命名实体识别在HanLP中的实现

命名实体:文本中有一些描述实体的词汇。比如人名、地名、组织机构名、股票基金、医学术语等
具有以下特点:
- 数量无穷。比如宇宙中的恒星命名、新生儿的命名不断出现新组合。
- 构词灵活。比如中国工商银行,既可以称为工商银行,也可以简称工行。
- 类别模糊。有一些地名本身就是机构名,比如“国家博物馆”。
识别出句子中命名实体的边界与类别的任务称为命名实体识别
- 对于规则性较强的命名实体,比如网址、E-mail、IBSN、商品编号等。可以通过正则表达式处理,未匹配上的片段交给统计模型处理。
- 对于较短的命名实体,比如人名,可以通过分词来确定边界,通过词性标注确定类别
命名实体识别也可以转化为一个序列标注问题,可以将命名实体识别附着到{B,M,E,S}标签
基于规则的命名实体识别
人名识别
音译人名用字较为固定,若音译字符连续的出现,则很有可能来自于一个音译人名。因此可以通过如下规则来进行人名识别:
-
若粗分结果中某词语的备选词性有出现音译人名中的词语,则从该词的出发,向后扫描进行合并,知道词语为非音译人名库中的词语。
例如:
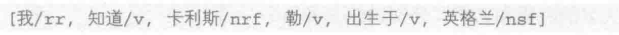
"卡利斯"触发了合并规则,直到遇到“出生于”才会中止合并

数词英文识别
数词(123、一、二、三)的识别的常见做法为:
-
获取每个字符的类型
-
然后扫描字符串的类型数组,将类型相同的字符合并,利用类型(数词m或者英文nx)来确定词性
HanLP中实现如下
from pyhanlp import * ViterbiSegment = JClass('com.hankcs.hanlp.seg.Viterbi.ViterbiSegment') CharType = JClass('com.hankcs.hanlp.dictionary.other.CharType') segment = ViterbiSegment() print(segment.seg("牛奶三〇〇克壹佰块")) print(segment.seg("牛奶300克100块")) print(segment.seg("牛奶300g100rmb")) # 自定义字符串 text = "牛奶300~400g100rmb" print(segment.seg(text)) CharType.set('~', CharType.CT_NUM) print(segment.seg(text))结果
[牛奶/nf, 三〇〇/m, 克/q, 壹佰/m, 块/q] [牛奶/nf, 300/m, 克/q, 100/m, 块/q] [牛奶/nf, 300/m, g/nx, 100/m, rmb/nx] [牛奶/nf, 300~400/m, g/nx, 100/m, rmb/nx] [牛奶/nf, 300~400/m, g/nx, 100/m, rmb/nx]总结
基于规则和词典的方法是命名实体识别中最早使用的方法,规则简单易于实现,但是一般而言,当提取的规则能比较精确地反映语言现象时,基于规则的方法性能要优于基于统计的方法。但是这些规则往往依赖于具体语言、领域和文本风格,编制过程耗时且难以涵盖所有的语言现象,特别容易产生错误,系统可移植性不好,对于不同的系统需要语言学专家重新书写规则。基于规则的方法的另外一个缺点是代价太大,存在系统建设周期长、移植性差而且需要建立不同领域知识库作为辅助以提高系统识别能力等问题。
命名实体识别语料库
1998《人民日报》语料库
假设我们只关心人名、地名和机构名的话,PKU语料就可以视作命名实体识别语料库。其中一句典型样例为:

微软命名实体识别语料库
为xml格式,并且命名实体之外的词语没有标注词性,例句为:

