LMCache

想要大模型在通用性上获得更好的效果,就需要让大模型对更多的领域知识进行“补充”。
《Do Large Language Models Need a Content Delivery Network》论文提出了 KDN(Knowledge Delivery Network),简单来说就是对输入进行“缓存”,从而提升模型首个 Token 响应时间,并将 KDN 开源为 LMCache
概述
随着大模型(LLM, Large Language Model)的发展,使用规模和参数的持续扩大,尤其是在处理长上下文(long-context)请求时,LLM 推理面临两大核心性能瓶颈:
- 成本激增 —— 用户请求变得更加复杂与庞大,导致 GPU 资源消耗迅速攀升,从而引发推理成本成倍增长的问题;
- 延迟指标难以达标 —— 在保障用户体验的前提下,如何满足对“首个 Token 响应时间(TTFT, Time to First Token)与 Token 间响应时间(ITL, Inter-Token Latency)”的严格服务等级目标(SLOs),已成为技术落地的关键挑战之一。
为缓解上述情况,KV Cache应运而生。所谓 KV Cache就是预先计算新知识内容的 KV Cache,以便在后续相同知识输入时,KV Cache可以直接被 LLM 使用。
通过这种方式,KV Cache一旦生成,就可以供 LLM 重用,以便在后续输入请求使用已缓存的相同上下文时,跳过预填充阶段。当许多查询重用相同上下文时,KV Cache可以极大减少每个查询的延迟和计算开销,同时仍保留上下文学习的模块性,无需额外的计算开销来预填充知识文本。
本质上是一种用空间换时间的技术
作者在《Do Large Language Models Need a Content Delivery Network》论文中对这种“空间换时间”的技术指出了两个优点:
- KV Cache被大量重用。许多上下文,特别是长上下文,经常被不同查询和不同用户重用。这可以看作是 LLM 版本的帕累托法则:即 LLM 像人类一样,在 80% 的时间内使用 20% 的知识,这意味着知识被频繁重用。
- KV Cache大小的增加速度慢于预填充延迟。随着上下文增加,KV Cache大小线性增长,而预填充延迟超线性增长(由于注意力机制的存在)。随着 LLM 规模变大,更多计算将发生在前馈层,这不会影响 KV Cache大小。
然而目前的 KV Cache系统也存在一些局限性:
- KV Cache的存储空间有限:目前,许多服务仅使用可由单个 LLM 实例本地访问的 GPU/CPU 内存来存储 KV Cache。这种仅本地存储的方式极大地限制了可被存储和重用的 KV Cache量。例如,对于小型 LLM(Llama 34B),64 GB 的 CPU 内存只能存储 160 K Token 的 KV Cache。而将 KV Cache扩展到硬盘或远程服务器将显著限制其加载到 GPU 中的速度。
