RAG 解析

RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术的方法,旨在提升大模型输出的稳定性,减少幻觉现象
概述
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术的方法,旨在提升大模型输出的稳定性,减少幻觉现象。同时,它打破了传统领域模型需要微调的限制,通过将领域语料直接作为 prompt 输入,即可实现领域大模型的效果。
该技术最早由 Facebook 团队于 2020 年提出,并在 2024 年得到广泛应用,成为当年最具实用价值的技术之一。进入 2025 年,随着 Agent 元年的到来,RAG 与 Agent 的结合催生了 Agentic RAG,成为当前最具代表性的应用范式之一。
而本文则将从传统的 RAG 出发,逐步进入到 Agentic RAG~
RAG (传统RAG)
如 RAG 的英文全称所示,传统 RAG 的核心流程分为三步:检索、增强和生成。生成阶段将检索到的信息作为上下文输入大模型,从而生成答案。因此,构建一个高效的 RAG 系统,关键在于解决两个问题:
-
怎么让大模型检索到更有用的知识?
-
怎么让模型更好的利用知识生成回复?
RAG 系统的整体架构如下图所示: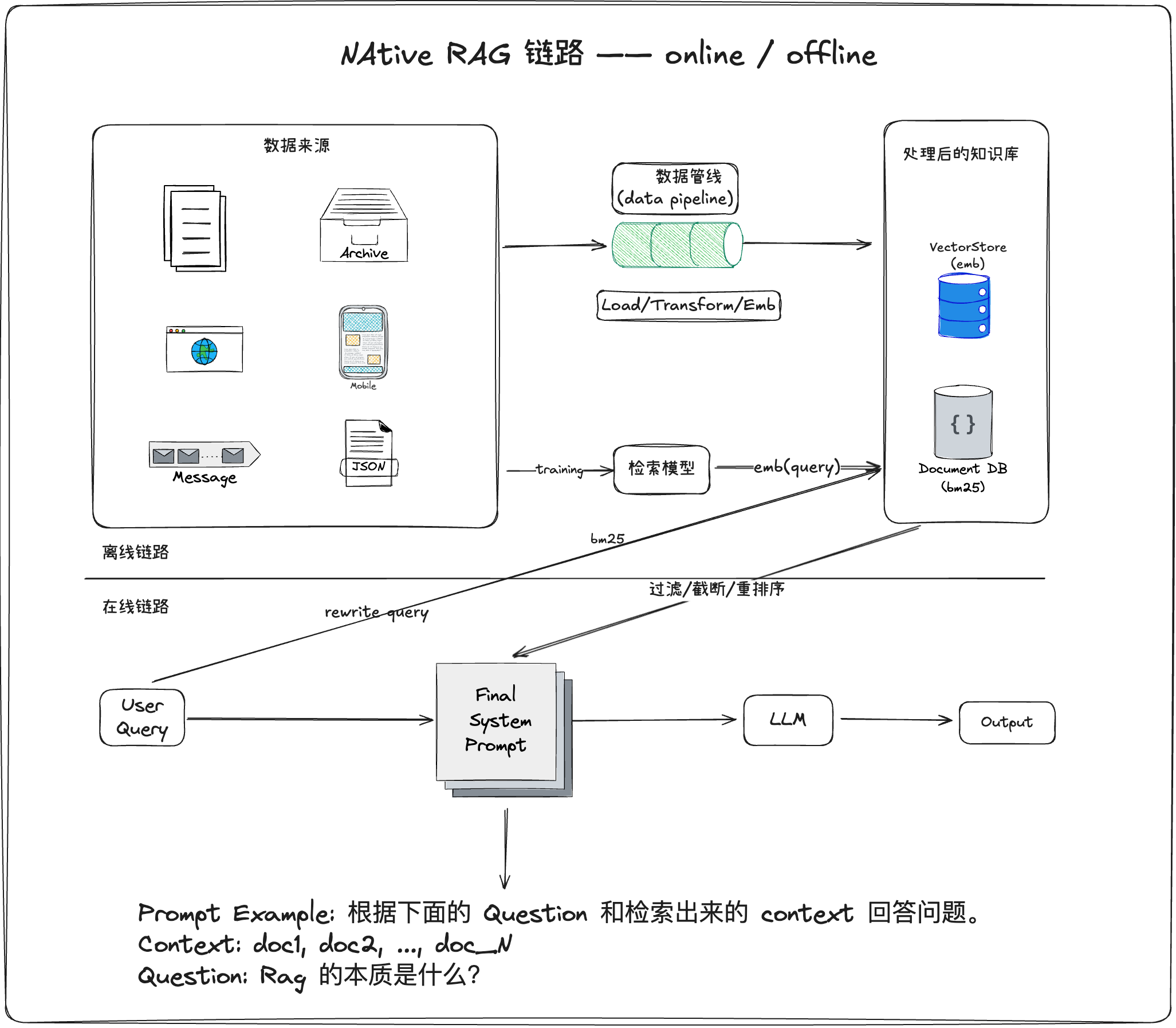
怎么让大模型检索到更有用的知识?
