KV Cache
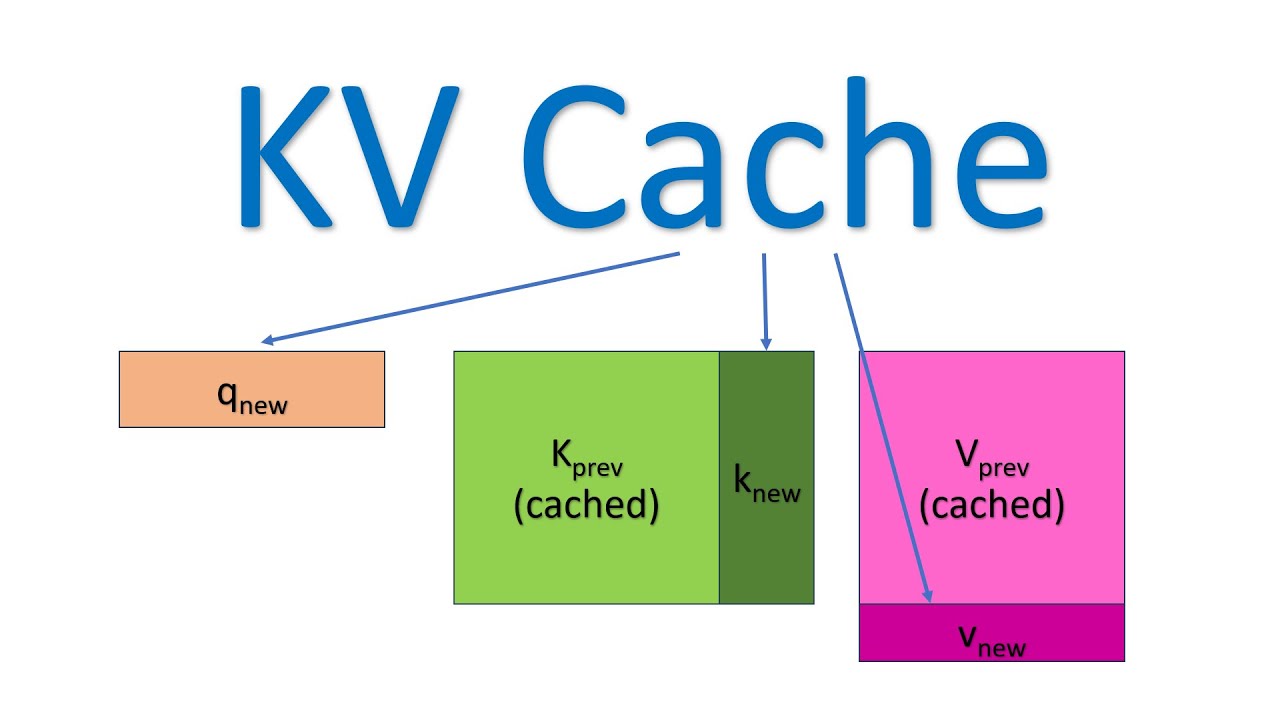
KV Cache是一种针对Transformer-Decoder部分的注意力层的优化技术,其原理是通过缓存之前生成的KV值,提高模型的推理性能。
什么是 KV Cache
对于包含有Transformer-Decoder部分的模型(可以是Decoder-Encoder,Only Decoder),模型的推理过程如下:
给定一个输入文本,模型会根据输入的文本,开始一个token一个 token 的输出回答,每一个 token 的输出都依赖于之前的输出,直到输出终止 token。
如下图例子所示:
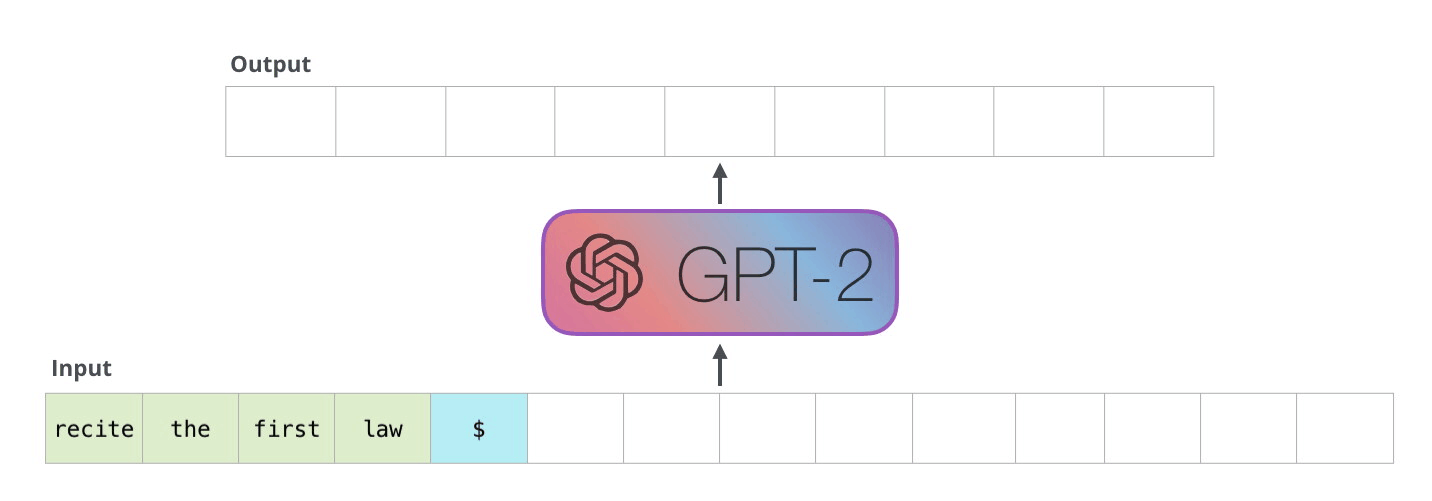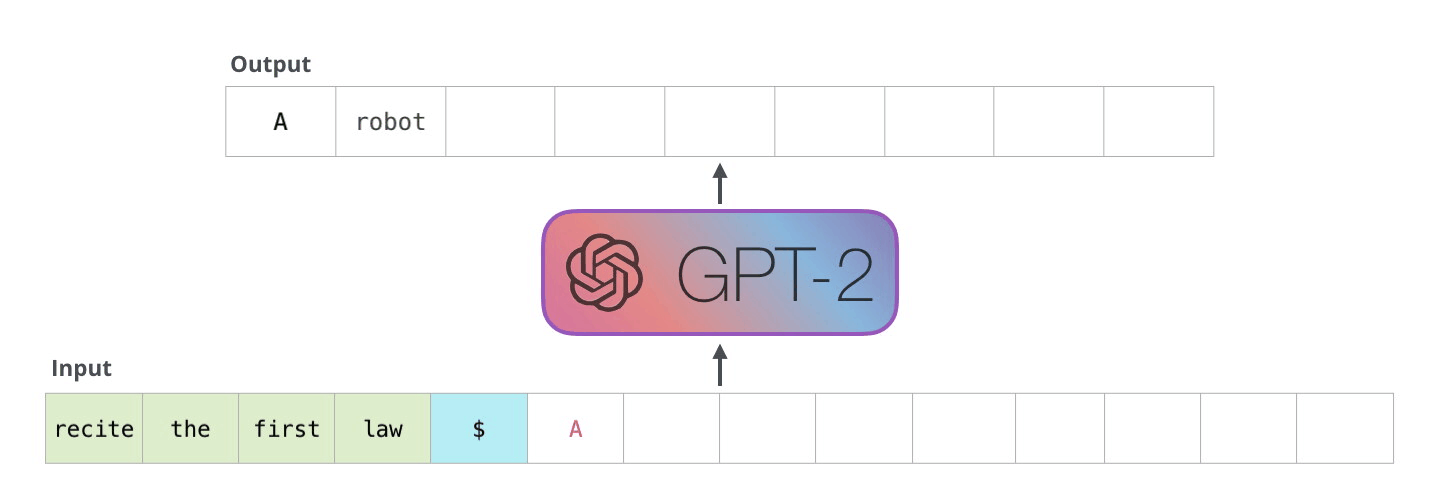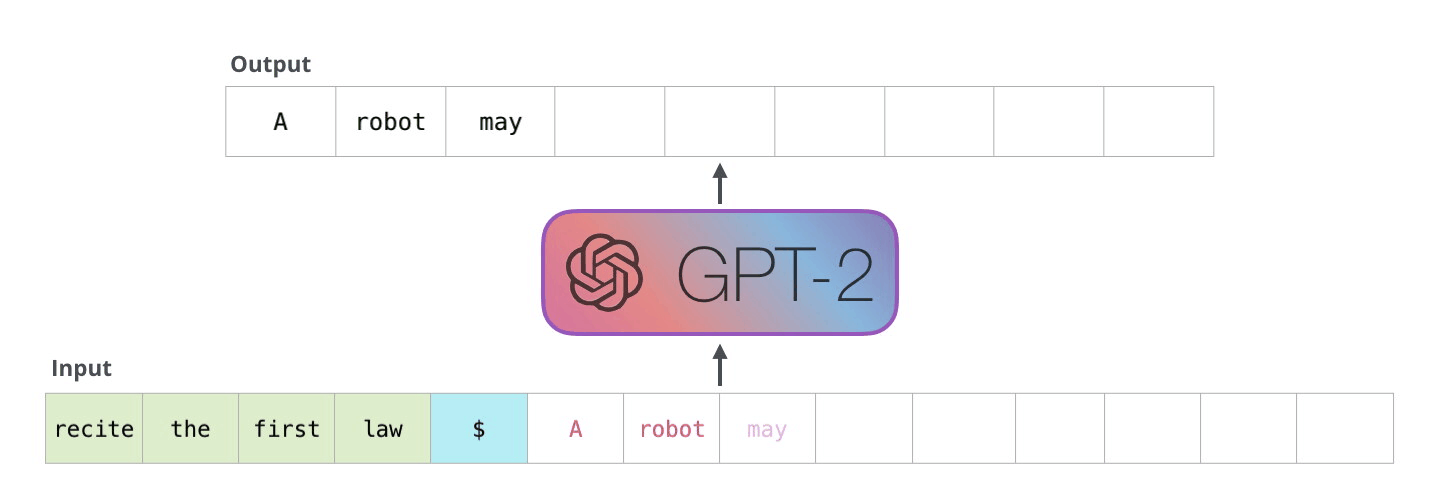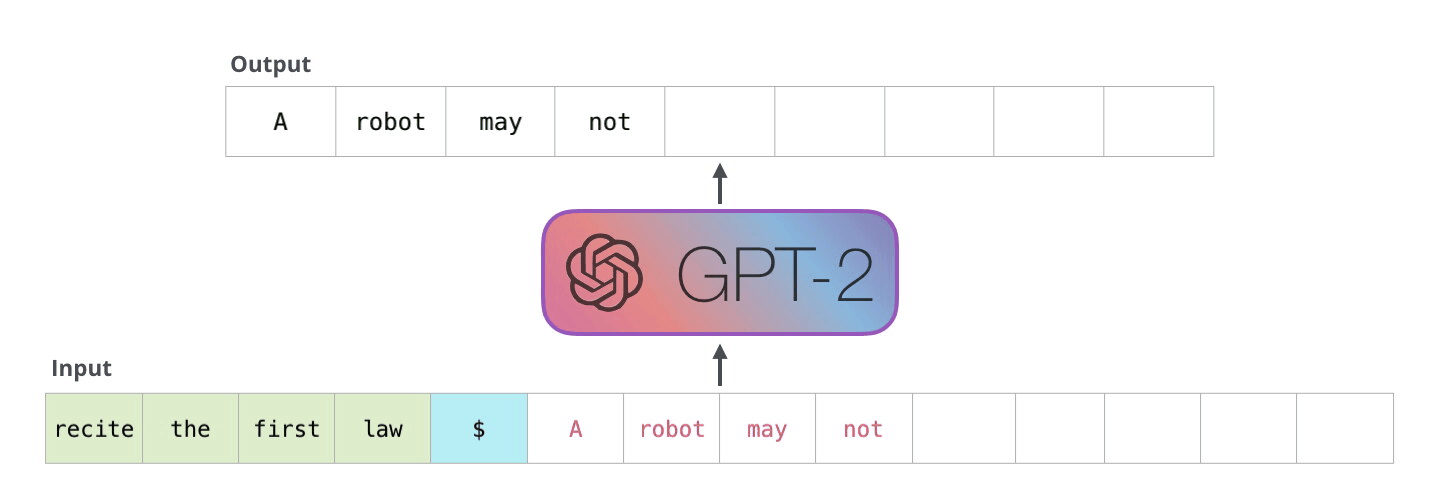