- 仅前缀的 KV Cache可重用:为了重用 KV Cache,大多数系统要求 KV Cache的文本必须是 LLM 输入的前缀。尽管 LLM 自然支持重用前缀的 KV Cache,但这种“仅共享前缀”的假设严重限制了其用例。例如,在 RAG+LLM 方法中,会在 LLM 中写入多个检索到的文本块,但这些重用的文本大多并非前缀。
- 在长上下文中缓存质量下降:随着更多文本作为上下文添加到输入中,LLM 捕获重要信息的能力可能降低,从而降低推理质量。因此,当 KV Cache被更多查询重复使用时,LLM 的输出质量会下降。
作者针对现有 KV Cache的局限性进行改进,并提出了一种新的 KV Cache系统——KDN。
KDN
作者认为,要解决当前 KV Cache存在的问题,需要一个独立的 KV Cache管理系统,该系统可以动态压缩、组合并修改 KV Cache,以优化其存储与交付,并在此基础上提升 LLM 推理效率。作者将这样的系统称为 KDN。如下图所示,KDN 的架构由三个主要模块组成:
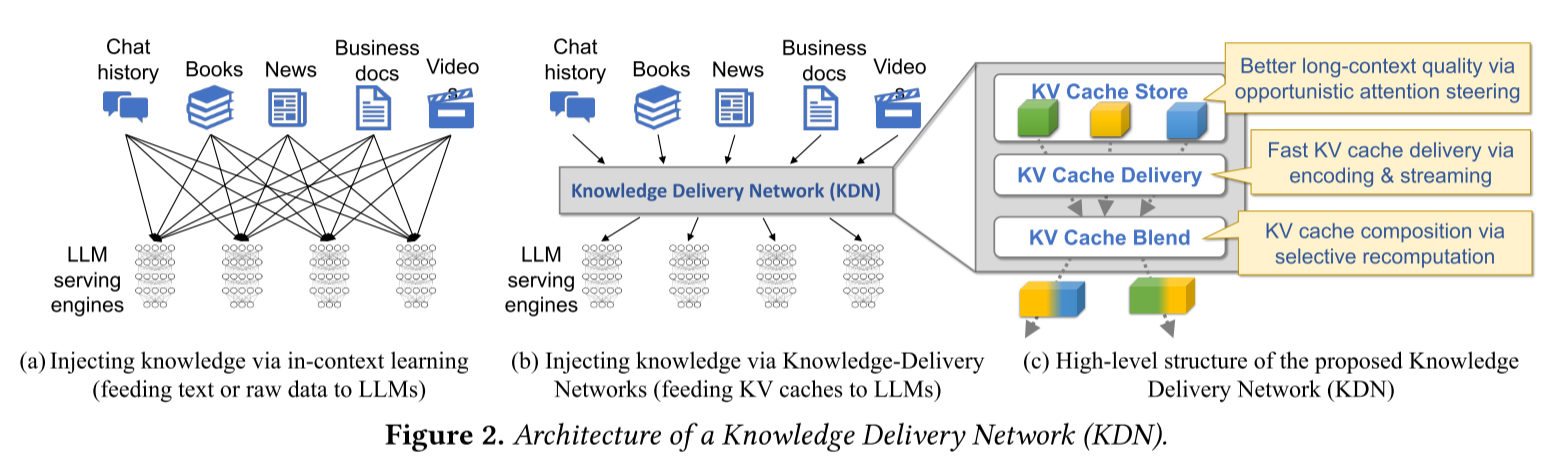
- KV Cache Store:存储模块负责存储文本及其可修改的 KV Cache,使其能够提升 LLM 推理质量。
- KV Cache Delivery:发送模块负责将压缩后的 KV Cache传输到运行 LLM 的服务器,并在 GPU 中解压以供 LLM 服务使用。
- KV Cache Blend:混合模块能够动态将多个不同文本的 KV Cache进行组合,然后将这些 KV Cache一起放入 LLM 上下文中。
现有的 LLM 服务系统将 KV Cache与 LLM 深度耦合。相比之下,KDN 的概念是将 KV Cache和 LLM 服务分离,实现了 KV Cache的存储、共享和使用,而无需与快速发展的 LLM 服务深度耦合。通过单独优化 KDN,它可以作为 LLM 服务生态系统的关键新系统模块(类似中间件)。
KDN 使 KV Cache管理与 LLM 服务解耦,这允许 LLM 服务专注于快速高效地进行推理,而 KDN 可以独立专注于 KV Cache相关的优化。
技术路线
KDN 本身的架构并不直接解决 KV Cache相关问题。KDN 只是解耦了 KV Cache与 LLM 服务之间的关联,目前针对 KV Cache的新兴研究工作可能逐步让每个模块实用化,从而提升 KDN 整体有效性。
-
KV Cache Delivery:最近的 KV Cache压缩技术使得在 GPU 和 CPU 内存之外,能够以更低成本存储并快速加载 KV Cache。例如,CacheGen[1] 通过量化并将其编码为二进制字符串来压缩 KV Cache;LLMLingua[2] 引入一个更小的语言模型识别并删除知识文本中的非必要标记,从而减少相应 KV Cache大小;H2O[3]根据推断过程中的重要性直接删除 KV Cache中的元素。通过结合上述技术,KV Cache的内存占用可减少 10 倍以上,大幅提升加载速度并降低存储成本。
-
KV Cache Blend:最近的一些工作也提高了 KV Cache的可组合性。例如,CacheBlend[4]通过重新计算 KV Cache之间的交叉注意力,可任意组合不同 KV Cache,其中重新计算仅需全文 10% 的计算;PromptCache[5]允许用户定义不同段的提示模板,使得每个段的 KV Cache可在不同位置重复使用,而不仅限于前缀。
