对预训练模型进行微调

近年来随着自然语言处理技术的不断发展,预训练模型已经成为了近年来最热门的研究方向之一。预训练模型有更好的性能表现。然而,对于刚接触的人来说,阵对预训练模型的训练可能会显得复杂和难以理解。
因此,本文将以对BART微调用于文本摘要任务为例子提供如何对预训练模型+微调的教程,通过本文所提供的示例,相信能够更好地理解和应用预训练模型,从而在自己的研究和项目中取得更好的成果。
什么是预训练+微调
预训练+微调是一种常用的NLP训练的范式。预训练+微调的过程通常可以分为两个阶段:
首先,在一个大规模的数据集上训练一个通用的预训练模型,例如BERT、GPT-2等。这个预训练模型的目标是学习一些通用的语言模型或者视觉特征,以便能够应用到各种具体任务中。
其次,针对具体的任务,在相对较小的数据集上对预训练模型进行微调。可以将预训练模型Fine-tune到文本分类、命名实体识别等子任务中。微调的过程通常是在原来预训练模型的基础上,针对具体任务的特定数据集进行少量的训练,以调整模型的参数,使得模型在具体任务上能够取得更好的表现。
叫我们自己实现一个预训练模型是不现实的(没钱、没显卡),但是不用担心,Google、Facebook等大厂会帮我们训练好大模型,我们所需要做的,只需要调用他们在自己的数据集微调就好了。
