LONGNET: Scaling Transformers to 1,000,000,000 Tokens

前段时间刚介绍了能使模型处理上下文扩展到百万级别的方法,现在微软又提出了一种能扩展到十亿级别的方法(不过有标题党的嫌疑,因为在实验中作者只扩展到了百万级别)
概述
微软研究提出了一种新的Transformer变体:LONGNET,该架构将序列标记长度扩展到了10亿级别,且不会影响较短序列的性能。它采用用一个名为 膨胀注意力(dilated attention) 的新颖组件取代了普通Transformers的注意力,其设计原则为:注意力分配随着Token之间距离的增加呈指数减少。这使得LONGNET可以获得线性计算复杂度和对数依赖性,从而解决了有限的注意力资源和每个标记的可访问性之间的矛盾。
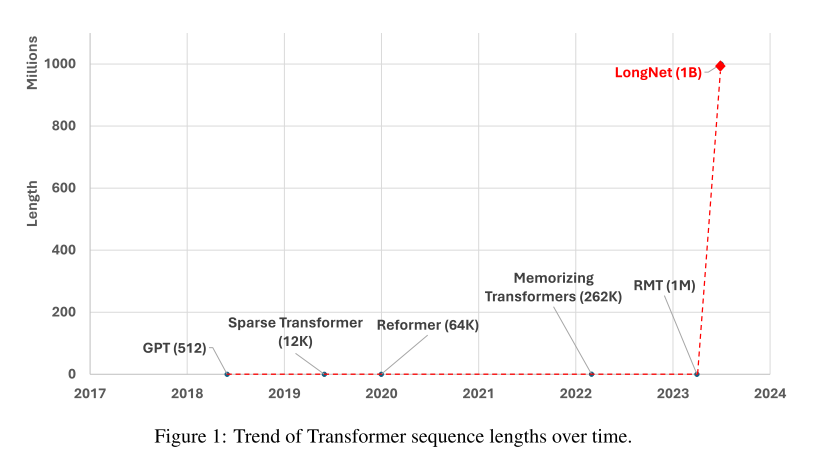
LONGNET
膨胀注意力
膨胀注意力由一系列用于建模短程和长程依赖关系的注意力模式组成,注意力模式的数量可以根据序列长度进行扩展。在每个注意力模式中,查询向量和键向量之间的点积被分解为多个子点积,每个子点积仅涉及到一小部分的键向量。这种分解方式可以减少计算复杂度,同时也可以使模型更好地处理长序列。具体如下图所示:
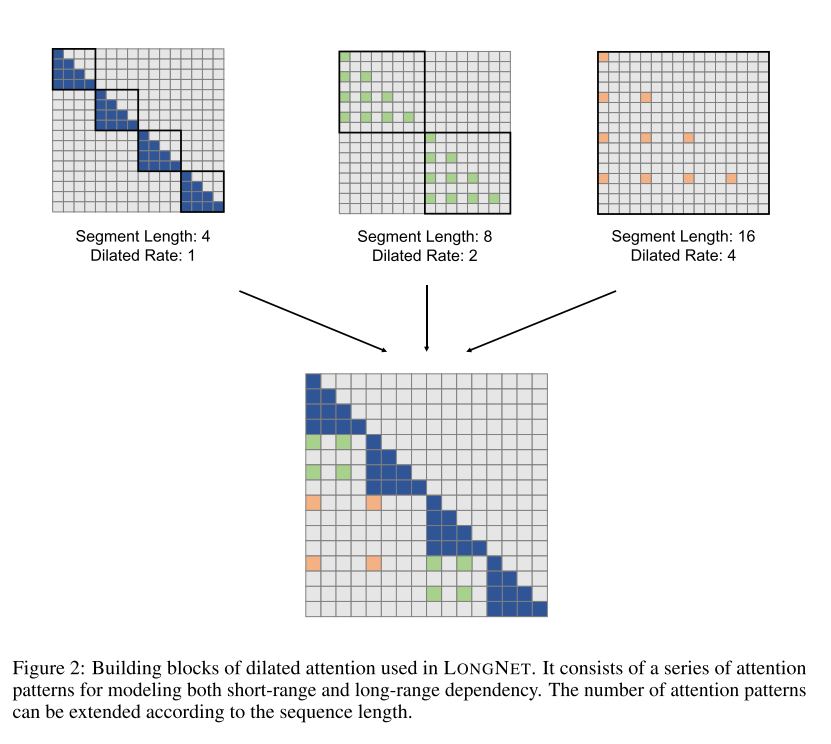
膨胀注意力还引入了“多头”机制,可以在不同的头之间分别计算注意力。每个头都有自己的偏移量,这样就可以在不同的位置上计算注意力,从而更好地捕捉序列中的信息。通过这种方式,扩张注意力可以更好地处理长序列,同时保持较短序列的性能。具体如下图所示:
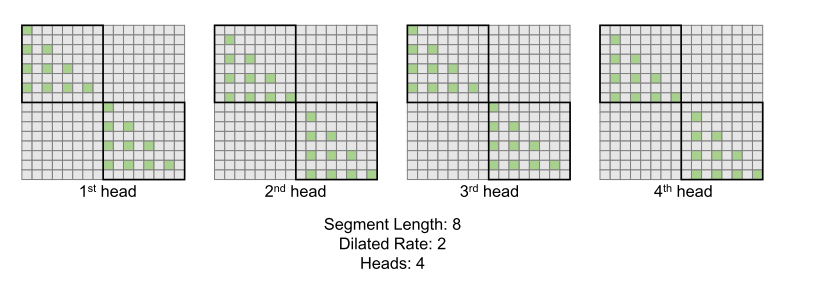
看到这里,会不会觉得这里的膨胀注意力其实和之前介绍的Longformer 很相似?