-
Offline KV-cache editing:通过将 KV Cache管理与 LLM 服务引擎分离,KDN 为提高推理质量开辟了新可能性。最近的研究表明,如果适当修改 LLM 输入的注意力矩阵,推理质量可显著提升[6,7]。换句话说,当 KV Cache“存放”到 KDN 时,KDN 不仅存储它,还可通过修改 KV Cache并在下次检索时返回修改后的版本,从而主动影响 LLM 推理质量,而无需对输入提示的模型本身做任何更改。
-
Interface with LLM serving engines:目前,大多数 LLM 服务引擎(如 vLLM、HuggingFace TGI 和 SGLang)不支持将外部提供的 KV Cache注入为 LLM 输入的一部分。然而,它们内部的 KV Cache管理与模型推理高度耦合。部署 KDN 的一种方法是将其作为 LLM 引擎的子模块来增强每个引擎。然而,开发高性能 KDN 是一项艰巨任务,若每个引擎都独立维护和发展其 KDN,将导致大量冗余工程工作。为避免重复造轮子,LLM 服务引擎可通过两个 API 与独立的共享 KDN 提供者对接:
(1)LLM 将 KV Cache与相关文本一起存储到 KDN
(2)LLM 使用某些文本从 KDN 检索 KV Cache公开这些 API 是可行的,因为大多数主流 LLM 引擎均为开源。但仍存在一些设计问题:如何利用异构链路(如 NVLink、RDMA 或 PCIe)传输 KV Cache?API 能否与其他 LLM 函数(如分解预填充)共享?
实验
-
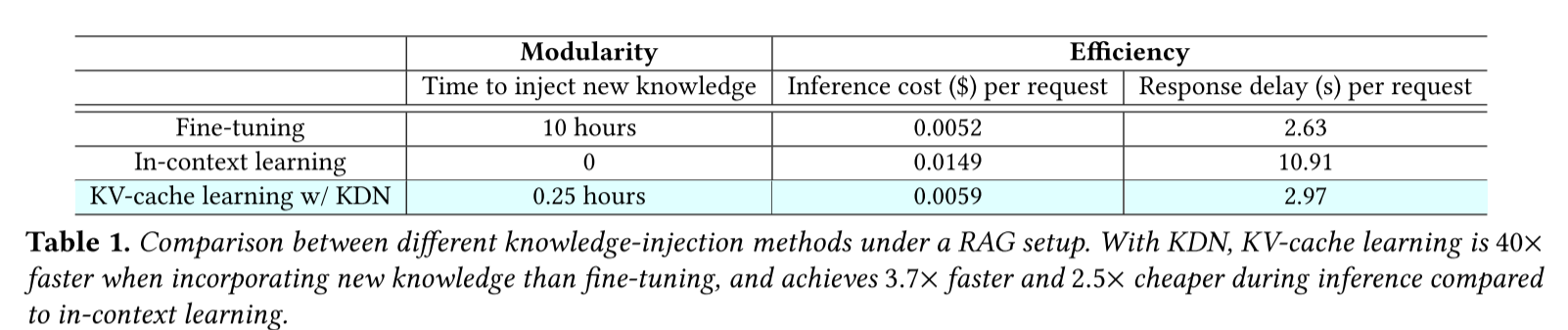
使用 KDN,在注入新知识时比微调快 40 倍,与上下文学习相比,推理时间降低 3.7 倍,速度提升 2.5 倍。
-
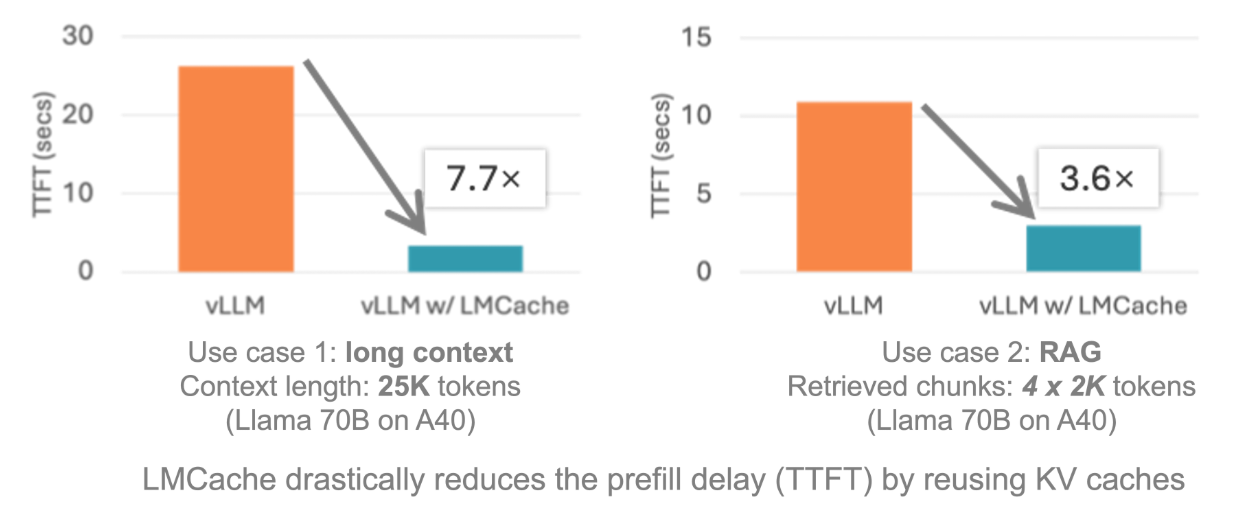
在 32 K 上下文的多轮对话场景中,LMCache 的 TTFT(首 Token 延迟)从 1.8 秒降至 0.4 秒,GPU 利用率下降 40%。
使用
- 下载库
git clone https://github.com/LMCache/LMCache.git
cd LMCache pip install -e . --no-cache-dir
- 启动 vLLM 并挂载 LMCache
python -m vllm.entrypoints.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--kv-transfer-config '{"kv_connector": "lmcacheconnector"}' \
--max-model-len 128000 # 支持长上下文
总结
简而言之,该论文的创新性为:
- 将知识管理(以 KV Cache的形式)与 LLM 服务引擎之间的解耦