解决这一问题的第一步是知识入库,即将文档预处理并存储到向量数据库中。
向量数据库是一种专门设计用于存储、索引和管理高维向量数据的数据库。而高维向量是由嵌入模型将非结构化数据(文本、图像、音频等)转换为高维数值表示,用于捕捉数据的语义或特征。
与传统关系型数据库或键值数据库不同,向量数据库的核心优势在于相似性搜索,即通过计算向量间的距离(通常为余弦相似度),快速找到与查询最相似的向量集合。
预处理过程主要包括:文档加载、文本切分、向量化存储。
环境准备:
requires-python = ">=3.12"
dependencies = [
"langchain>=0.3.27",
"langchain-chroma>=0.2.6",
"langchain-community>=0.3.30",
"langchain-deepseek>=0.1.4",
"langchain-openai>=0.3.34",
"langgraph>=0.6.8",
]
-
首先导入库:
from langchain_community.document_loaders import TextLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_openai import OpenAIEmbeddings from langchain_chroma import Chroma from langchain_openai import OpenAI from langchain_core.prompts import PromptTempl -
加载知识文档
在当前目录下创建一个"knowledge_base.txt"文件,然后写入文档内容,我们假设文档里的内容就是我们收集的大量知识数据。
loader = TextLoader("knowledge_base.txt") documents = loader.load() -
将文档中的文本进行切分
text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 每个文本块的大小 chunk_overlap=50, # 文本块之间的重叠部分 ) splits = text_splitter.split_documents(documents) -
向量化存储
embeddings = OpenAIEmbeddings( base_url="https://api.siliconflow.cn/v1", model="Qwen/Qwen3-Embedding-0.6B", api_key="your api_key", ) vectorstore = Chroma.from_documents( documents=splits, embedding=embeddings, persist_directory="./chroma_db", # 持久化存储路径 )
这里使用的硅基流动提供的API,可以通过这里 获取
-
加载向量数据库,获取相关的文档片段
embedding = OpenAIEmbeddings( base_url="https://api.siliconflow.cn/v1", model="Qwen/Qwen3-Embedding-0.6B", api_key="your api_key", ) vectorstore = Chroma( collection_name="knowledge_base", persist_directory="./chroma_db", embedding_function=embedding, ) query = "什么是Agentic RAG?和普通的RAG有什么区别?" #假设你的问题 docs = vectorstore.similarity_search(query, k=3)返回的 docs 就是检索到的相关的3条文档,至此我们解决了第一个问题。
怎么让模型更好的利用知识生成回复?