分布式训练
虽然 膨胀注意力的计算复杂度已经大幅降低到 ,但由于计算和内存的限制,在单个 GPU 设备上将序列长度扩展到百万级别是不可行的。有一些用于大规模模型训练的分布式训练算法,如模型并行、序列并行 和 流水线并行,然而这些方法对于 LONGNET 来说是不够的,特别是当序列维度非常大时。
作者利用 LONGNET 的线性计算复杂度来进行序列维度的分布式训练。下图展示了在两个 GPU 上的分布式算法,还可以进一步扩展到任意数量的设备。
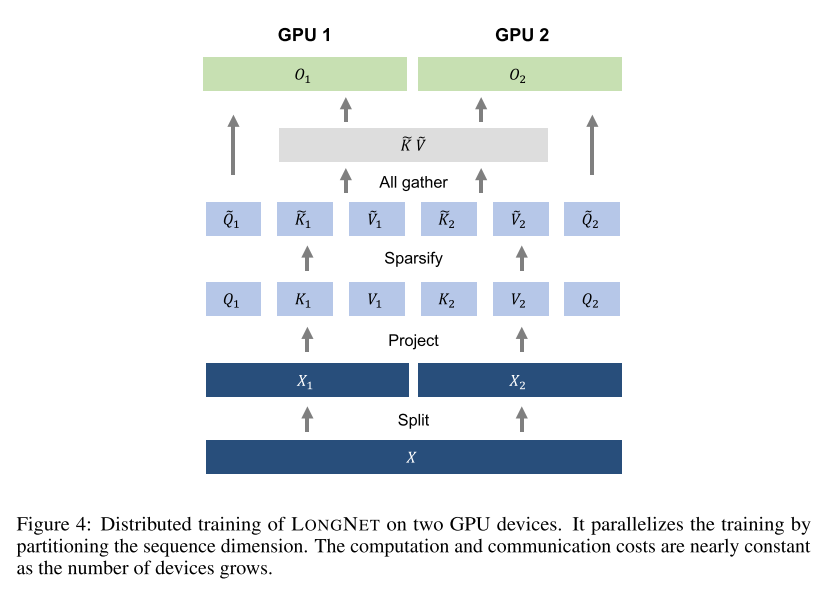
也就将上下文划分成多个segment,每个GPU处理一个segment进行膨胀注意力,然后再将每个膨胀注意力组合起来,也就是说只要GPU数量足够,那么就可以扩展到任意长度的context
实验结果
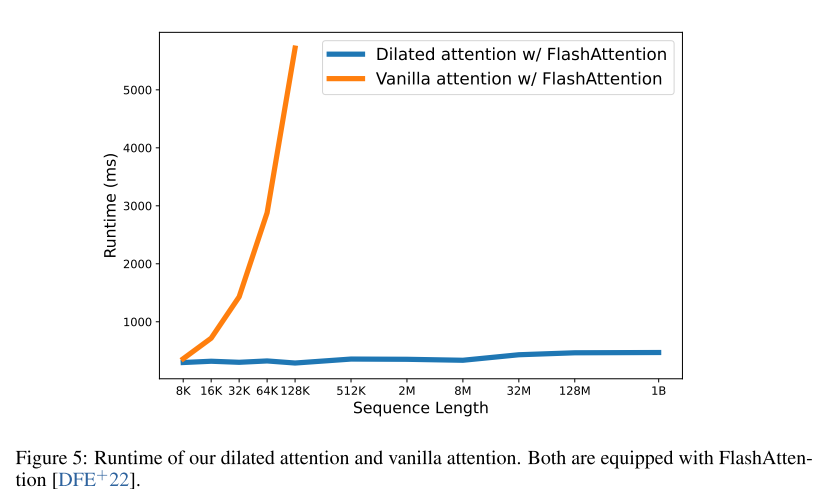
LONGNET能够在几乎恒定的运行时间下有效地将序列长度扩展到1B个Token如下图所示,而普通Transformer则面临着二次复杂度的问题。
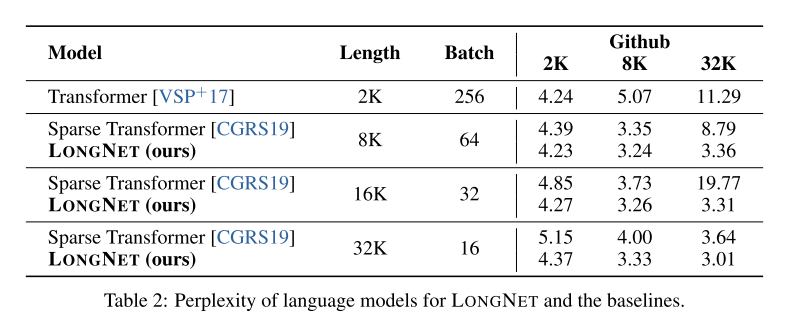
将LONGNET与原始Transformer和稀疏Transformer进行比较。架构之间的差异在于注意力层,而其他部分保持不变。将这些模型的序列长度从2K扩展到32K,同时减小批次大小以保持每批次的Token数量恒定。实验结果表明:
1)在训练期间增加序列长度通常会产生更好的语言模型;
2)推理中序列长度的外推不适用于长度远大于模型支持的情况;
3)LONGNET始终优于基线模型,证明了其在语言建模方面的有效性。
