Hyper Connections 是对残差网络(Residual Connections) 的一种改进设计,其核心在于引入了可学习的深度连接与宽度连接。该方法在几乎不增加计算量和参数量的前提下,能够带来显著的性能提升,且具有极高的普适性——无论是密集连接(Dense)还是混合专家模型(MoE),无论是视觉任务还是文本模态,均能取得收益。特别是在大语言模型(LLMs)的预训练中,收敛速度最高可提升0.8倍[1]。
概述
Hyper Connections 旨在解决残差网络中前归一化(Pre-Norm)与后归一化(Post-Norm) 之间存在的跷跷板效应——即表示崩溃与梯度消失之间的矛盾。该方法允许网络动态调整不同深度特征的连接强度,甚至实现对网络层的重排列。
残差网络主要有两种变体:
前归一化(Pre-Norm):训练过程更稳定:
xt+1=xt+Ft(Norm(xt))
随着迭代进行,当 xt 的幅值逐渐增大时,xt+1 会与初始输入 x0 高度相似,导致模型逐渐丧失学习复杂变换的能力,从而引发表示崩溃。然而,由于梯度不经过归一化层的缩放,反向传播路径更接近恒等映射,因此梯度回传较为顺畅,能有效缓解梯度消失问题。
后归一化(Post-Norm):训练效果通常更好:
xt+1=Norm(xt+Ft(xt))
其中 F(x) 的输出未经归一化直接加入,保留了不同层之间的幅值差异,因此模型能更充分地学习特征。但正因如此,梯度的幅值分布容易被改变,导致深层梯度呈指数级衰减,进而引发梯度消失问题。
在 Transformer 中,式中的 Norm 主要指 Layer Normalization,但在其他模型中,它也可以是 Batch Normalization、Instance Normalization 等,相关结论本质上是通用的。
两种方法各有优势,那怎么做才能将给自的优点结合起来呢?
有的~~
Hyper Connections 的核心思想在于:通过动态调整不同层之间的连接权重,弥补残差连接在梯度消失与表示崩溃之间的跷跷板效应。实验表明,该方法不仅训练过程比前归一化更稳定,还能有效降低层间相似度,并扩大相似度的动态范围,从而模拟出后归一化的良好训练特性。
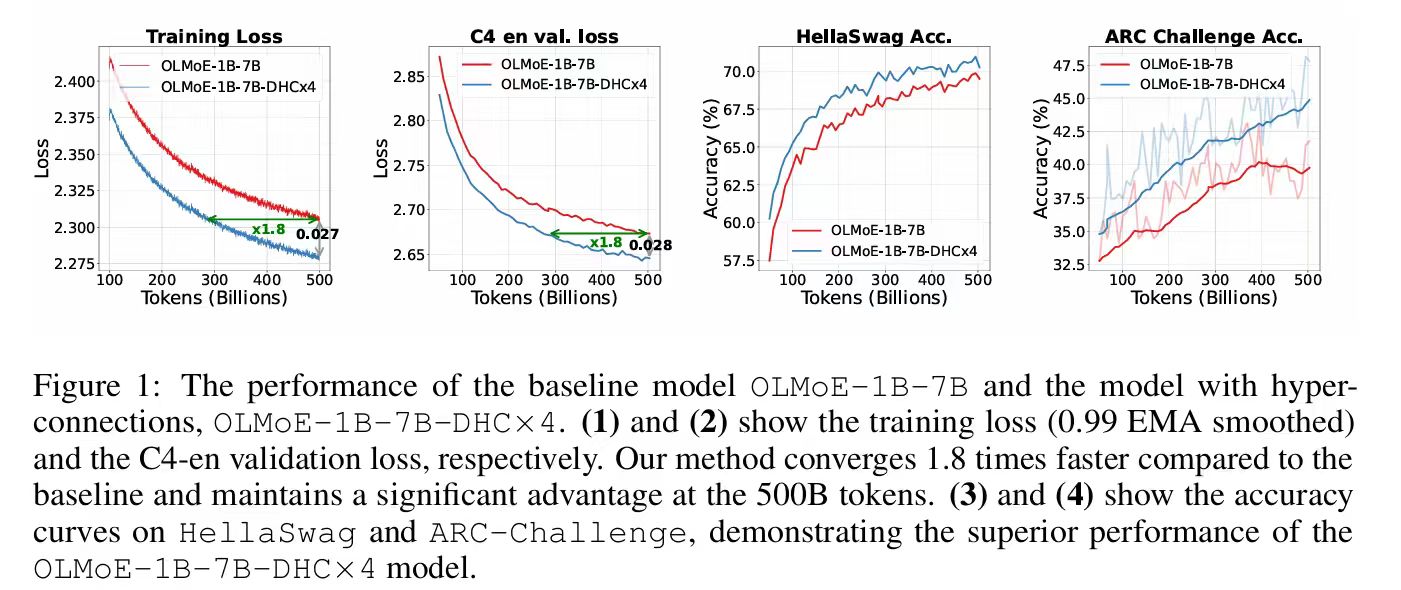
Hyper Connections