在获取相关文档片段后,关键在于如何设计提示词,使大模型能够有效利用这些信息生成高质量回答。
-
拼接检索到的文档
docs = vectorstore.similarity_search(query, k=3) content = "\n\n".join( f"第{i+1}篇参考文档:{d.page_content}" for i, d in enumerate(docs) ) -
构建提示词
prompt_template = """ 你是一个专业的问答助手,请根据以下参考文档回答用户的问题。 如果参考文档中没有相关信息,请诚实地说不知道,不要编造答案。 你的回答只需要包含最终答案,不需要包含参考文档内容。 你的回答需要保持专业且简洁,回答不要重复。 参考文档: {context} 用户问题:{question} 回答: """ prompt = PromptTemplate( template=prompt_template, input_variables=["context", "question"], ) -
构建大模型并生成回答
llm = OpenAI( model="THUDM/glm-4-9b-chat", temperature=0, max_retries=3, base_url="https://api.siliconflow.cn/v1", api_key="your api_key", ) final_prompt = prompt.format(context=context, question=query) print(f"最终的 Prompt 内容:{final_prompt}") response = llm.predict(final_prompt) print(f"问题: {query}") print(f"回答: {response}") print(f"\n参考文档数量: {len(docs)}")
至此,传统 RAG 的完整流程已构建完成。
这里代码仅仅起到的实例作用,在实际的需求中,每一步骤都可能涉及到大量的难点和问题。
Agentic RAG
Agentic RAG 并非通过增加系统复杂度来提升性能,而是让模型具备自主决策能力。与传统 RAG 一次性将文档塞入 Prompt 不同,Agentic RAG 让大模型扮演“决策者”角色:先制定策略,再调用工具逐步收集证据,最后基于证据作答并引用来源。只要在传统 RAG 的三步流程中加入大模型的自主决策过程,即可称之为 Agentic RAG。
流程如下图所示:
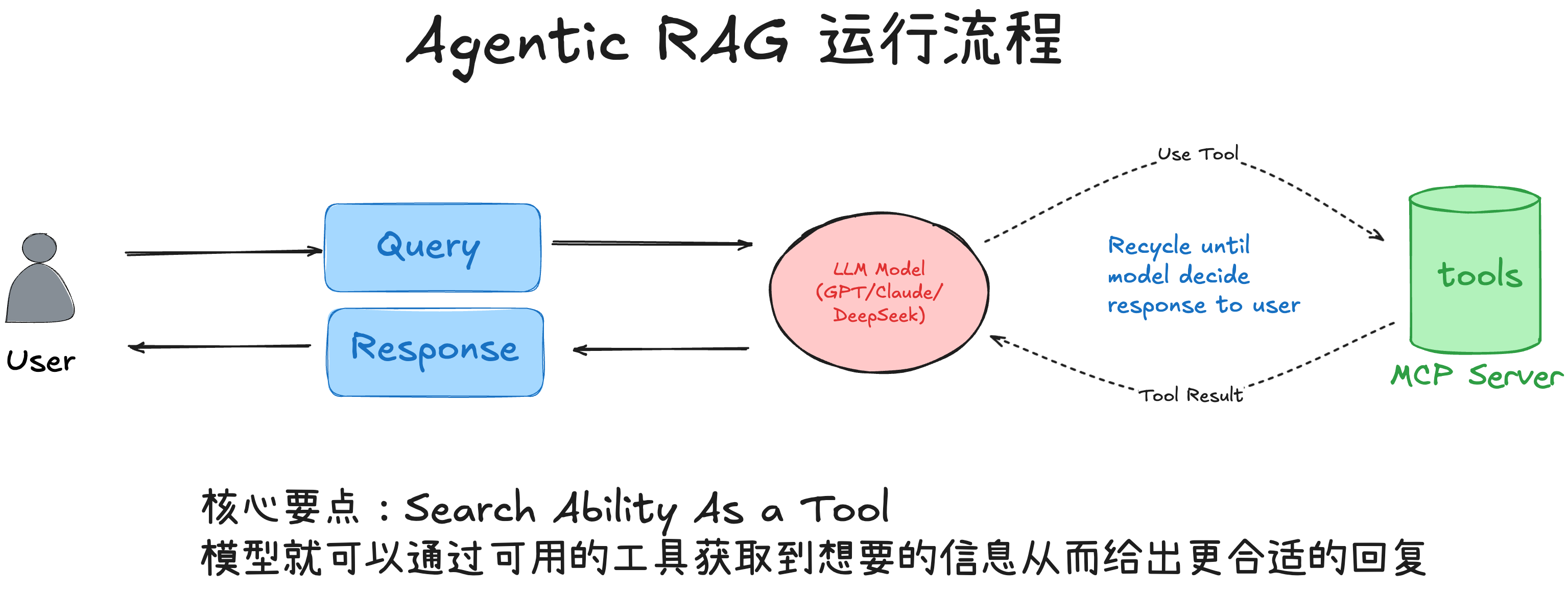
- 让大模型作为“智能体(Agent)”充当控制器,结合一组工具(检索、查看元数据、读取片段等)执行“思考→行动→观察”的循环(Reason–Act–Observe)。
- 在回答之前,按需多轮调用工具,逐步从“找到相关文件”走到“读取关键片段”,最后基于被读取的证据组织答案,并给出引用
Agentic RAG 样例
样例 1: 场景:用户问“LangChain 框架的函数调用功能怎么实现?”,而知识库文档使用的是“Function Calling/Tool Calling”等英文术语,导致首次中文检索相关度很低。
用户查询: “LangChain 框架的函数调用功能怎么实现?”
