FastText

FastText是在word2vec的cbow和skip-gram基础上得到模型,其最大的特点是模型简洁,训练速度快且文本分类准确率也令人满意
fastText 训练词向量的时候一般是使用Skip-gram模型的变种。在用作文本分类的时候,一般是使用CBOW的变种
前置知识
N-gram特征
fastText在做词向量的时候引入了subword n-gram的概念来解决词形变化的问题。它将一个单词打散到char级别,并且利用字符级别的n-gram信息来捕捉字符间的顺序关系,希望能够以此丰富单词内部更细微的语义。
而当fastText做文本分类的时候,变为了word n-grams。它将一个短语打散到word级别。
举个例子
- 做词向量的时候
对于一个词“where“,为了表达单词前后边界,我们加入<>两个字符,即变形为“< where >。假设我们希望抽取3-gram信息,可以得到如下集合:G = { < w h,w h e,h e r,e r e,r e >}。在实践中,我们往往会同时提取单词的多种n-gram信息,如2/3/4/5-gram。这样,原始的一个句子,就被一个char级别的n-gram集合所表达。
对应到中文,其实就是偏旁部首。 阿里曾发布fasttext的一个中文版本,训练的就是偏旁部首。
- 做文本分类的时候
对于一个短语“我 爱 北京 天安门“,同样加入<>两个字符,变为“< 我 爱 北京 天安门 >”,那么2-gram得到如下集合,G={< 我,我 爱,爱 北京,北京 天安门,天安门 >}。
FastText生成词向量
关于FastText词向量,原论文《Enriching Word Vectors with Subword Information》
FastText生成词向量是在skip-gram模型基础上提出来的,需要回顾一下word2ve中的skip-gram模型(参考上一篇文章)

如上图为Word2vec原Skip-Gram模型。
FastText构建词向量与word2vec中Skip-Gram模型唯一不同的就是在输入层。
- FastText取n-gram求和作为词向量,后者取One-Hot词向量;
- 输入向量矩阵中,FastText的N为所有语料的n-grams总数,而Word2vec则为语料word总数。
其余过程就和skip-Gram过程相同了,乘上一个矩阵w,获得向量,然后乘上另一个矩阵w*,进行softmax最后输出属于每个标签的概率,再进行反向传播。最后的w矩阵和最初的1*V向量相乘作为表示的词向量。
FastText的输入
例如
比如对于词汇表D中的 where 词:
原词:< w h e r e > ,分别获得其3,4,5,6-gram
- 3-grams: < w h , w h e , h e r , e r e , r e >
- 4-grams: < w h e, w h e r , h e r e, e r e >
- 5-grams: < w h e r , w h e r e , h e r e >
- 6-grams: < w h e r e , w h e r e >
然后将原词的和字符级n-grams的one-hot编码进行累加得到输入向量,
即将< where>和3-grams,4-grams,5-grams,6-grams的one-hot向量相加得到
如果遇到了OOV怎么办?只使用n-grams的向量和来表示就可以
void Dictionary::computeSubwords(const std::string& word,std::vector<int32_t>& ngrams,std::vector<std::string>* substrings)const {
for (size_t i = 0; i < word.size(); i++) {
std::string ngram;
if ((word[i] & 0xC0) == 0x80) {
continue; // 遇到10开头字节跳过,保证中文从第一个字节开始读
}
for (size_t j = i, n = 1; j < word.size() && n <= args_->maxn; n++) {
ngram.push_back(word[j++]);
while (j < word.size() && (word[j] & 0xC0) == 0x80) {
ngram.push_back(word[j++]); // 如果是中文,读取该字符的所有字节
}
if (n >= args_->minn && !(n == 1 && (i == 0 || j == word.size()))) {// subword满足长度,
int32_t h = hash(ngram) % args_->bucket;//将字符通过hash,得到的hash值加入到ngrams里面
pushHash(ngrams, h);
if (substrings) {
substrings->push_back(ngram);
}
}
}
}
}
在fastText源代码中,将n-gram进行hash,hash到同一位置的多个n-gram会共享一个embedding。这样降低了学习的embedding规模,够极大的节省了空间。
FastText进行文本分类
关于FastText文本分类,原论文《[Enriching Word Vectors with Subword Information]》
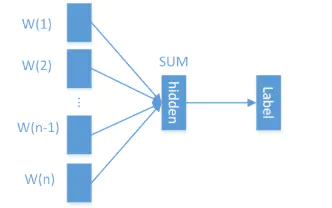
fasttext文本分类的模型,该模型类似word2vec的cbow模型.