Hyper Connections 的结构如下图(b)所示。该方法引入了两种可学习的连接机制:深度连接(Depth-Connections)和宽度连接(Width-Connections)。
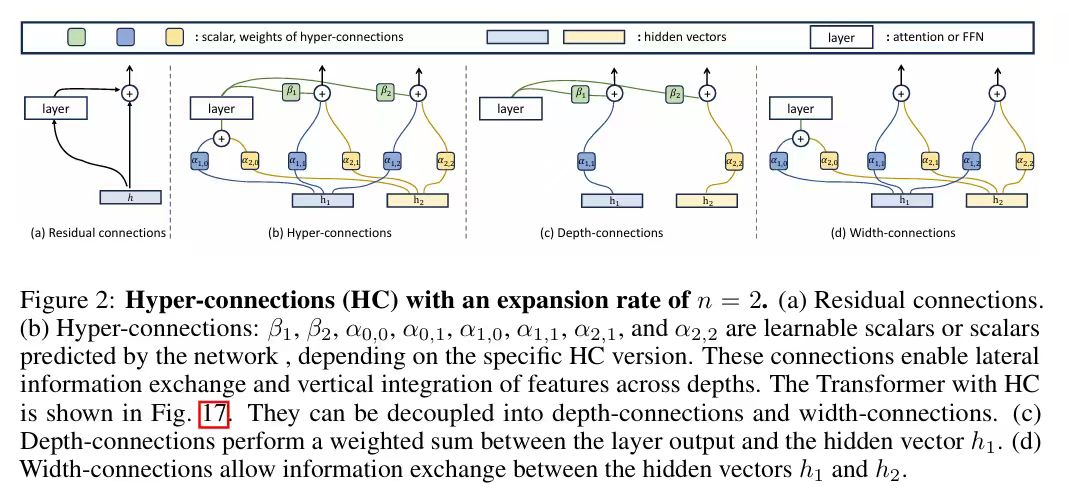
- 深度连接(Depth-Connections):类似于残差连接,但通过为输入与输出之间的连接分配可学习的权重,允许网络灵活调整不同层之间的连接强度。
- 宽度连接(Width-Connections):在每一层中实现Hidden Vector之间的信息交互,增强特征融合能力,从而提升模型的表示效果。
首先,将输入扩展为 n 份(n 称为膨胀率(Expansion Rate))。此后,每一层的输入均为 n 个隐藏向量(如图 (b) 中的 h1、h2)。通过将深度连接与宽度连接统一为矩阵形式,Hyper Connections 不仅可以调整残差连接的强度,还能实现对网络层的重排列。
此外,Hyper Connetions可以分为静态和动态两种类型:
- Static Hyper Connections (SHC):连接权重在训练完成后保持固定,不随输入变化。
- Dynamic Hyper Connections (DHC):连接权重根据输入动态变化,能够自适应不同的输入,通常效果更优
Static Hyper-Connections(SHC)
首先,第0层的输入为h0,维度为d,然后将其复制n次,得到初始矩阵:
H0=(h0 h0 ... h0 )T
第k层的输入是上一层的Hk−1,即:
Hk−1=(h1k−1 h2k−1 ... hnk−1)T
最终的输出表示为对最后一层的矩阵按行求和,最后进行一次前归一化,获得最终输出得到最后所需要的向量。
为了简化后续分析中的符号表示,省略层索引,记矩阵为:
H=(h1 h2 ... hn )T
上图的(b)为Hyper Connections的图结构,其实Hyper Connections可以用一个矩阵来表示,对于扩展率为n的情况,Hyper Connections矩阵HC如下:
HC=(O1×1AmBAr)=⎝⎜⎜⎜⎜⎜⎛0α1,0α2,0⋮αn,0β1α1,1α2,1⋮αn,1β2α1,2α2,2⋮αn,2⋯⋯⋯⋱⋯βnα1,nα2,n⋮αn,n⎠⎟⎟⎟⎟⎟⎞∈R(n+1)×(n+1).