下载语料库
本文使用PKU98语料库进行训练
import zipfile
import os
from pyhanlp.static import download, remove_file, HANLP_DATA_PATH
def test_data_path():
data_path = os.path.join(HANLP_DATA_PATH, 'test')
if not os.path.isdir(data_path):
os.mkdir(data_path)
return data_path
## 验证是否存在 MSR语料库,如果没有自动下载
def ensure_data(data_name, data_url):
root_path = test_data_path()
dest_path = os.path.join(root_path, data_name)
if os.path.exists(dest_path):
return dest_path
if data_url.endswith('.zip'):
dest_path += '.zip'
download(data_url, dest_path)
if data_url.endswith('.zip'):
with zipfile.ZipFile(dest_path, "r") as archive:
archive.extractall(root_path)
remove_file(dest_path)
dest_path = dest_path[:-len('.zip')]
return dest_path
## 指定 PKU 语料库
PKU98 = ensure_data("pku98", "http://file.hankcs.com/corpus/pku98.zip")
NER_MODEL = os.path.join(PKU98, 'ner.bin')
基于统计的命名实体识别
基于HMM序列标注的命名实体识别
## 开始 HMM 命名实体识别
HMMNERecognizer = JClass('com.hankcs.hanlp.model.hmm.HMMNERecognizer')
AbstractLexicalAnalyzer = JClass('com.hankcs.hanlp.tokenizer.lexical.AbstractLexicalAnalyzer')
PerceptronSegmenter = JClass('com.hankcs.hanlp.model.perceptron.PerceptronSegmenter')
PerceptronPOSTagger = JClass('com.hankcs.hanlp.model.perceptron.PerceptronPOSTagger')
Utility = JClass('com.hankcs.hanlp.model.perceptron.utility.Utility')
def train(corpus):
recognizer = HMMNERecognizer()
recognizer.train(corpus) #训练
return recognizer
def test(recognizer):
# 包装了感知机分词器和词性标注器的词法分析器
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), PerceptronPOSTagger(), recognizer)
print(analyzer.analyze("华北电力公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"))
if __name__ == '__main__':
recognizer = train(PKU98)
test(recognizer)
识别结果如下:
华北电力公司/nt 董事长/n 谭旭光/nr 和/c 秘书/n 胡花蕊/nr 来到/v 美国纽约/ns 现代/ntc 艺术/n 博物馆/n 参观/v
其中机构名“华北电力公司”、人名“谭旭光”“胡花蕊”全部识别正确。但是地名“美国纽约现代艺术博物馆”则无法识别。有以下两个原因:
- PKU 语料库中没有出现过这个样本。
- 隐马尔可夫模型无法利用词性特征。
对于第一个原因,只能额外标注一些语料。对于第二个原因可以通过切换到更强大的模型来解决。
基于感知机序列标注的命名实体识别
与分词和词性标注一样,结构化感知机仍然可以胜任命名实体识别任务。
## 开始 感知机 命名实体识别
NERTrainer = JClass('com.hankcs.hanlp.model.perceptron.NERTrainer')
PerceptronNERecognizer = JClass('com.hankcs.hanlp.model.perceptron.PerceptronNERecognizer')
PerceptronSegmenter = JClass('com.hankcs.hanlp.model.perceptron.PerceptronSegmenter')
PerceptronPOSTagger = JClass('com.hankcs.hanlp.model.perceptron.PerceptronPOSTagger')
AbstractLexicalAnalyzer = JClass('com.hankcs.hanlp.tokenizer.lexical.AbstractLexicalAnalyzer')
Utility = JClass('com.hankcs.hanlp.model.perceptron.utility.Utility')
def train(corpus, model):
trainer = NERTrainer()
return PerceptronNERecognizer(trainer.train(corpus, model).getModel())
def test(recognizer):
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), PerceptronPOSTagger(), recognizer)# 包装了感知机分词器和词性标注器的词法分析器
print(analyzer.analyze("华北电力公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"))