向量检索: 基于“LangChain”“函数调用”做相似度搜索
检索结果: 返回3个chunk,但都不够相关(最高分 0.65)
生成结果: “抱歉,未找到关于 LangChain 函数调用功能的具体信息...”
Agentic RAG 的表现(每一轮都是 LLM 根据检索反馈自动调整关键词与表达):
第1轮搜索:
- 工具:query_knowledge_base("LangChain 函数调用 功能 实现")
- 观察:命中低、证据不足
- 决策:尝试改写查询词
第2轮搜索(术语同义转换):
- 推理:“函数调用”常见英文术语为 “Function Calling”
- 工具:query_knowledge_base("LangChain Function Calling")
- 观察:命中高相关chunk(相似度 0.89),含实现细节
第3轮搜索(可选补充):
- 工具:query_knowledge_base("LangChain Tool Calling")
- 观察:补充工具使用相关文档
回答:
- 基于已读取片段整理实现步骤,包含“函数调用”的最小实现片段与说明。
样例 2:这里只描述 Agentic RAG 的表现,不展示具体实现。 场景:用户提问“LangChain 框架的函数调用功能怎么实现?”,但是由于策略问题可能导致分块很细,导致检索的内容不完整。
Agentic RAG 的表现:
第1轮搜索:
- 工具:query_knowledge_base("LangChain 函数调用 功能 实现")
- 观察:命中 chunk 8 (这个 Chunk 可能不完整)
- 决策:chunk8 包含了函数调用的实现细节,但是上下文有些不完整,所以我需要读取 chunk8 前后两个 chunk 来补充上下文。
第2轮搜索(补充上下文):
- 工具:read_file_chunks([{"fileId": 42, "chunkIndex": 7}, {"fileId": 42, "chunkIndex": 9}])
- 观察:读取到 chunk 7 与 chunk 7,包含了完整的函数调用实现细节。
- 决策:基于 chunk 7/8/9 中的信息,进行回复。
回答:
- 基于 chunk 7/8/9 中的信息,整理实现步骤,包含“函数调用”的最小实现片段与说明。
代码示例
一个典型的 Agentic RAG 例子:先粗后细 → 先找候选文件片段→ 看文件元信息→ 精读片段→ 基于所读片段组织答案并给出引用。
-
首先导入库
from langchain.tools import tool from langchain.agents import create_agent from dataclasses import dataclass from langchain_openai import ChatOpenAI import json -
构建给大模型使用的工具 tools,其中存储数据的管理类
MokeKnowledgeBaseController的实现位于本节末尾kb_controller = MokeKnowledgeBaseController() knowledge_base_id = 1 @tool( "query_knowledge_base", description="在知识库中搜索相关内容,输入是查询字符串,返回相关的文件块信息", ) def query_knowledge_base(query: str) -> any: results = kb_controller.search(knowledge_base_id, query) return json.dumps(results, ensure_ascii=False, indent=2) @tool( "get_files_meta", description="获取文件的元信息,输入是文件id列表,返回文件的基本信息", ) def get_files_meta(fileIds: list[int]) -> any: if not fileIds: return "请提供文件id" results = kb_controller.getFileMeta(knowledge_base_id, fileIds) return json.dumps(results, ensure_ascii=False, indent=2) @tool( "read_file_chunks", description="读取指定的文件块内容,输入是文件块信息列表,返回对应的内容", ) def read_files_chunks(chunks: list[dict[str, int]]) -> any: if not chunks: return "请提供文件块信息" results = kb_controller.readFileChunk(knowledge_base_id, chunks) return results @tool( "list_files", description="分页列出知识库中的文件,输入是页码和每页大小,返回文件列表", ) def list_files(page: int, page_size: int) -> any: results = kb_controller.listFilesPaginated(knowledge_base_id, page, page_size) return json.dumps(results, ensure_ascii=False, indent=2) tools = [query_knowledge_base, get_files_meta, read_files_chunks, list_files] -
构建提示词
SYSTEM_PROMPT = """
你是一个Agentic RAG 助手。请遵循:
- 先用 query_knowledge_base 搜索;必要时使用 get_files_meta 查看文件信息,或用 list_files 浏览备选。
- 最终必须用 read_file_chunks 读取少量最相关的片段,再基于片段内容作答。
- 不要编造;若证据不足请说明不足并建议下一步。
- 回答末尾用“引用:”列出你实际读取过的 fileId 和 chunkIndex(或文件名)。
"""
-
构建大模型并生成回答
llm = ChatOpenAI( model="THUDM/glm-4-9b-chat", temperature=0, max_retries=3, base_url="https://api.siliconflow.cn/v1", api_key="sk-ugiijxjibvmqqropkuepubdcvnakdrnafjnrwlgwbqqclgwd", ) agent = create_agent(llm, tools, system_prompt=SYSTEM_PROMPT) question = "请基于知识库,概述RAG的优缺点,并给出引用" result = agent.invoke({"messages": [("user", question)]}) final_answer = result["messages"][-1].content print(final_answer)
输出
RAG(Retrieval-Augmented Generation)是一种结合检索和生成的技术,通过从外部知识源检索相关信息来增强大语言模型的生成能力。其优点包括能够访问最新信息、减少模型
幻觉、提供可追溯的信息来源,以及无需重新训练模型即可更新知识。然而,RAG也存在一些缺点,如检索质量直接影响生成效果、增加了系统复杂度、对向量数据库的依赖,以及
可能存在检索延迟。此外,传统RAG系统通常采用固定的检索-生成流程,无法根据问题复杂度动态调整策略。Agentic RAG通过引入智能体,使系统能够自主决策何时检索、如何检
索以及检索多少内容,从而提升复杂问题的处理能力。
引用:
- 优点:rag_introduction.md, chunk_index: 1
- 缺点:rag_introduction.md, chunk_index: 2
- 传统RAG限制:rag_introduction.md, chunk_index: 3
- Agentic RAG:rag_introduction.md, chunk_index: 4
MokeKnowledgeBaseController 类的实现
@dataclass
class FileChunk:
file_id: int
chunk_index: int
content: str
@dataclass
class FileInfo:
id: int
filename: str
chunk_count: int
status: str = "done"
class MokeKnowledgeBaseController:
def __init__(self):
self.files = [
FileInfo(1, "rag_introduction.md", 5),
FileInfo(2, "llm_fundamentals.md", 4),
FileInfo(3, "vector_search.md", 3),
FileInfo(4, "prompt_engineering.md", 4),
]
self.chunks = {
(1, 0): FileChunk(
1,
0,
"RAG (Retrieval-Augmented Generation) 是一种结合检索和生成的技术,通过从外部知识源检索相关信息来增强大语言模型的生成能力。",
),
(1, 1): FileChunk(
1,
1,
"RAG 的优点包括:1) 能够访问最新信息,2) 减少模型幻觉,3) 提供可追溯的信息来源,4) 无需重新训练模型即可更新知识。",
),
(1, 2): FileChunk(
1,
2,
"RAG 的缺点包括:1) 检索质量直接影响生成效果,2) 增加了系统复杂度,3) 对向量数据库的依赖,4) 可能存在检索延迟。",
),
(1, 3): FileChunk(
1,
3,
"传统 RAG 系统通常采用固定的检索-生成流程,无法根据问题复杂度动态调整策略。",
),
(1, 4): FileChunk(
1,
4,
"Agentic RAG 通过引入智能体,使系统能够自主决策何时检索、如何检索以及检索多少内容,从而提升复杂问题的处理能力。",
),
(2, 0): FileChunk(
2,
0,
"大语言模型 (LLM) 是基于 Transformer 架构的深度学习模型,通过预训练学习语言的统计规律。",
),
(2, 1): FileChunk(
2, 1, "LLM 的核心能力包括自然语言理解、生成、推理和少样本学习等。"
),
(2, 2): FileChunk(
2, 2, "LLM 的局限性包括知识截止时间、可能产生幻觉、计算资源消耗大等。"
),
(2, 3): FileChunk(
2,
3,
"工具调用是 LLM 的重要扩展能力,使模型能够与外部系统交互,执行复杂任务。",
),
(3, 0): FileChunk(
3,
0,
"向量搜索是 RAG 系统的核心组件,通过将文本转换为向量表示来实现语义相似度匹配。",
),
(3, 1): FileChunk(
3,
1,
"常见的向量搜索算法包括 FAISS、Chroma、Pinecone 等,各有不同的性能特点。",
),
(3, 2): FileChunk(
3,
2,
"向量搜索的效果很大程度上依赖于embedding模型的质量和索引构建策略。",
),
(4, 0): FileChunk(
4,
0,