考虑一层网络T ,它可能是Transformer中的Attention层或者是FFN层,那么Hyper Connections的输出H^可以简单地表示为:
H^=HC(T,H)=B⊤T(H⊤Am)⊤+Ar⊤H
即对输入H,按Am的权重进行加权和获得当前网络层T的输入:
h0⊤=Am⊤H
Ar用于将H映射为hyper hidden matrix H′,即:
H′=Ar⊤H
那么最终式子可以变为:
H^=B⊤(Th0)⊤+H′
则Depth-Connections(上图(c))可以被解耦为:
DC=(Bdiag(Ar))=(β1α1,1β2α2,2⋯⋯βnαn,n)∈R2×n
其中B和diag(Ar)分别表示当前网络T 的输出和输入权重。diag(Ar)表示将Ar沿着对角线展开。
同样的,Width-Connections(上图(d))可以被定义为:
WC=(AmAr)∈Rn×(n+1).
伪代码如下:

Dynamic Hyper Connections (DHC)
所谓动态,即Hyper Connections矩阵HC的元素随着输入矩阵 H 动态的进行变化。
HC(H)=(01×1Am(H)B(H)Ar(H))
给网络T和输入矩阵 H ,动态 Hyper Connections 的输出可以表示为:
H^=HC(H)(T,H)
在实际操作中,DHC是结合静态和动态矩阵实现的。动态参数通过线性变换生成。
为了稳定训练过程,在线性变换前加入归一化,随后使用 tanh 激活函数,并通过一个可学习的缩放因子进行调整。动态参数的计算公式如下所示:
H=norm(H)
B(H)=sβ∘tanh(HWβ)⊤+B∈R1×n
Am(H)=sα∘tanh(HWm)+Am∈Rn×1
Ar(H)=sα∘tanh(HWr)+Ar∈Rn×n
代码为:

Why Hyper Connections
前归一化与后归一化
前归一化与后归一化均可视为 Hyper Connections 在不可训练情况下的特例。
当膨胀率 n=1 时,Hyper Connections 可分别退化为前归一化与后归一化形式:
HCPreNorm=(0111),HCPostNorm=⎝⎛01σi2+σo2+2σio1σi2+σo2+σio1⎠⎞
其中,σi 和 σo 分别为网络层输入和输出的标准差,σio 为二者的协方差。
顺序排列与并行排列
Hyper Connections可以学习将不同层重排列,形成顺序排列或并行排列的混合结构
当n(膨胀率)为2的时候,如果 Hyper Connections 的矩阵形式如下所示,则网络层将被顺序排列:
HC=⎝⎛010110101⎠⎞
结构如下图(a)所示。
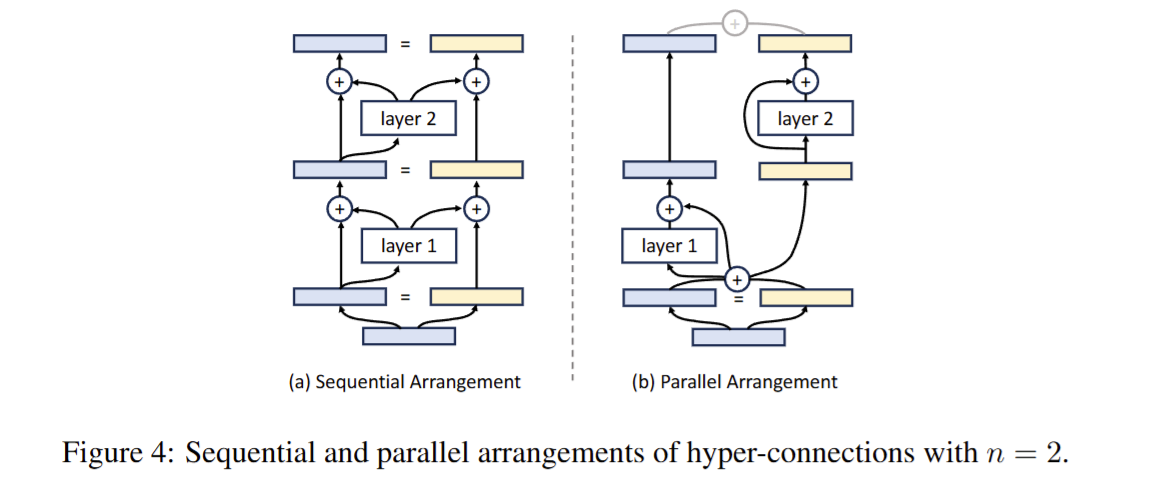
当奇数层和偶数层的Hyper Connections矩阵分别定义为以下形式时,神经网络每两层将被并行排列,类似于 Transformer 中的并行排列的方式,如上图(b) 所示。
HCodd=⎝⎛011111011⎠⎞
HCeven=⎝⎛001010101⎠⎞.