if __name__ == '__main__':
recognizer = train(PKU98, NER_MODEL)
test(recognizer)
结果如下:
华北电力公司/nt 董事长/n 谭旭光/nr 和/c 秘书/n 胡花蕊/nr 来到/v [美国纽约/ns 现代/ntc 艺术/n 博物馆/n]/ns 参观/v
与隐马尔可夫模型相比,已经能够正确识别地名了。
同时,感知机命名实体识别还支持在线学习。
通过调用PerceptronLexicalAnalyzer接口来在线学习新知识
from pyhanlp import *
PerceptronNERecognizer = JClass('com.hankcs.hanlp.model.perceptron.PerceptronNERecognizer')
PerceptronSegmenter = JClass('com.hankcs.hanlp.model.perceptron.PerceptronSegmenter')
PerceptronPOSTagger = JClass('com.hankcs.hanlp.model.perceptron.PerceptronPOSTagger')
Sentence = JClass('com.hankcs.hanlp.corpus.document.sentence.Sentence')
def train(corpus, model):
trainer = NERTrainer()
return PerceptronNERecognizer(trainer.train(corpus, model).getModel())
if __name__ == '__main__':
recognizer = train(PKU98, NER_MODEL)#创建感知机词法分析器
analyzer = PerceptronLexicalAnalyzer(PerceptronSegmenter(), PerceptronPOSTagger(), recognizer)# 根据标注样本的字符串形式创建等价的Sentence对象
sentence = Sentence.create("与/c 特朗普/nr 通/v 电话/n 讨论/v [太空/s 探索/vn 技术/n 公司/n]/nt") # ②
# 测试词法分析器对样本的分析结果是否与标注一致,若不一致重复在线学习,直到两者一致。
while not analyzer.analyze(sentence.text()).equals(sentence): # ③
analyzer.learn(sentence)
基于条件随机场序列标注的命名实体识别
CRFNERecognizer = JClass('com.hankcs.hanlp.model.crf.CRFNERecognizer')
AbstractLexicalAnalyzer = JClass('com.hankcs.hanlp.tokenizer.lexical.AbstractLexicalAnalyzer')
Utility = JClass('com.hankcs.hanlp.model.perceptron.utility.Utility')
def train(corpus, model):
# 零参数的构造函数代表加载配置文件默认的模型,必须用null None 与之区分。
recognizer = CRFNERecognizer(None) # 空白
recognizer.train(corpus, model)
return recognizer
def test(recognizer):
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), PerceptronPOSTagger(), recognizer)
print(analyzer.analyze("华北电力公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"))
if __name__ == '__main__':
recognizer = train(PKU98, NER_MODEL)
test(recognizer)
运行时间较长,结果如下:
华北电力公司/nt 董事长/n 谭旭光/nr 和/c 秘书/n 胡花蕊/nr 来到/v [美国纽约/ns 现代/ntc 艺术/n 博物馆/n]/ns 参观/v
得到了正确结果。
命名实体识别标准化评测
各个命名实体识别模块的准确率如何,并非只能通过几个句子主观感受。任何监督学习任务都有一套标准化评测方案,对于命名实体识别,按照惯例引入P、R 和 F1 评测指标。
引用《自然语言处理入门》书中的数据:
在1998年1月《人民日报》语料库上的标准化评测结果如下:
| 模型 | P | R | F1 |
|---|---|---|---|
| 隐马尔可夫模型 | 79.01 | 30.14 | 43.64 |
| 感知机 | 87.33 | 78.98 | 82.94 |
| 条件随机场 | 87.93 | 73.75 | 80.22 |
总结
条件随机场为命名实体识别提供了一个特征灵活、全局最优的标注框架,但同时存在收敛速度慢、训练时间长的问题。一般说来,支持向量机在正确率上要比隐马尔可夫模型高一些,但是隐马尔可夫模型在训练和识别时的速度要快一些,主要是由于在利用维特比算法求解命名实体类别序列的效率较高。隐马尔可夫模型更适用于一些对实时性有要求以及像信息检索这样需要处理大量文本的应用,如短文本命名实体识别。
基于统计的方法对语料库的依赖也比较大,而可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少。
自定义领域命名实体识别
假设我们想要识别专门领域中的命名实体,这时,我们就要自定义领域的语料库了。
-
收集一些文本, 作为标注语料库的原料,称为生语料
-
生语料准备就绪后,就可以开始标注了。对于命名实体识别语料库,若以词语和词性为特征的话,还需要标注分词边界和词性。可以在HanLP的标注基础上进行校正,这样工作量更小。
例如:

通过HanLP词法分析器,输出:
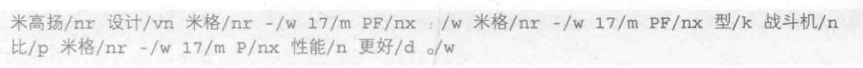
人工定义标签,将米格-17PF作为一个标签
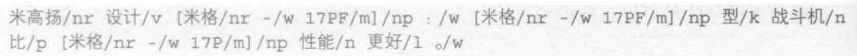
样本标注了数千个之后,生语料就被标注成了熟语料。
- 通过使用感知机作为训练算法,让语料库能够正确识别