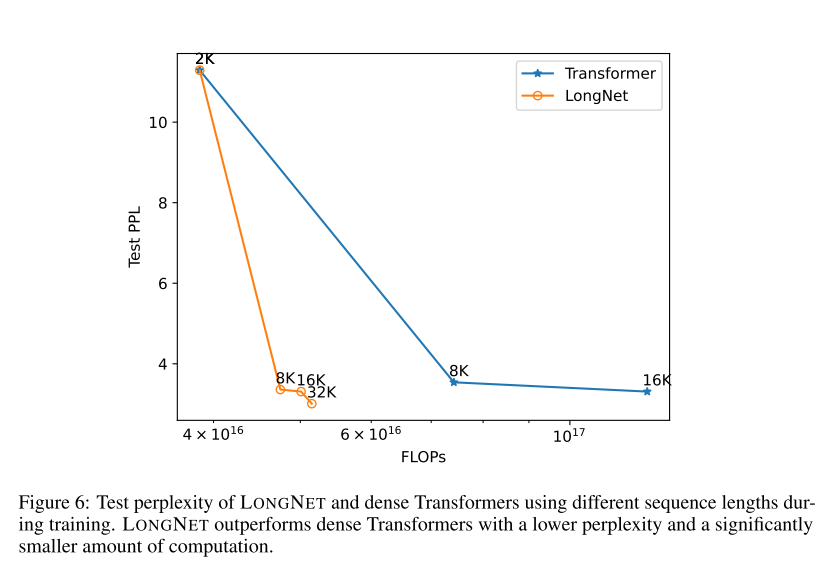
Scaling Curves of Sequence Length
下图绘制了原始transformer 和 LONGNET 的序列长度扩展曲线。作者通过计算矩阵乘法的总 flops 来估计计算量。结果表明LONGNET 可以更有效地扩展上下文长度,以较小的计算量实现较低的测试损失。
Scaling up Model Size
为了验证 LONGNET 是否仍然遵循类似的扩展规律,作者用不同的模型规模(从 1.25 亿到 27 亿个参数) 训练了一系列模型。27 亿的模型是用 300B 的 token 训练的,而其余的模型则用到了大约 400B 的 token。下图a部分为 LONGNET 关于计算的扩展曲线。作者在相同的测试集上计算了复杂度。这证明了 LONGNET 仍然可以遵循幂律。这也就意味着 dense Transformer 不是扩展语言模型的先决条件。LONGNET 可以提高模型的可扩展性和效率。
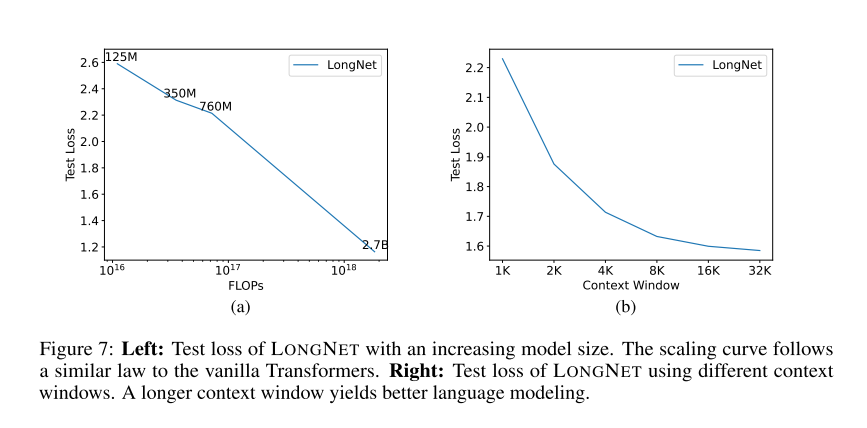
Long Context Prompting
作者保留了一段前缀(prefixes)作为 prompt,并测试其后缀(suffixes)的困惑度。并且逐渐将 prompt 从 2K 扩展到 32K。为了进行公平的比较,保持后缀的长度不变,而将前缀的长度增加到模型的最大长度。上图 (b) 报告了测试集上的结果。它表明,随着上下文窗口的增加,LONGNET 的测试损失逐渐减少。这证明了 LONGNET 在充分利用长语境来改进语言模型方面的优越性。