因此,通过学习不同形式的Hyper Connections矩阵,网络层的排列可以多种表现形式。
实验
一方面,Hyper Connections 显著提升了训练稳定性,使训练过程中的损失曲线更加平滑:
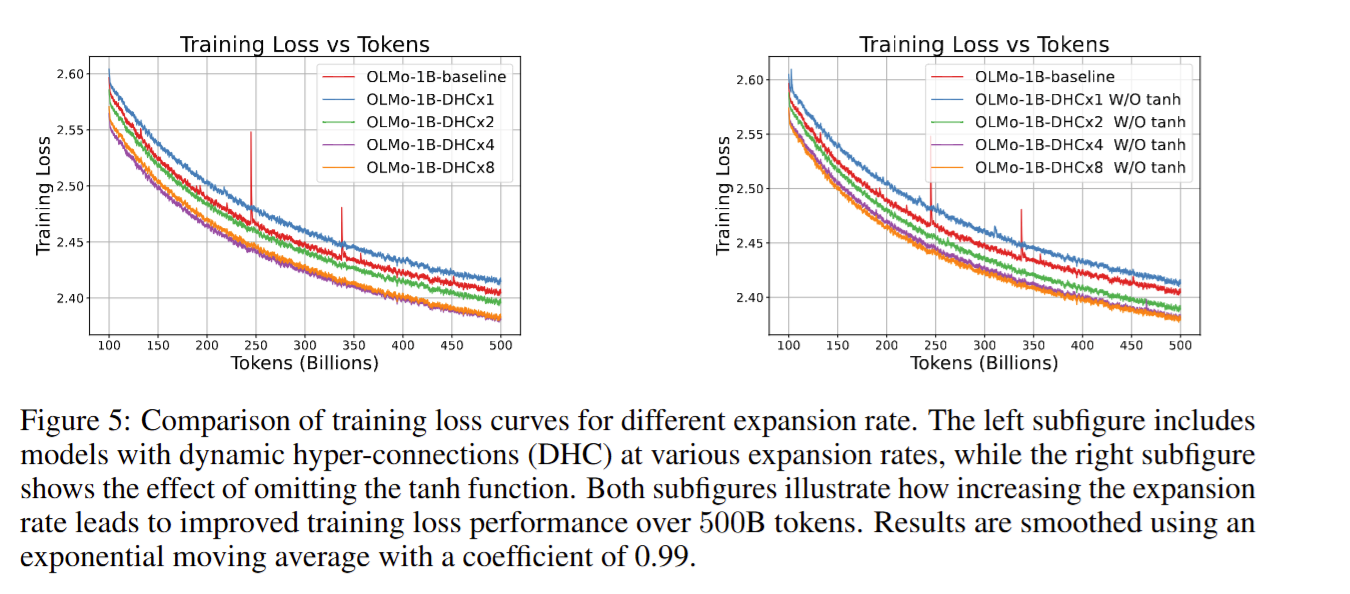
另一方面,Hyper Connections 在最终效果上也表现优异:
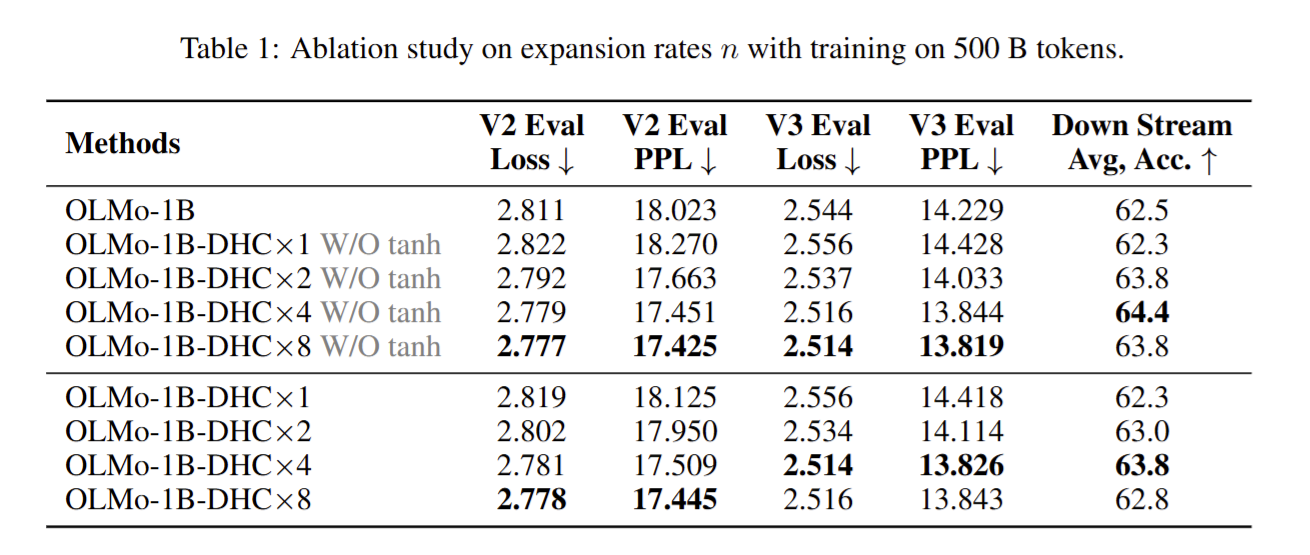
研究还对比了不同连接模式的特性::
- Hyper Connections 显示出一种大致形连接模式,即每层输出对邻近层的贡献较大,同时浅层对远层有长期贡献。这种模式融合了 Pre-Norm 和 Post-Norm 结构的特性。