上述过程的模型,我们也称之为自回归模型
在自回归模型中,因为模型一次只能生成一个token,而且每次新的预测都依赖于之前的上下文。这意味着,要预测第1000个token,你需要用到前999个token的信息。
这通常涉及到对这些token的表示进行一系列矩阵乘法运算,Transformer原始的计算过程是在每一次计算token的时候,都得计算重新之前token的注意力信息。如下图所示:
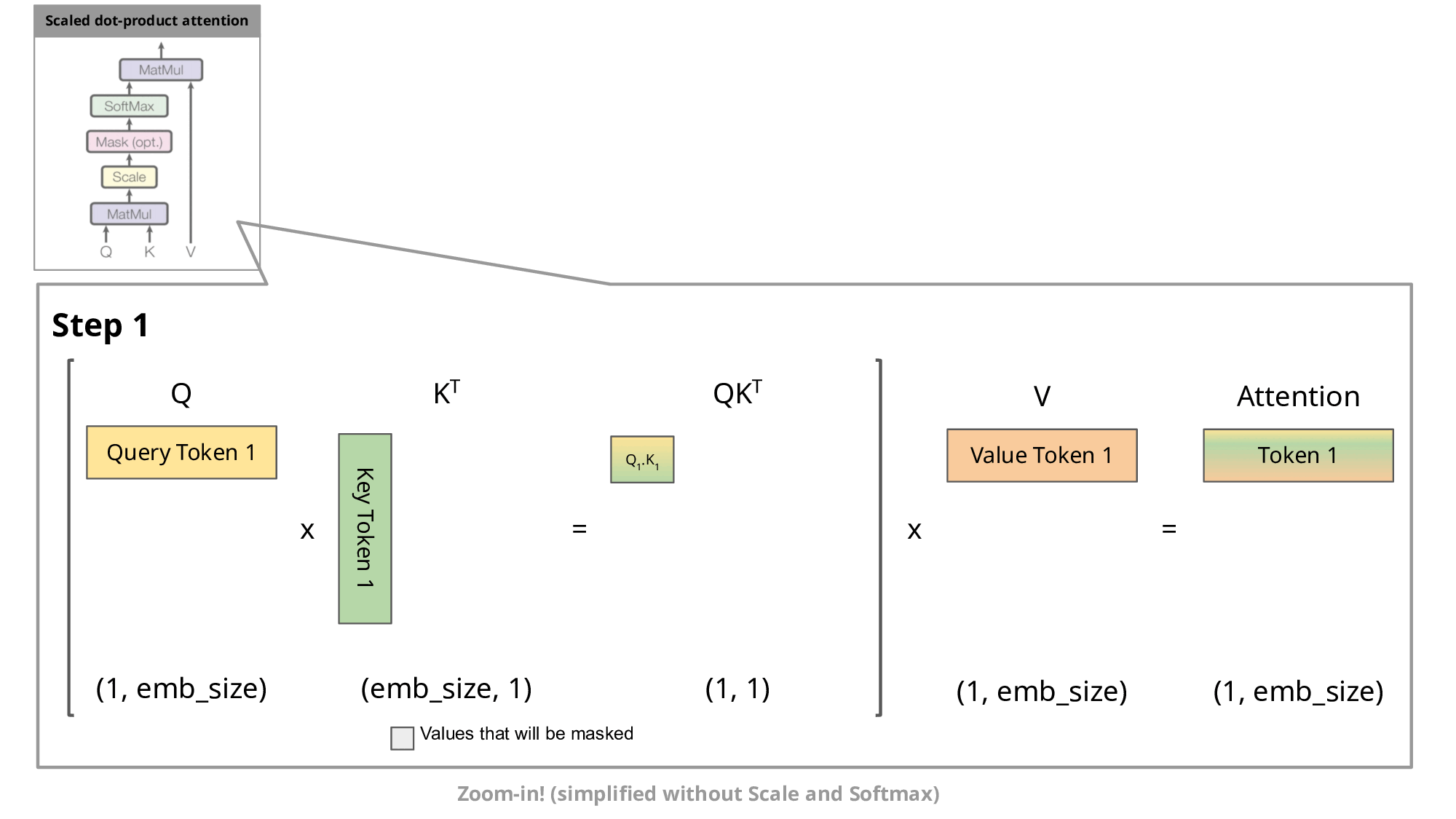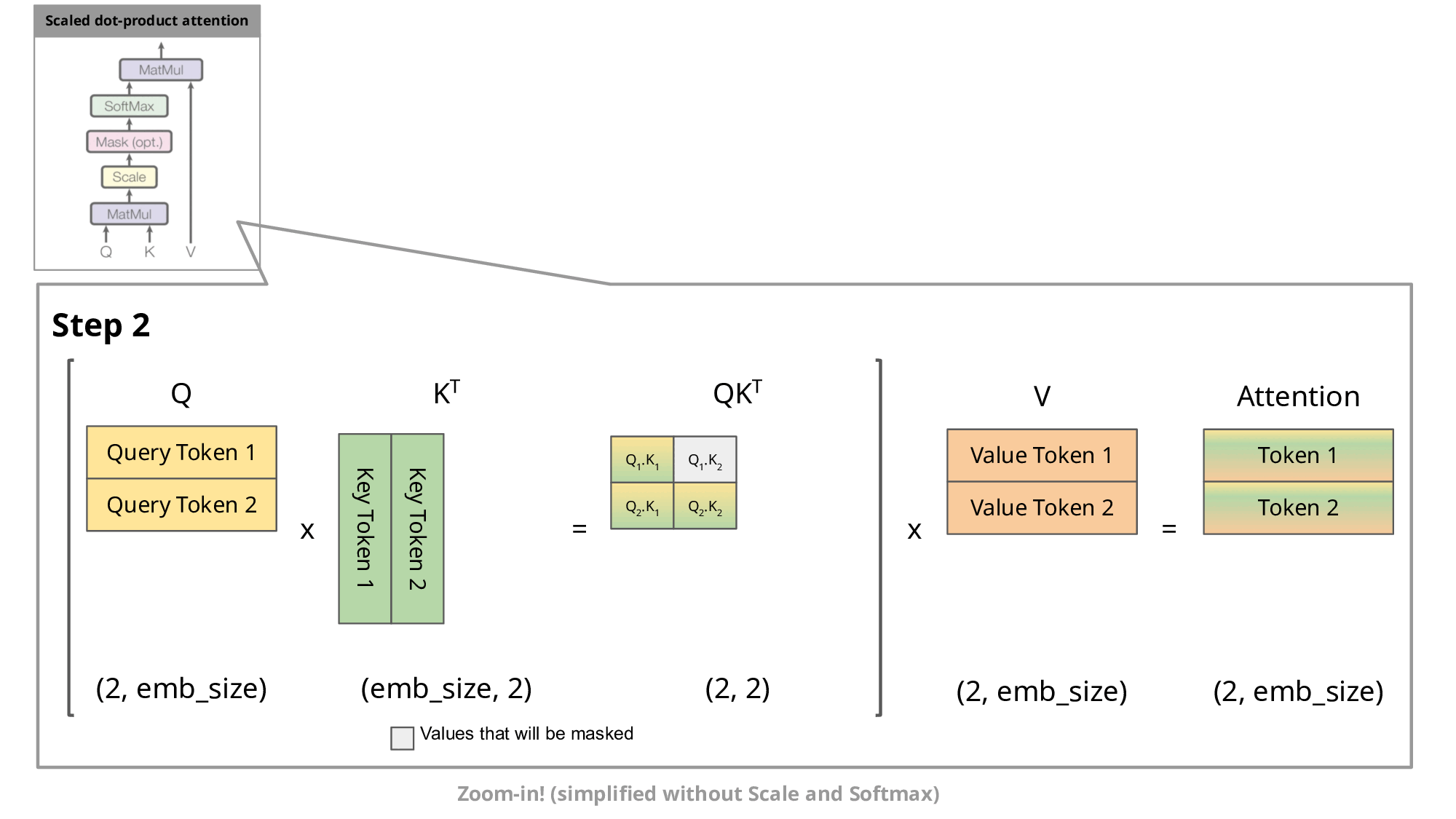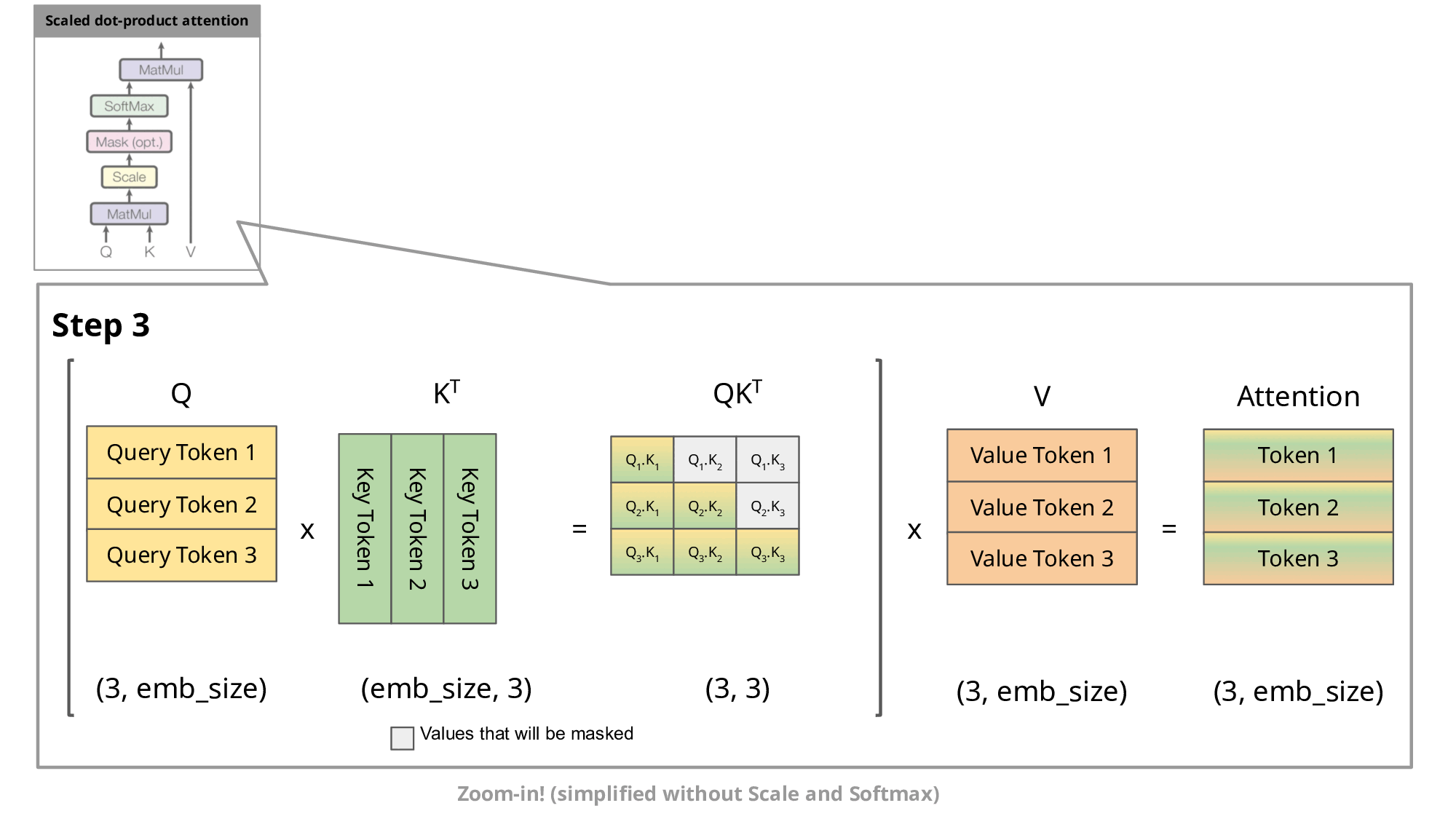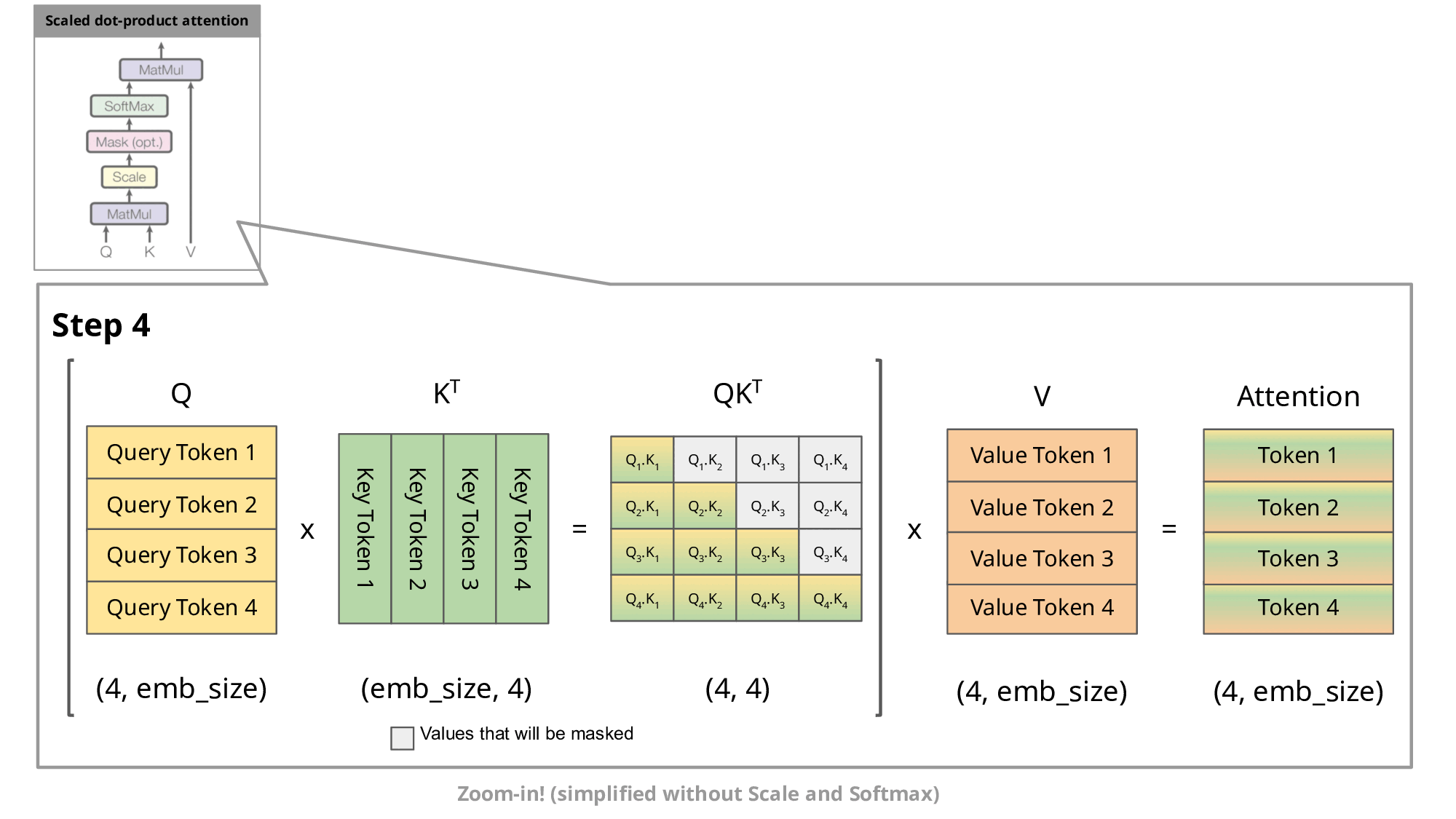
KV cache就是在这里发挥作用,通过存储之前K , V的计算结果,并在接下来的token生成时复用这些结果,从而避免重复计算,提高推理效率。如下图第二部分所示:
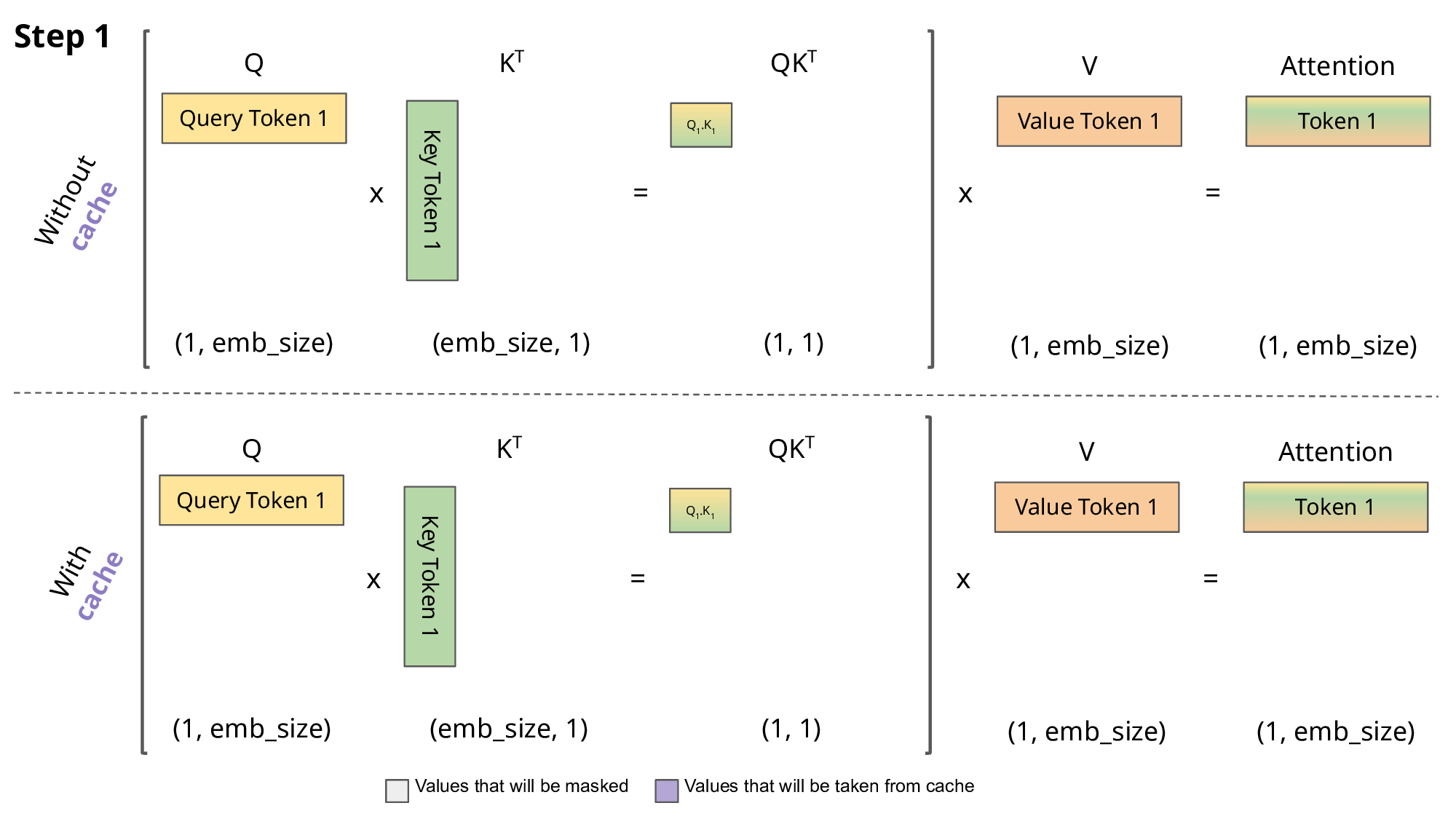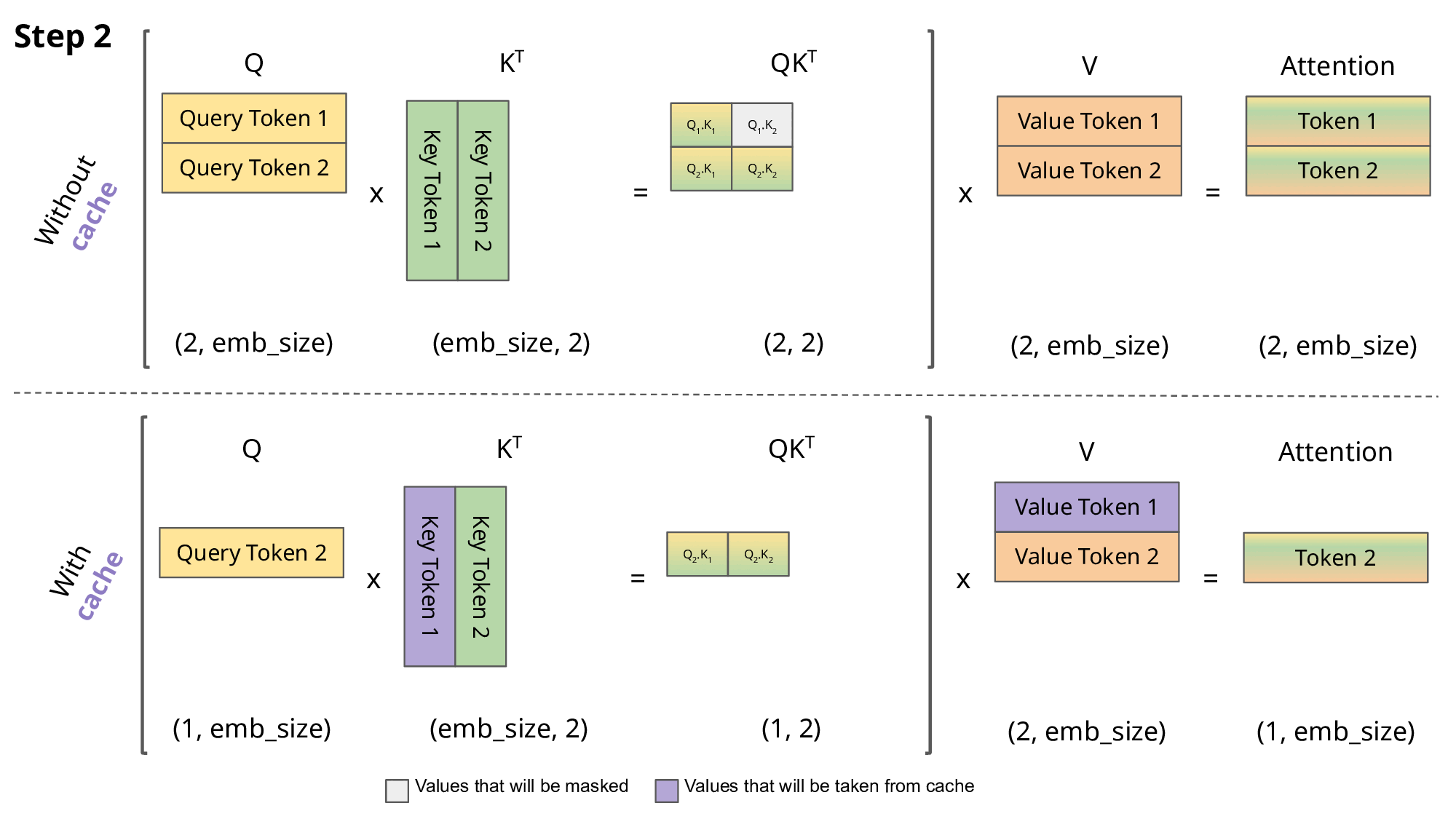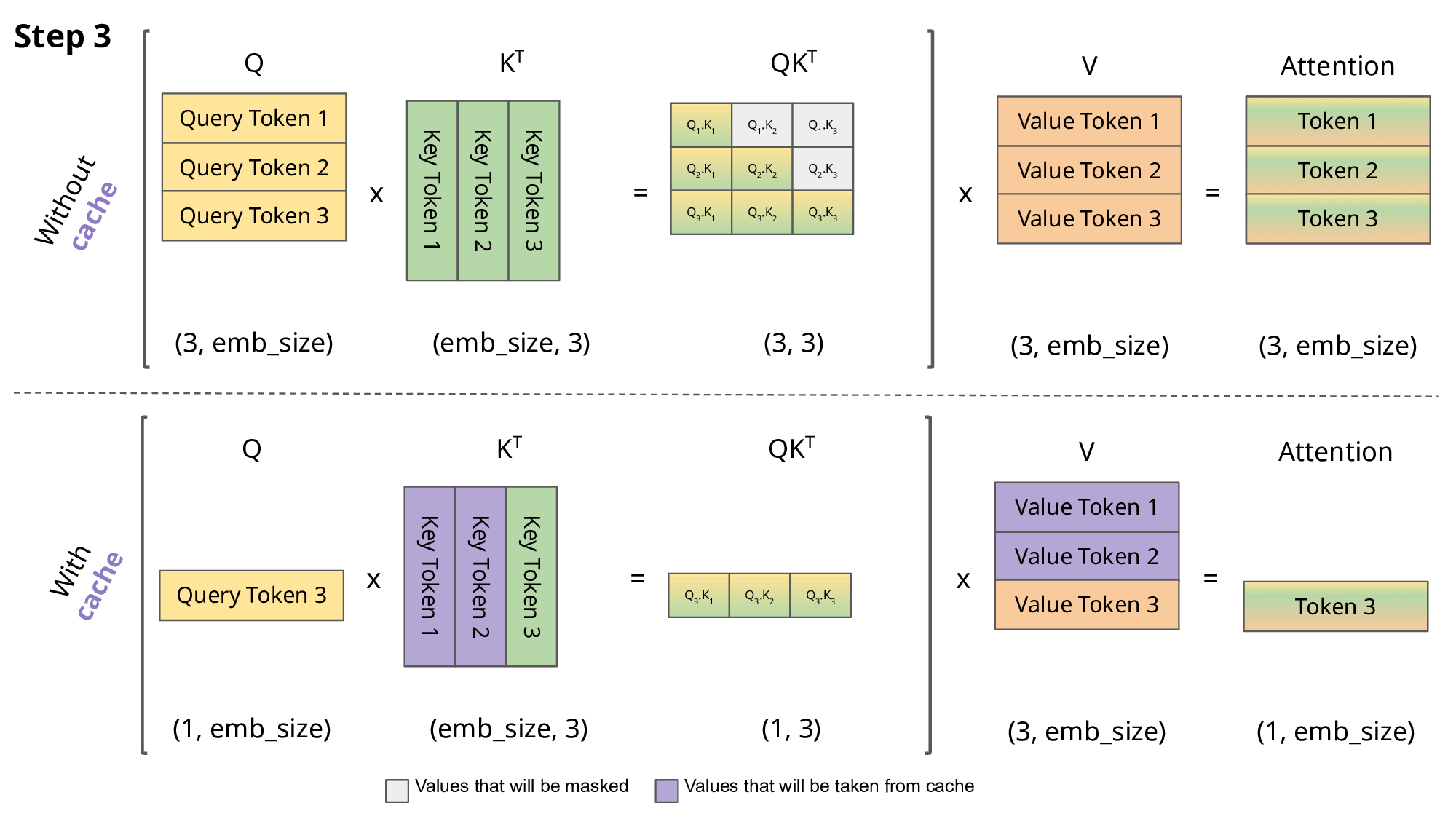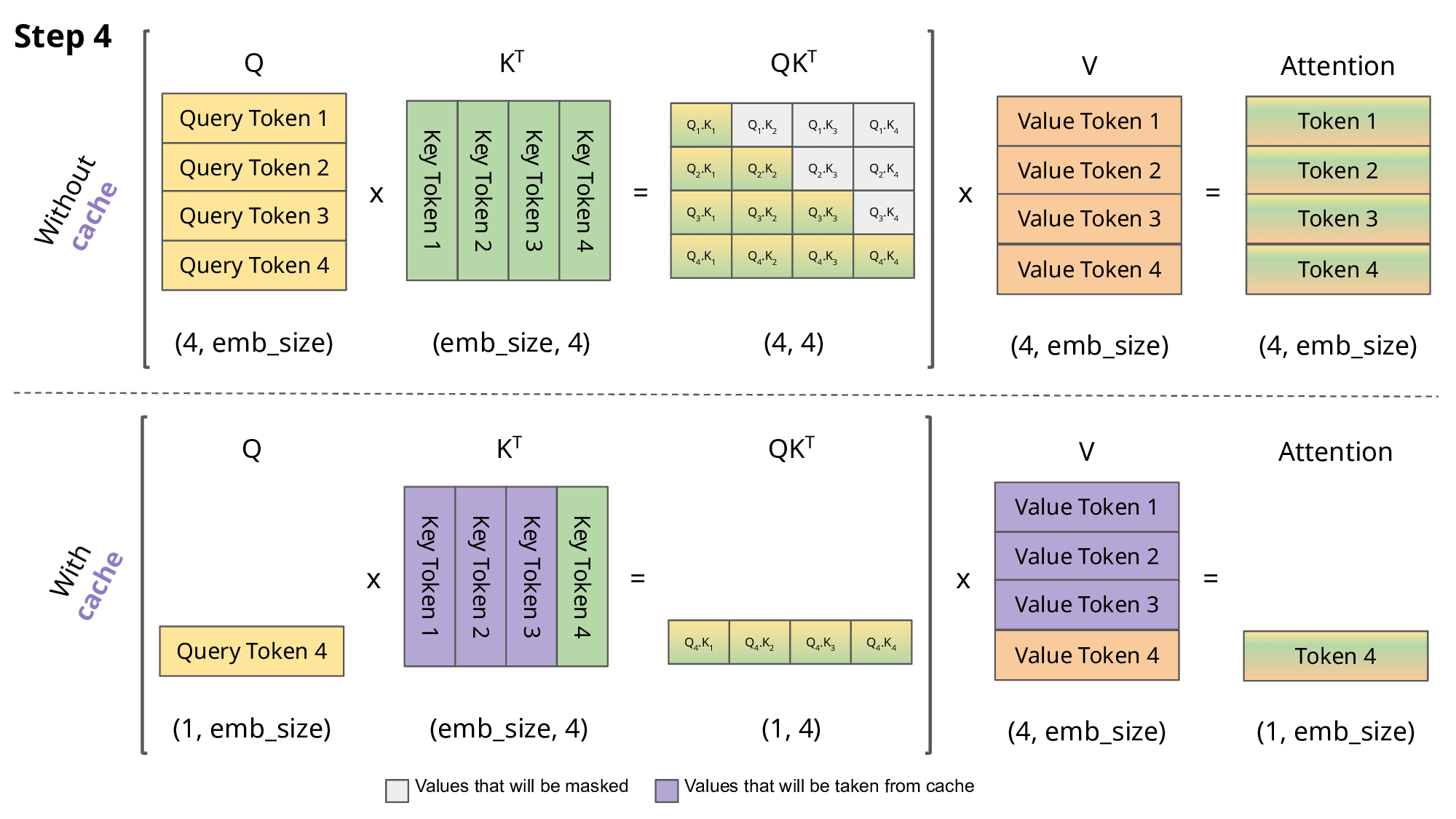
需要注意的是,KV cache只在多个token生成步骤中发生,并且仅在decoder部分进行。像BERT这样的encoder only模型,并不是生成式模型,因此不涉及KV cache。
当然,我们也可以用代码测试一下,使用了KV Cache后模型推理速度提升了多少
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("sshleifer/tiny-gpt2")
model = AutoModelForCausalLM.from_pretrained("sshleifer/tiny-gpt2").to(device)
for use_cache in (True, False):
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")
测试结果如下:
with KV caching: 2.088 +- 0.715 seconds
without KV caching: 18.835 +- 12.523 seconds
快了大约 9.02 倍!
