Less is More for Long Document Summary Evaluation by LLMs

这篇文章给了我们一种如何在自己研究的领域去"蹭"大模型热度的思路
摘要:
大语言模型(LLM)在自动摘要评估任务有良好的性能,但它们因为有着高额的计算成本和关键句子丢失等问题,模型经常忽视长文本中的重要信息。为了解决这些问题,该文介绍了一种新的方法,首先提取然后评估,它涉及到从长的源文本中提取关键句子,然后通过prompt LLM对抽取的句子进行评估。结果表明,该方法不仅显着降低了计算成本,但也表现与人类的评价较高的相关性。此外,作者还提供了对长文本抽取最佳文档长度和句子抽取方法的建议,为基于LLM的文本生成评估的成本效益更高且更准确的方法的发展做出了贡献。
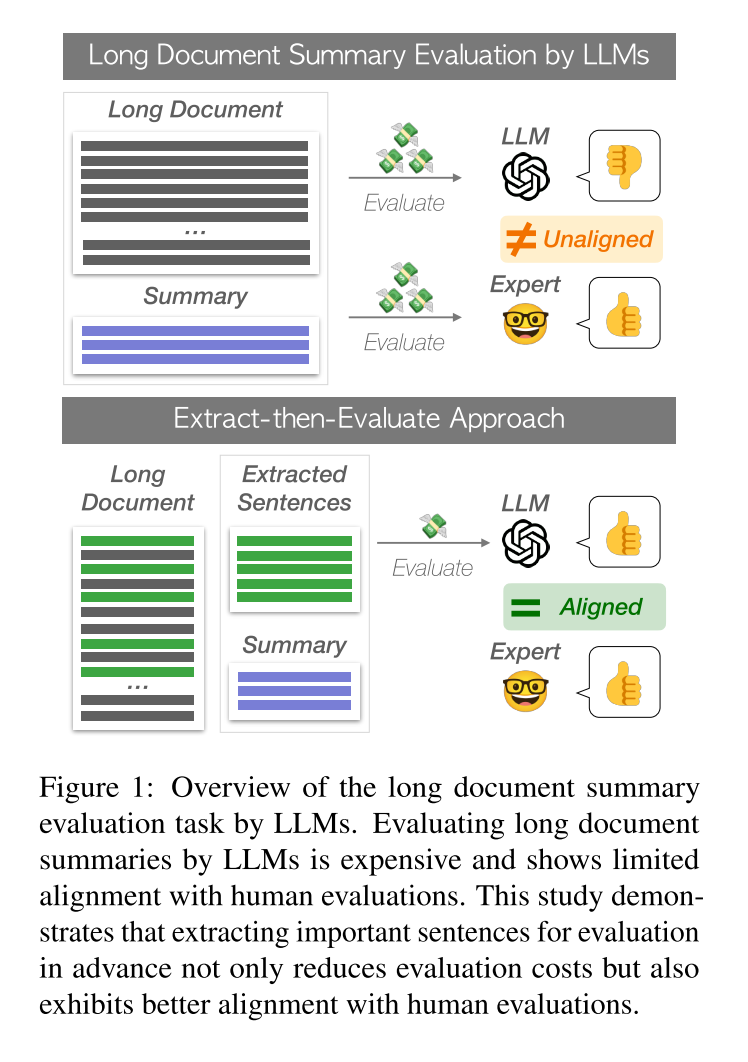
方法
摘要评价指标为模型生成的摘要 分配一个评分 。评价指标与人工判断得分 之间的相关性越高,评估指标就被认为越好。为了分配评分 ,现有研究使用参考摘要 或输入文档 ,以及生成的摘要 。
为了使用LLM作为评估器,通常将模型生成的摘要和源文档 作为输入。
但该文提出的提取-然后评估方法包括两个步骤来使用LLM,如下图所示:
- 从长篇源文档 中提取重要的句子进行摘要评估,直到达到预定义的长度 ,并构建一个短但信息密集的文档 。
- 通过prompt LLMs评估摘要 的质量。设计一个prompt可以将提取的源文档 和摘要作为输入,并生成一个评分标度 作为输出。要提取句子,作者考虑了以下方法:
- LEAD: 提取文本中前N个句子
- ROUGE: 使用模型生成的摘要中有最大ROUGE得分的源文本句子
- BERTScore: 和ROUGE一样,只不过是在BERTScore评价指标中
- NLI: 使用NLI模型提取作为前提的句子,这些句子在生成的摘要中被分类成抽取或不抽取,直到抽取句子达到N个字。这个过程旨在提取与正在评估的摘要在语义上相关的句子。
在所有方法中,原始顺序被保留,并且仅提取完整的句子。
实验
作者使用了GPT-4作为评估器,在arXiv、PubMed、GovReport和SQuALITY上进行了实验,对于句子提取,分别用128、256、512、768、1024、1536、2048和4096作为提取的源文档的长度限制进行实验。
结果
1.以1024作为抽取句子的长度效果最好
2.以ROUGE作为抽取策略效果最好
3.经过抽取后再评估,效果更好

总结
-
这篇文章在生成摘要评估的领域采用GPT4作为评估器,分为抽取+评估两阶段。
-
prompt+LLM在NLP任务中具有发展潜力(好蹭热点),目前绝大数NLP的文章都涉及到LLM,主要分为三个方向:
- 1.提出了大模型 (大牛实验室)
- 2.提出了一种对大模型的分析(优缺点、新的微调方法等)
- 3.使用prompt 结合大模型应用到自己任务(最常见)