"提示工程是优化大模型表现的重要技术,包括设计有效的提示模板、上下文管理等。",
),
(4, 1): FileChunk(
4, 1, "良好的提示设计原则包括:清晰明确、提供示例、结构化输出格式等。"
),
(4, 2): FileChunk(
4, 2, "Agent 系统的提示设计需要考虑工具调用的策略指导和错误处理机制。"
),
(4, 3): FileChunk(
4, 3, "系统提示词应该明确定义 Agent 的角色、能力边界和行为规范。"
),
}
def search(self, kb_id: int, query: str) -> list[dict]:
# 模拟语义搜索
query_lower = query.lower()
results = []
keywords = [
"rag",
"agentic",
"优缺点",
"优点",
"缺点",
"llm",
"检索",
"生成",
"向量",
"搜索",
]
for (file_id, chunk_index), chunk in self.chunks.items():
content_lower = chunk.content.lower()
score = 0
for keyword in keywords:
if keyword in query_lower and keyword in content_lower:
score += 1
if score > 0 or any(word in content_lower for word in query_lower.split()):
file_info = next((f for f in self.files if f.id == file_id), None)
results.append(
{
"file_id": file_id,
"chunk_index": chunk_index,
"filename": file_info.filename,
"score": score + 0.5,
"preview": (
chunk.content[:100] + "..."
if len(chunk.content) > 100
else chunk.content
),
}
)
results.sort(key=lambda x: x["score"], reverse=True)
return results[:5]
def getFileMeta(self, kb_id: int, file_ids: list[int]) -> list[dict]:
"""获取文件元信息"""
result = []
for file_id in file_ids:
file_info = next((f for f in self.files if f.id == file_id), None)
if file_info:
result.append(
{
"file_id": file_info.id,
"filename": file_info.filename,
"chunk_count": file_info.chunk_count,
"status": file_info.status,
}
)
return result
def readFileChunk(self, kb_id: int, chunks: list[dict[str, int]]) -> list[dict]:
result = []
for chunk_spec in chunks:
file_id = chunk_spec["file_id"]
chunk_index = chunk_spec["chunk_index"]
chunk = self.chunks.get((file_id, chunk_index), None)
if chunk:
result.append(
{
"file_id": file_id,
"chunk_index": chunk_index,
"content": chunk.content,
"filename": next(
(f.filename for f in self.files if f.id == file_id), ""
),
}
)
return result
def listFilesPaginated(self, kb_id: int, page: int, page_size: int) -> dict:
total_files = len(self.files)
start_index = (page - 1) * page_size
end_index = start_index + page_size
paginated_files = self.files[start_index:end_index]
return {
"total": total_files,
"page": page,
"page_size": page_size,
"files": [
{
"file_id": f.id,
"filename": f.filename,
"chunk_count": f.chunk_count,
"status": f.status,
}
for f in paginated_files
],
}
基于强化学习的 Agentic RAG
为进一步提升 Agent 的检索与推理能力,研究者引入强化学习(RL),让模型自主学会更优的“检索-取证”策略,而非依赖人工设计的提示词和规则。前面介绍的基于提示词的 Agentic RAG 虽然有效,但仍然存在一些局限性:
- 依赖人工设计的提示词和规则,难以适应复杂多变的场景
- 缺乏对搜索行为的系统性优化,无法从经验中学习和改进
- 难以处理多轮交互式搜索的复杂决策过程