为什么Q不用Cache
正常情况下,Transformer结构的Attention的计算公式步骤如下:
其中表示加上了masked的注意力,表示进行了softmax计算,那么最后的结果如下:
其中表示Attention的第一行,表示Attention的第二行。
因此,在Attention的每一步中,其实只需要根据计算 就可以,之前已经计算的Attention完全不需要重新计算。但是 K 和 V 是全程参与计算的,所以这里我们需要把每一步的 K,V 缓存起来。而Q只与当前一步计算有关,所以不需要也不用去缓存Q
KV Cache存在的问题
由于KV Cache思想是以空间换时间,那么显而易见的是KV Cache所带来模型占用显存的增加。
假设输入序列的长度为 ,输出序列的长度为 ,transformer层数为,隐藏层维度$ h [b, head_num, , head_dim]$,, 峰值kv_seq_len为 ,,以float16来保存KV cache,那么KV cache的峰值显存占用大小为 。这里第一个 2 表示 K/V cache,第二个2表示float16占 2 个 bytes。
以GPT3-175B为例,对比KV cache与模型参数占用显存的大小。模型配置如下:
| 模型名 | 参数量 | 层数 | 隐藏层维度 | 注意力头数 |
|---|---|---|---|---|
| GPT-3 | 175B | 96 | 12288 | 96 |
GPT3 模型占用显存大小为350GB。假设批次大小 ,输入序列长度$s=512 n=32 $,则KV cache 峰值占用显存为 ,大约是模型参数显存的0.5倍。
优化KV Cache 的几种方法
MHA
MHA(Multi-Head Attention)也就是Transformer原始的多头注意力机制,其思想是将多个独立的注意力机制进行拼接,假设输入的行向量为,其中有维。那么MHA的表现形式如下:
其中, 表示多头注意力后的结果,分为了个注意力头,每个头独立计算然后进行拼接,,这里省略了Attention矩阵的缩放因子,实践上,每个头里的维度一般为,LLAMA2-7b有,,每个头里的维度为128,LLAMA2-70b则是,,每个头里的维度为128。
MQA
MQA,即“Multi-Query Attention”,是减少KV Cache的一次非常朴素的尝试,首次提出自《Fast Transformer Decoding: One Write-Head is All You Need》,这已经是2019年的论文了,这也意味着早在LLM火热之前,减少KV Cache就已经是研究人员非常关注的一个课题了。
MQA的思路很简单,直接让所有Attention Head共享同一个K、V。
使用 MQA 的模型包括 PaLM、Gemini 等。很明显,MQA 直接将 KV Cache 减少到了原来的 。
效果方面,目前看来大部分任务的损失都比较有限。
GQA
有人担心 MQA 对 KV Cache 的压缩太严重,以至于会影响模型的学习效率以及最终效果。为此,一个 MHA 与 MQA 之间的过渡版本 GQA(Grouped-Query Attention)应运而生,出自 2023 年 Google 的论文 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints。
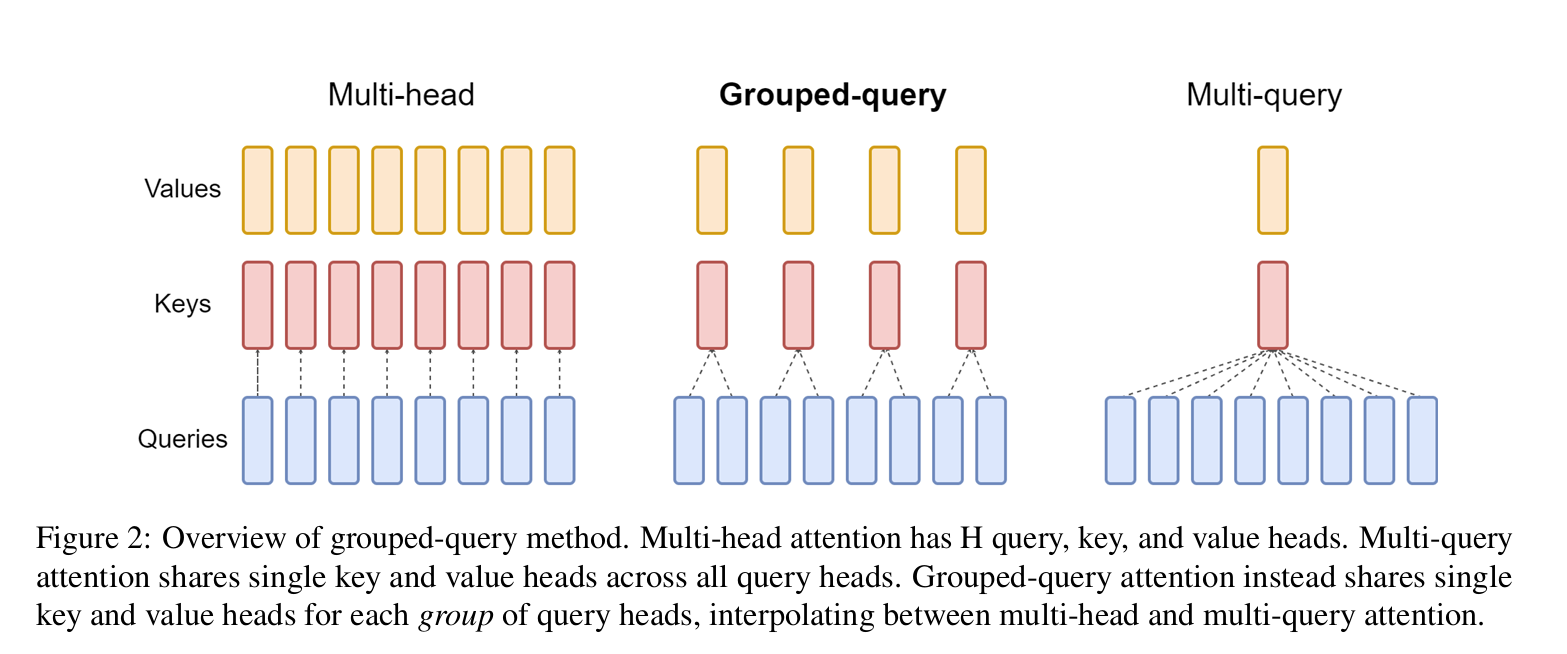
GQA的思想也很朴素,它就是将所有Head分为个组(可以整除),每组共享同一对K、V用数学公式表示为
其中这里的是是向上取整符号。GQA 提供了 MHA 到 MQA 的自然过渡。当时就是MHA,时就是MQA,当时,它只将KV Cache压缩到,压缩率不如MQA,但同时也提供了更大的自由度,效果上更有保证。GQA最知名的使用者,大概是Meta开源的LLAMA2-70B,以及LLAMA3全系列,此外使用GQA的模型还有TigerBot、DeepSeek-V1、Yi、ChatGLM2、ChatGLM3等,相比使用MQA的模型更多
MLA
随着今年DeepSeek的爆火,DeepSeek所提出的MLA,也正是该模型便宜的关键技术之一。
MLA(Multi-head Latent Attention)是对GQA的改进。其核心是对键(Keys)和值(Values)进行低秩联合压缩,生成压缩的潜在向量,以降低推理阶段的KV缓存。并结合了RoPE,提升了模型的外推能力,进一步提升了模型的效果。
- MLA 通过低秩压缩显著降低了 KV 缓存的大小,在 DeepSeek-V2 中,KV 缓存减少了 93.3%,推理吞吐量提升了 576%。
- 通过部分 RoPE 保留和低秩近似,MLA 能够高效地将任意基于 MHA/GQA 的大语言模型迁移到 MLA 架构,仅需使用少量预训练数据进行微调。