- 提出了知识交付网络(KDN)作为新的 LLM 系统组件,并利用最新研究优化基于 KV Cache的知识注入效率(速度与成本)
参考文献
[1] Yuhan Liu, Hanchen Li, Kuntai Du, Jiayi Yao, Yihua Cheng, Yuyang Huang, Shan Lu, Michael Maire, Henry Hoffmann, Ari Holtzman, et al. Cachegen: Fast context loading for language model applications. arXiv preprint arXiv:2310.07240, 2023.
[2] Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. arXiv preprint arXiv:2310.05736, 2023.
[3] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Re, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. In Workshop on Efficient Systems for Foundation Models @ICML2023, 2023.
[4] Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. Cacheblend: Fast large language model serving with cached knowledge fusion. arXiv preprint arXiv:2405.16444, 2024.
[5] In Gim, Guojun Chen, Seung seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference, 2023.
[6] Anonymous. Model tells itself where to attend: Faithfulness meetsautomatic attention steering. In Submitted to ACL Rolling Review June 2024, 2024. under review.
[7] Qingru Zhang, Chandan Singh, Liyuan Liu, Xiaodong Liu, Bin Yu, Jianfeng Gao, and Tuo Zhao. Tell your model where to attend: Posthoc attention steering for llms. arXiv preprint arXiv:2311.02262, 2023.
[8] [2409.13761] Do Large Language Models Need a Content Delivery Network?
[9] LMCache/LMCache: Supercharge Your LLM with the Fastest KV Cache Layer