Longformer
Longformer是一种用来拓展模型在长序列建模的能力算法,它提出了一种时空复杂度同文本序列长度呈线性关系的Self-Attention,用以保证能够使得模型高效处理长文本。
Tranformer由于采用的是“全连接”型的注意力机制,在处理长文本时有着天然的劣势。因为每一个token都要与其他所有token进行交互。其注意力机制复杂度为 。而 Longformer 对Transformer的注意力机制进行了改进,使得时间复杂度降至,极大的节省模型在长文本任务中内存和时间的占用。
概述
Longformer对注意力机制的改进,具体来说:使每一个token只对固定窗口大小附近的token进行local attention(局部注意力)。并且Longformer针对具体的任务,在原有local attention的基础上增加了一种global attention(全局注意力)。
Longformer在两个字符级语言建模任务上都取得了SOTA的效果。并且作者用Longformer预训练RoBERTa,训练得到的语言模型在多个长文档任务上进行fine-tune后,性能全面超越RoBERTa
Longformer
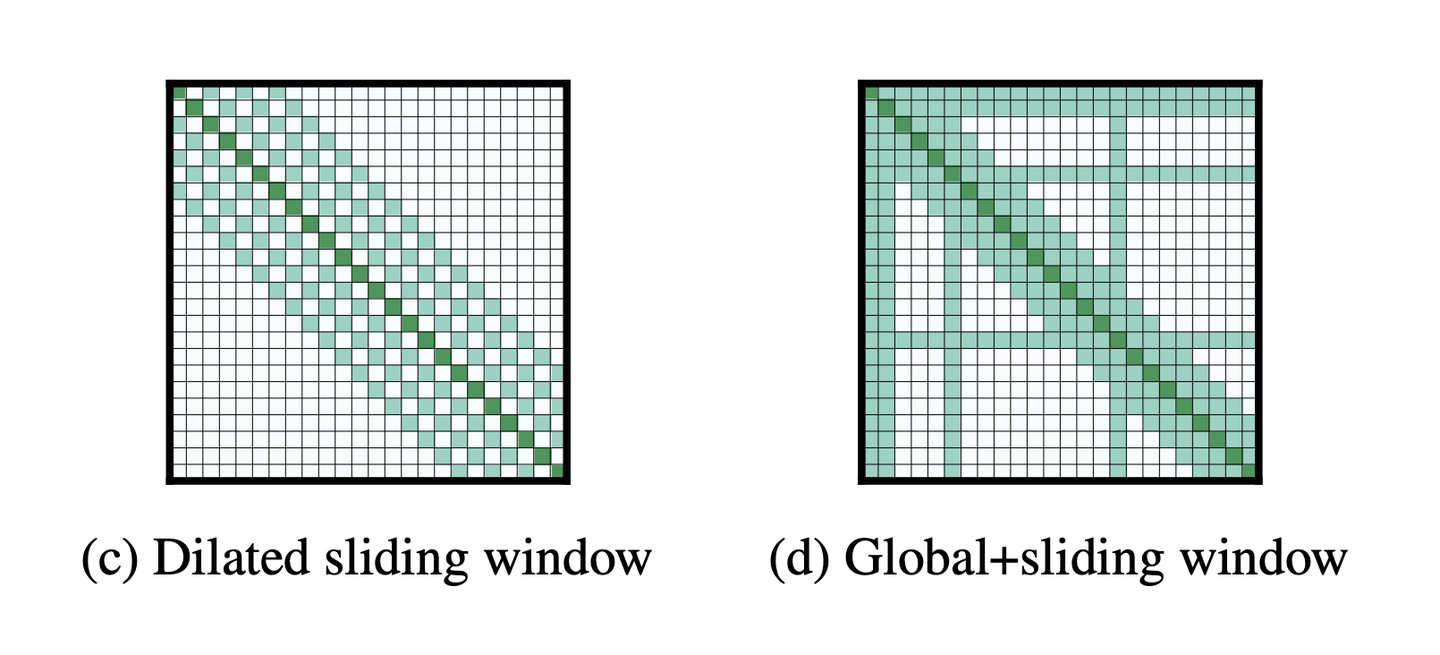
作者共提出了三种新的注意力模式,来降低传统注意力机制的复杂度,分别是滑窗机制(Sliding window attention)、膨胀滑窗机制(Dilated sliding window)、融合全局信息的滑窗机制(Dilated sliding window) 。下图展示了传统注意力机制(a)与这三种注意力模式(b,c,d)。
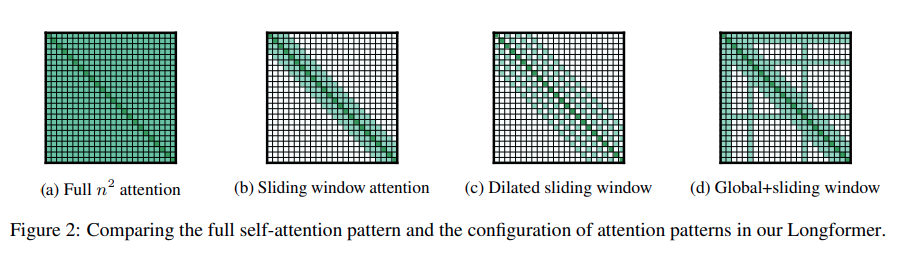
滑窗机制
滑动窗口的原理,设置一个大小为的窗口,对于每一个token,只对其附近的个token计算attention,复杂度为 ,其中 为文本的长度。
作者认为,根据应用任务的不同,可以对Transformer每一层施以不同的窗口大小,对模型表示能力可能有潜在帮助。
在论文中实验中,作者将窗口 设置为512,达到了Bert的输入token限制的大小。
膨胀滑窗机制
对每一个token进行编码时,普通的滑窗机制只能考虑到长度为 的上下文。作者进一步提出空洞滑窗机制,其做法借鉴了空洞卷积的思想,在不增加计算负荷的前提下,拓宽视野范围。在空洞滑窗中,被attented到的两个相邻token之间会存在大小为 的间隙,因此当计算到第 个token时(即图c中的第 行),此时视野范围可达到。论文实验表明,由于考虑了更加全面的上下文信息,空洞滑窗机制比普通的滑窗机制表现更佳。
融合全局信息的滑窗机制
从字面上就很好理解,即某些token采用滑窗机制,某些token采用全局注意力,而哪些oken获得全局注意力是根据具体任务来决定的,比如,在分类任务中会在[CLS]初添加一个全局注意力(即第一行和第一列全绿);而在问答任务上会对问题中的所有token添加全局注意力,如图d所示。
