作者并将其运用在BERT模型上,使BERT模型的有效上下文长度增加到了前所未有的200万,同时保持了较高的记忆检索精度。其方法允许存储和处理局部和全局信息,并使用递归使信息在输入序列的片段之间流动。
方法
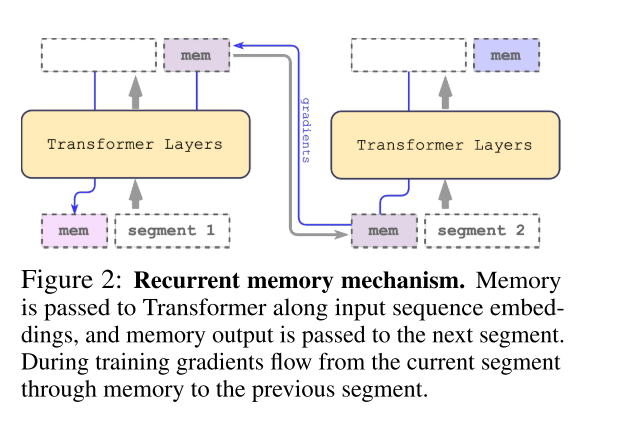
RMT(Recurrent Memory Transformer)的结构如下图所示,由于记忆机制允许存储和处理局部和全局信息,并通过递归在长序列的段之间传递信息。RMT的实现不需要改变 Transformer 模型,只需 对模型的输入和输出序列进行修改即可实现记忆和循环 。然后,模型被训练来控制记忆操作和序列表示处理。
具体来说,RMT 将长序列分成很多个片段,把前一个片段通过Transformer后得到的embedding作为memory token,影响下一个片段的embedding。相当于只在每个片段长度内做self-attention,然后把当前片段的状态浓缩到几个memory token上去,再用这个memory token去和下一个片段的embedding做self-attention,这样一直递归下去。
公式表示如下:
其中,N代表Transformer层数,在向前传播后包含了用于片段 更新的memory token,输入序列的片段被顺序地处理。为了进行循环,将memory token从当前段传递到下一个段的输入:
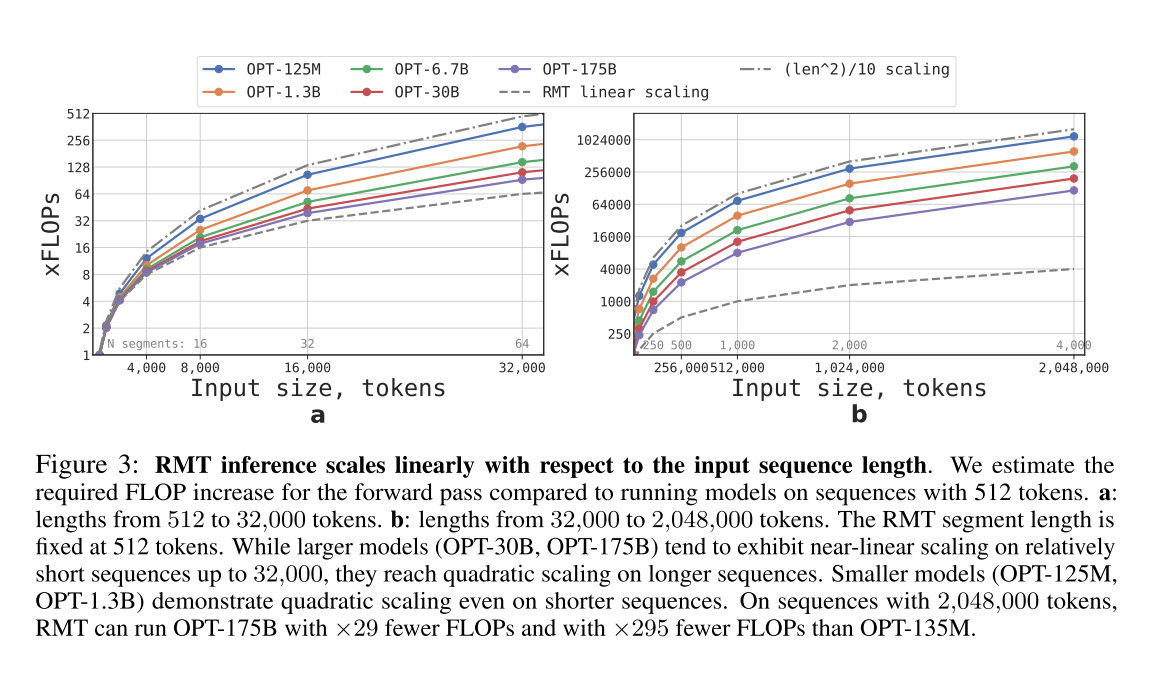
下图可以看到,计算量相比原始的Transformer大大降低,毕竟该架构只在每个片段内做self-attention,效率优势随着上下文的长度增加而更明显。
实验结果