- **Pre-Norm **的连接矩阵呈下三角形,反映了每层仅与前一层直接相连。
- **Post-Norm ** 的连接仅限于相邻层,权重随着深度迅速衰减。
- Two-hop残差连接 的连接模式表现为仅隔层有贡献,形成条状分布。
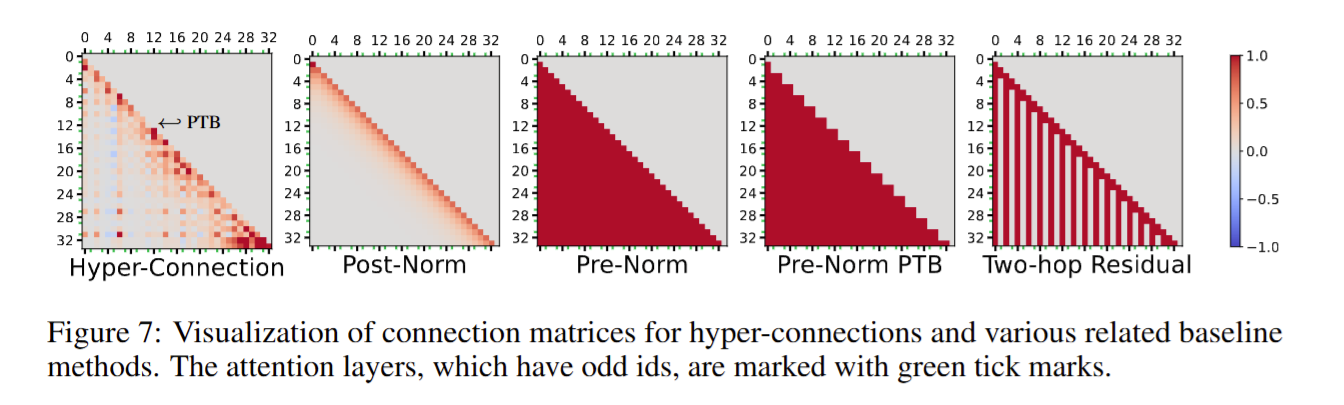
总结
Hyper Connections是针对为解决残差连接的PreNorm和PostNorm在梯度消失和表示崩溃之间现象而提出的。
该方法在大语言模型预训练及视觉任务中均展现出显著的性能提升,同时几乎不增加额外的计算开销或参数量,因此具有广泛的应用潜力(例如今年 DeepSeek 在此基础上提出的改进版本 mHC)。
不过,该方法也存在显存占用增加的问题,需要在算子层面进行重计算优化,以减少显存开销。
参考文章