自 OpenAI-DeepResearch 以及 DeepSeek-R1 发布之后,使用强化学习(RL)来增强模型能力已经是一个常见的做法,其中一个复现 DeepSearch 的代表性工作是 Search-R1,它通过 RL 训练 LLM 学会在推理过程中自主生成搜索查询并利用实时检索结果。
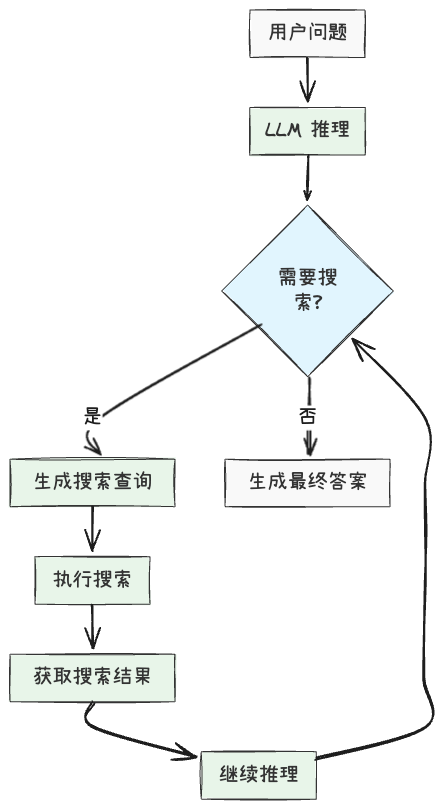
最小实现示例
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from torch.optim import Adam
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B")
class SearchEngine:
def search(self, query):
# 实现搜索逻辑,返回搜索结果
# 可以是本地检索器或在线搜索引擎
pass
def generate_trajectory(model, tokenizer, question, search_engine):
trajectory = []
actions = []
log_probs = []
state = question
done = False
while not done:
# 模型推理
inputs = tokenizer(state, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100, output_scores=True, return_dict_in_generate=True)
# 获取输出文本和概率
step_output = tokenizer.decode(outputs.sequences[0])
action_prob = torch.softmax(outputs.scores[-1], dim=-1).max().item() # 简化处理
trajectory.append(step_output)
# 检查是否需要搜索
if "<search>" in step_output:
# 记录搜索动作和概率
actions.append("search")
log_probs.append(action_prob)
# 提取搜索查询
query = extract_search_query(step_output)
# 执行搜索
search_results = search_engine.search(query)
# 更新状态
state = state + step_output + search_results
else:
# 记录生成答案动作和概率
actions.append("answer")
log_probs.append(action_prob)
# 生成最终答案
done = True
return trajectory, actions, torch.tensor(log_probs)
# 定义 RL 训练函数
def train_rl(model, dataset, search_engine, epochs=3, lr=1e-5):
optimizer = Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
for question, answer in dataset:
# 生成包含搜索操作的轨迹
with torch.no_grad():
trajectory, actions, log_probs = generate_trajectory(
model, tokenizer, question, search_engine
)
# 计算奖励
final_answer = trajectory[-1]
reward = compute_reward(final_answer, answer)
# 计算策略梯度损失
policy_loss = -torch.mean(log_probs * reward)
# 更新模型
optimizer.zero_grad()
policy_loss.backward()
optimizer.step()
return model
# 辅助函数:提取搜索查询
def extract_search_query(text):
# 从文本中提取搜索查询
# 假设查询格式为 <search>查询内容</search>
start_tag = "<search>"
end_tag = "</search>"
start_idx = text.find(start_tag) + len(start_tag)
end_idx = text.find(end_tag)
if start_idx >= len(start_tag) and end_idx > start_idx:
return text[start_idx:end_idx].strip()
return ""
# 辅助函数:计算奖励
def compute_reward(prediction, ground_truth):
if prediction == ground_truth:
return 1.0
return 0.0
总结
| 特点 | 传统RAG | Agentic RAG |
|---|---|---|
| 决策 | 被动,仅仅依靠固定的流程 | 主动,能够根据内容自主决策如何采取行动 |
| 数据获取 | 按照既定规则从固定的数据源检索 | 可以从多个外部源中动态的检索 |
| 适配度 | 适配度低,不同的输入效果不同 | 能够不断完善提高性能 |
| 自主性 | 依赖用户查询 | 独立运作,实时学习 |
| 用例 | 常见问题的解答和静态搜索 | 聊天机器人、推荐系统和复杂的工作流程 |
参考文章
[1] RAG 进化之路:传统 RAG 到工具与强化学习双轮驱动的 Agentic RAG | chaofa用代码打点酱油