为了测试记忆能力,作者构建了需要记忆简单事实和基本推理的合成数据集。任务输入由一个或多个事实和一个问题组成,该问题只能通过使用所有这些事实来回答。为增加任务难度,还添加了与问题或答案无关的自然语言文本,该文本起到了加入噪声的作用。
所以模型的任务是 将事实从无关的文本中分离出来,并用它们来回答问题 。该任务被公式化为 6 个分类,每个类别代表一个单独的答案选项。如下图所示,提出了综合任务和解决这些任务所需的 RMT 操作。在事实记忆任务中,事实陈述被放在序列的开头,在事实检测和记忆任务中,事实被随机放置在文本序列中,从而使检测更具挑战性。在推理任务中,提供答案所需的两个事实被随机放置在文本中。对于所有任务,问题都在序列的结尾。其中,‘mem’表示记忆符号,‘Q’表示问题,‘A’表示答案。
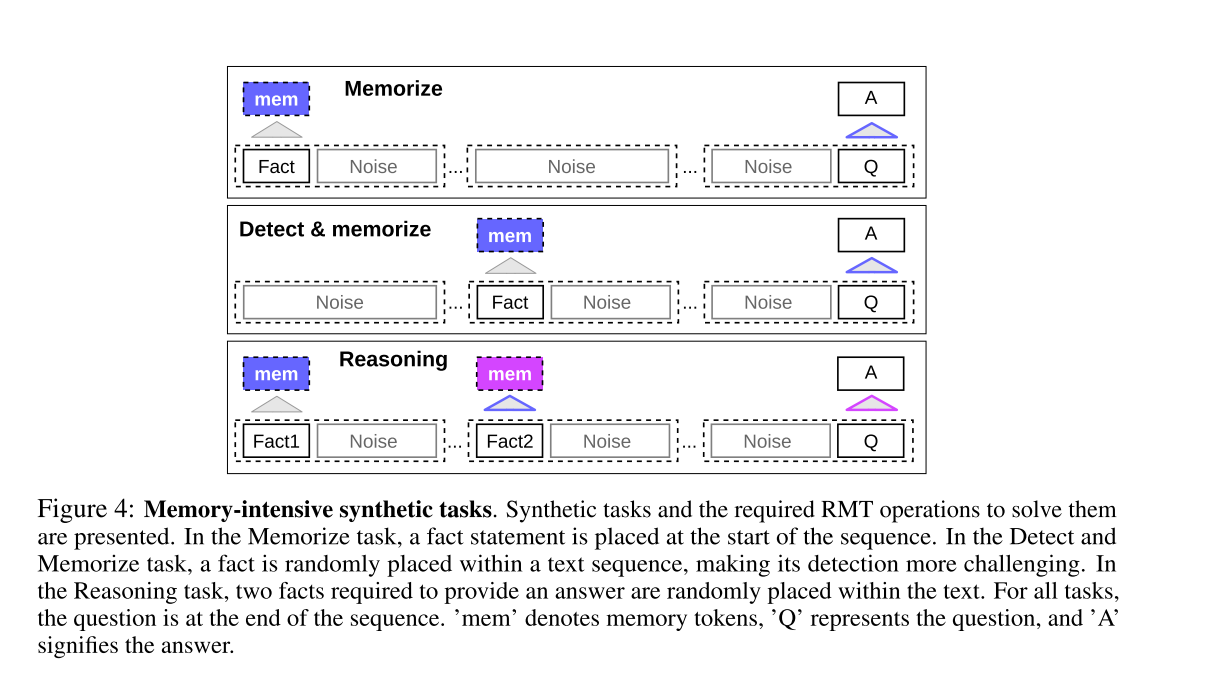
Task1:事实记忆
第一个任务是测试 RMT 在较长时间内在记忆中写入和存储信息的能力(如上图Memorize部分)。在最简单的情况下,事实始终位于输入的开头,而问题始终位于结尾。问题和答案之间的无关文本的数量逐渐增加,因此整个输入不适合单个模型输入。

Task2:事实检测 & 记忆
事实检测通过将事实移动到输入中的随机位置来增加任务难度(如上图 Detect & memorize部分)。这要求模型首先将事实与不相关的文本区分开来,将其写入记忆,然后使用它来回答位于结尾的问题。
Task3:推理任务
另一个与记忆有关的重要操作是利用记忆的事实和当前上下文进行推理。为了评估这个函数,使用了一个更复杂的任务(如图 3 的Reasoning部分),其中生成两个事实并在输入序列中随机定位。在序列结尾提出的问题以这样一种方式表述,即 任何事实都必须用于正确回答问题