与Word2vec的CBOW仅有两个区别:
-
输出是预测类别标签而不是预测中心词。
-
使用句子中所有单词及其n-gram作为输入,进行embedding,而不再是单单的针对滑动窗口中的单词进行one-hot。
其中输入的n-gram向量和fastText进行词向量过程是一致的,不过此时n-gram变为了词语级别而不是字符级别
其余过程就和cbow过程相同了,乘上一个矩阵w,对向量进行加权平均,然后乘上另一个矩阵w*,进行softmax最后输出属于每个标签的概率,再进行反向传播。
例如
对于一个短语“我 爱 北京 天安门“,同样加入<>两个字符,变为“< 我 爱 北京 天安门 >”
- 2-gram得到如下集合,{< 我,我 爱,爱 北京,北京 天安门,天安门 >}。
- 3-gram得到如下集合,{<我爱,我 爱 北京,爱 北京 天安门,北京 天安门 >}
- 4-gram得到如下集合,{< 我 爱 北京,我 爱 北京 天安门,爱 北京 天安门 >}
- 5-gram得到如下集合,{< 我 爱 北京 天安门,我 爱 北京 天安门 >}
然后将原句的和词语级n-grams的one-hot编码进行累加得到输入向量,
将< 我 爱 北京 天安门 >和2-gram,3-grams,4-grams,5-grams的one-hot向量相加求平均得到
优化
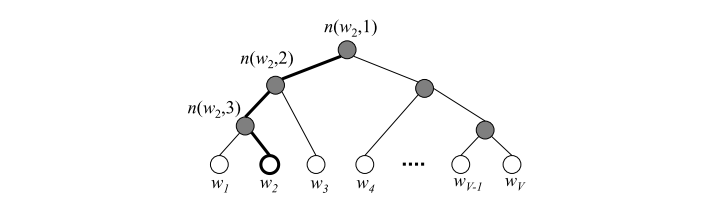
与word2vec一样,可以通过层次softmax进行优化。
与word2vec不同的是,fastText层次优化的叶子结点为文档标签的类别而不是中心词概率,以训练集中标签的频率进行排序,频率越高则越靠近根节点。
Gensim实现
FastText生成词向量在gensim中调用如下为:
class gensim.models.fasttext.FastText(sentences=None, corpus_file=None, sg=0, hs=0, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, word_ngrams=1, sample=0.001, seed=1, workers=3, min_alpha=0.0001, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=<built-in function hash>, iter=5, null_word=0, min_n=3, max_n=6, sorted_vocab=1, bucket=2000000, trim_rule=None, batch_words=10000, callbacks=())
数与word2vec遵循相同的模式。FastText支持原始word2vec中的下列参数:
- model: 训练架构. (允许的值: cbow, skipgram (默认 cbow)
- vector_size: 需要学习的嵌入的大小 (默认 100)
- alpha: 初始学习率 (默认 0.025)
- window: 上下文窗口大小 (默认 5)
- min_count: 忽略出现次数小于某个值的单词 (默认 5)
- loss: 训练目标. (允许的值: ns, hs, softmax (默认 ns)
- sample: 高频词的下采样阈值 (默认 0.001)
- negative: 要抽样的否定词数, for ns (默认 5)
- iter: epochs的数量 (默认 5)
- sorted_vocab: 按下降频率排序的单词 (默认 1)
threads: 使用的线程数量 (默认 12)
此外, FastText 还有3个额外参数:
- min_n: char ngrams的最小长度 (默认 3)
- max_n: char ngrams的最大长度 (默认 6)
- bucket: 用于散列ngrams的buckets数量 (默认 200000)
from pprint import pprint as print
from gensim.models.fasttext import FastText as Fasttext
from gensim.test.utils import datapath
if __name__ == '__main__':
corpus_file = datapath('lee_background.cor')
model = Fasttext(vector_size=60)
# build the vocabulary
model.build_vocab(corpus_file=corpus_file)
# train the model
model.train(
corpus_file=corpus_file, epochs=model.epochs,
total_examples=model.corpus_count, total_words=model.corpus_total_words
)
print(model.wv['爱丽丝'])
E:\python310\python.exe E:\fastText.py
array([ 0.00829479, 0.00071116, 0.00169409, -0.0025965 , 0.00328374,
-0.00180369, 0.00734048, 0.00590759, 0.00469353, 0.00143918,
-0.00479525, -0.00138552, 0.00741526, -0.00677875, -0.0017609 ,
-0.00018423, 0.00386455, 0.0009411 , 0.00489743, 0.00577713,
-0.00434757, -0.00546971, 0.00332852, 0.00614409, -0.00440957,
-0.00459056, -0.00591491, 0.00492364, -0.00173003, 0.00622221,
0.00049063, 0.00308326, 0.00337223, -0.00502754, -0.00046228,
0.00731711, -0.00710381, -0.00627137, 0.00071484, 0.00328238,
-0.00096842, -0.00138118, -0.00020508, -0.00524326, -0.00524897,
0.00445769, -0.00016085, -0.00373317, -0.00042375, 0.00661727,
0.00350993, 0.00502089, -0.00400781, -0.00213982, -0.00387585,
-0.00850575, 0.00332142, 0.00020067, -0.00368993, 0.00553988],
dtype=float32)
进程已结束,退出代码0
总结
fastText是word2vec的优化模型
相比于Bert等方法,fastText具有如下优点:
- 训练速度快,精度相当;
- 不需要预训练的词向量;
- N-gram特征关注了词序信息;
- 层次化Softmax优化了时间效率。