那么这种融合全局信息的滑窗Attention具体如何实现呢,我们先来回顾一下经典的Self-Attention,公式如下
即将原始的输入分别映射到了 $ Q,K,V$ 三个空间后进行attention计算,融合全局信息的滑窗机制涉及到两种Attention,分别将这两种attention映射到了两个独立的空间,即使用 来计算滑窗机制,使用来计算Global Attention。
实验结果
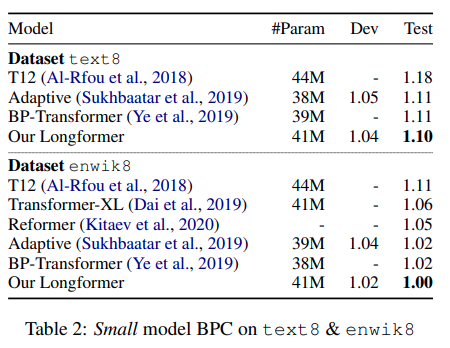
作者在text8和enwiki8两个字符级任务上对Longformer进行了实验。实验中每一层采用了不同的窗口大小,具体来说:底层使用较小的滑窗,以构建局部信息;越上层滑窗越大,以扩大感受野。训练时,理想状况当时是希望使用GPU所能承受最大的w ww和sequence length,但为了加快训练速度,作者采用的是多阶段训练法:从较短的序列长度和窗口大小开始,后续每个阶段将窗口大小和训练长度增加一倍,并将学习率减半。作者一共训练了5个阶段,第一个阶段sequence length是2048,最后一个阶段是23040
实验结果如下所示,Longformer在这两个数据集上皆达到了SOTA(注:测试指标为BPC,bits-per-character,BPC越小性能越好)
作者通过实验,对滑窗机制的设置进行了进一步的讨论。如下表所示:
表中第一组实验(前三行)讨论的是:如果transformer的不同层采用不同窗口大小,是否可以提高性能?实验结果表明,由底层至高层递增窗口大小,可提升性能;递减则反而性能降低。
第二组实验(后两行)是对膨胀滑窗机制的消融实验,证明了增加间隙后的滑窗机制,性能可以有小幅度提升

Longformer用于预训练
作者采用Longformer的方法在以下四个文档级语料上进行预训练,从而得到适于文档级NLP任务的语言模型。作者并没有完全从头预训练一个随机初始化的模型,而是以RoBERTa为基础,采用MLM(masked language modeling)的方法继续预训练。预训练时,每一层都采用固定的大小为512的滑动窗口,暂不添加global attention。为支持长文本,论文作者把position embedding扩展到了4096个。
预训练结束后,作者在多个文档级任务上进一步对预训练模型做fine-tuning。fine-tune时会根据任务增加global attention,同时设置两套映射矩阵,一套用于局部自注意力,另一套用于全局注意力。实验结果Longformer全面超越了RoBERTa

消融实验

参考文献
Longformer: The Long-Document Transformer (arxiv.org)