Curriculum Learning
最初 RMT 在任务的较短版本上进行训练,在训练收敛时,通过增加一个片段来增加任务长度。Curriculum Learning的过程将持续至达到所需的输入长度。
在实验中从适合单个片段的序列开始,实际的段大小为 499,因为从模型输入中保留了 3 个 BERT 特殊 token 和 10 个记忆占位符,大小共为 512。
Extrapolation Abilities
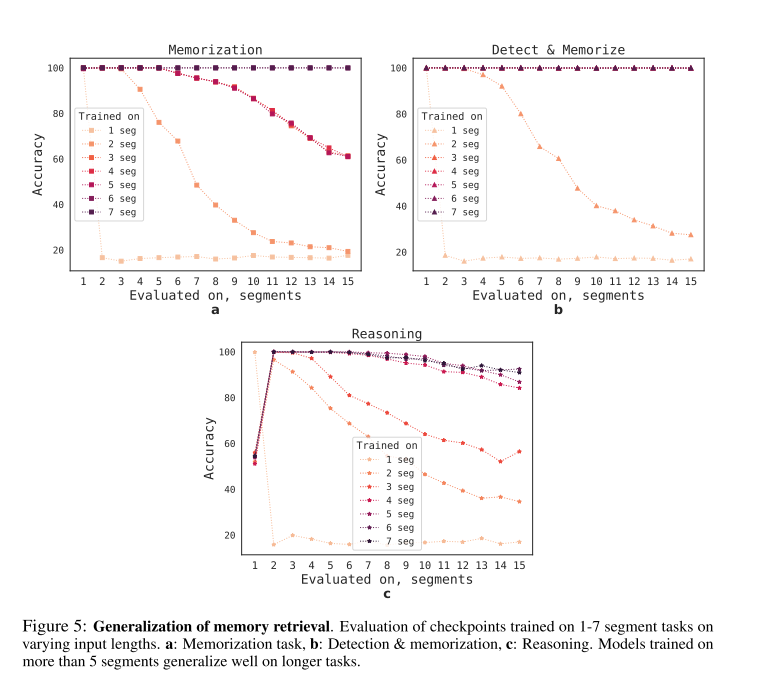
作者在BERT-base-cased上进行实验,训练时使用不同的片段(每个片段 512个token),以评估该方法对序列长度的泛化能力。实验发现RMT能泛化到两倍于训练长度的序列。例如下图Detect & Memorize这个task里,训练时候使用7个片段,评估时使用15个片段依然能取得100%的准确率。
Attention Patterns of Memory Operations
通过对下图中特定片段上的 RMT 注意力分析,观察到 记忆操作对应着注意力中的特定模式 。此外,在处理极长的序列时,学习的记忆操作表现出了很强的泛化能力,即使执行成千上万次仍然有效。这些操作并没有明确地受到任务损失的影响。

参考文献
Scaling Transformer to 1M tokens and beyond with RMT
太酷啦,Transformer 的有效上下文长度可扩展至百万级
Scaling Transformer to 1M tokens and beyond with RMT 把上下文长度提升到Million级别