训练环境搭建
首先我们需要准备好微调环境,你可以在自己的电脑上安装所需要的库,如:Pytorch、Transformers、NLTK等等所必须要库。但是,我觉得可以,但是没有必要。因为随着互联网的发展,我们完全可以使用云平台来来协助我们训练模型,接下来的教程,将会依靠百度的云平台飞桨AI Studio - 人工智能学习实训社区来完成
云平台的优点
在自己的电脑上运行模型往往会安装大量的库,但是这些库的安装并不像
pip install xxx
这样一行命令就能够完成安装,往往需要踩过各种坑才能安装成功
而如果使用云平台的话,事情就好办多了,自带各种深度学习框架,无需下载
如何使用
1.进入飞桨AI Studio,注册并登录
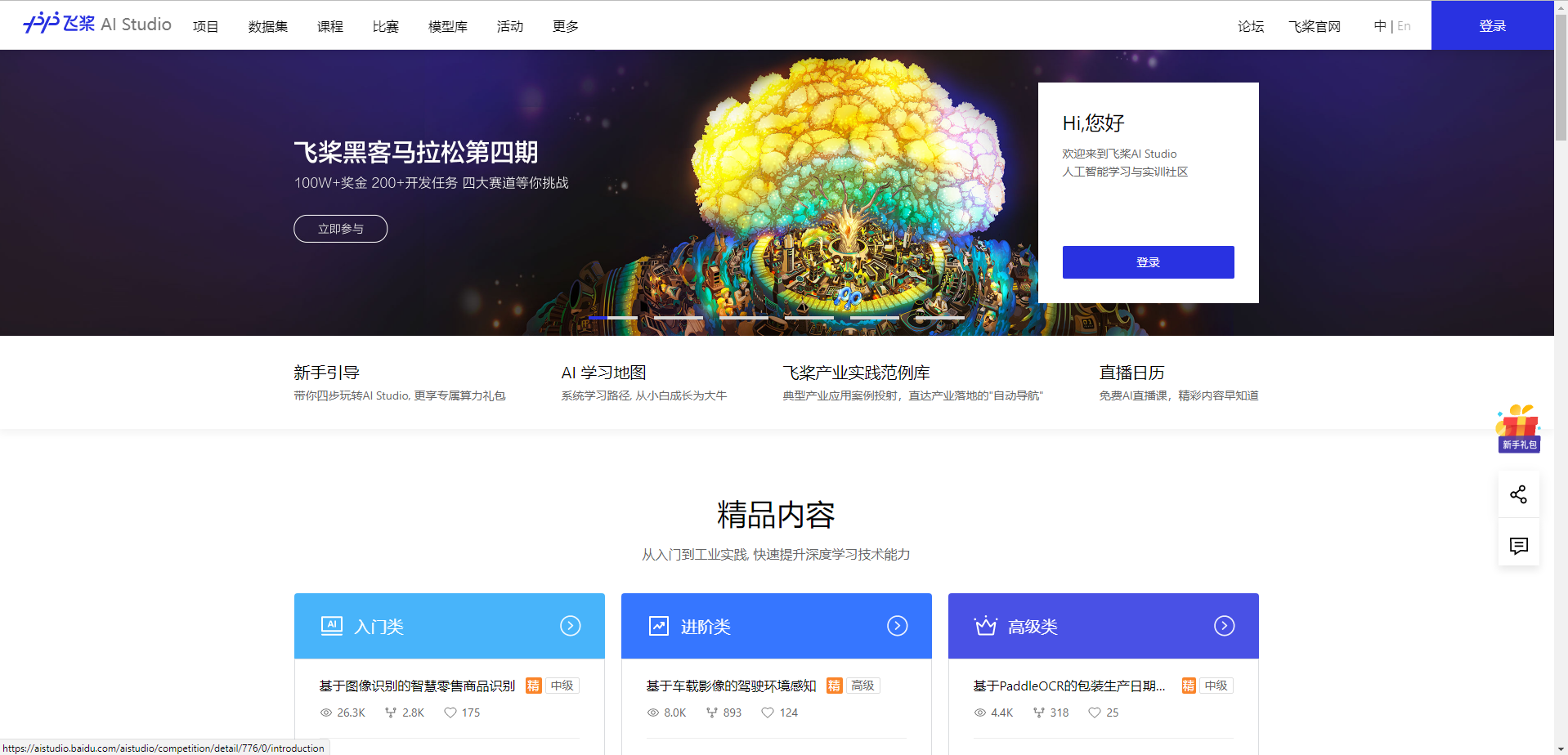
2.右上角进入个人中心,在项目里新建一个项目,全部默认设置,最后设置项目名称、标签、描述,有需要可以添加自己的数据集
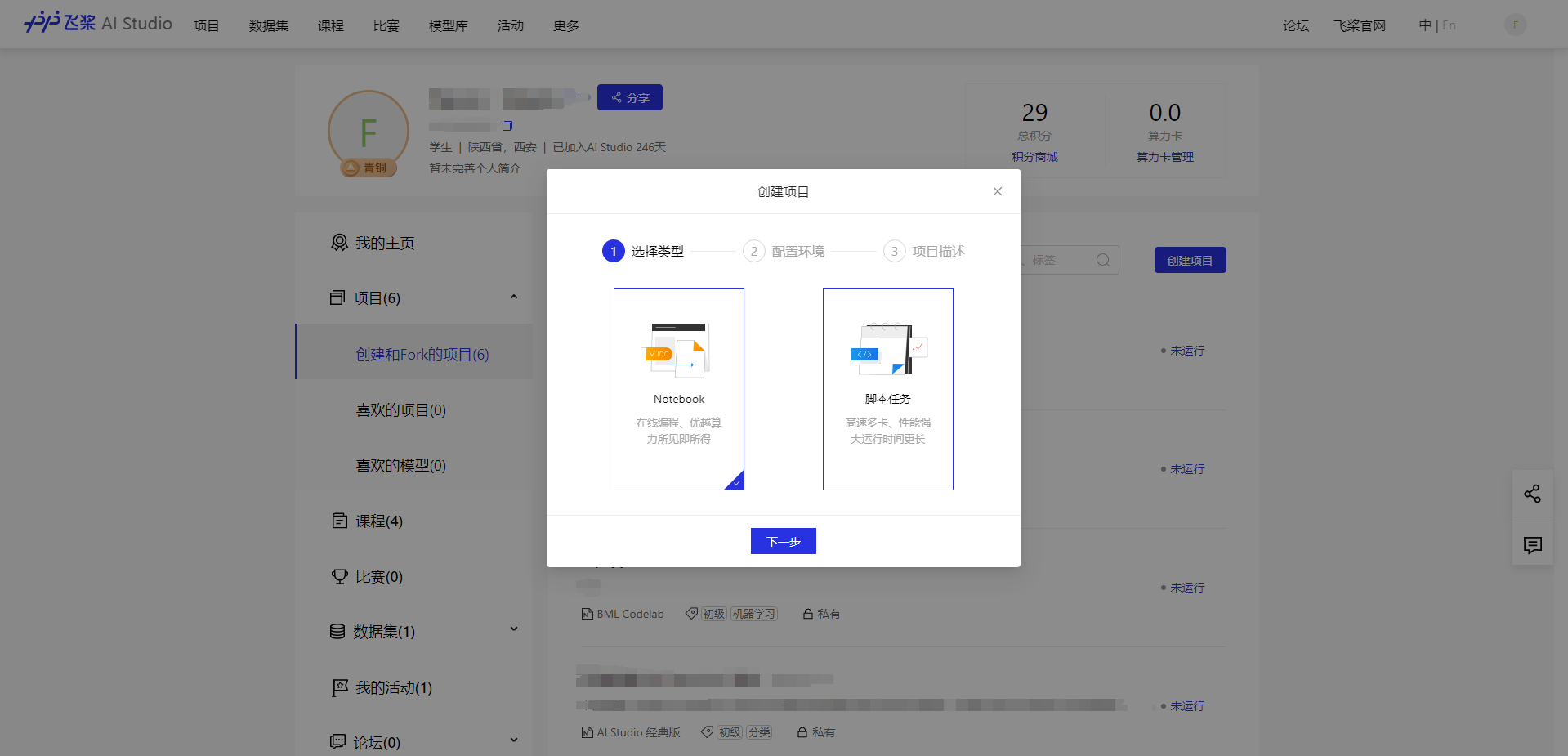
3.创建好后,点击启动环境,注意基础版没有GPU,所以我们需要选择有GPU的环境
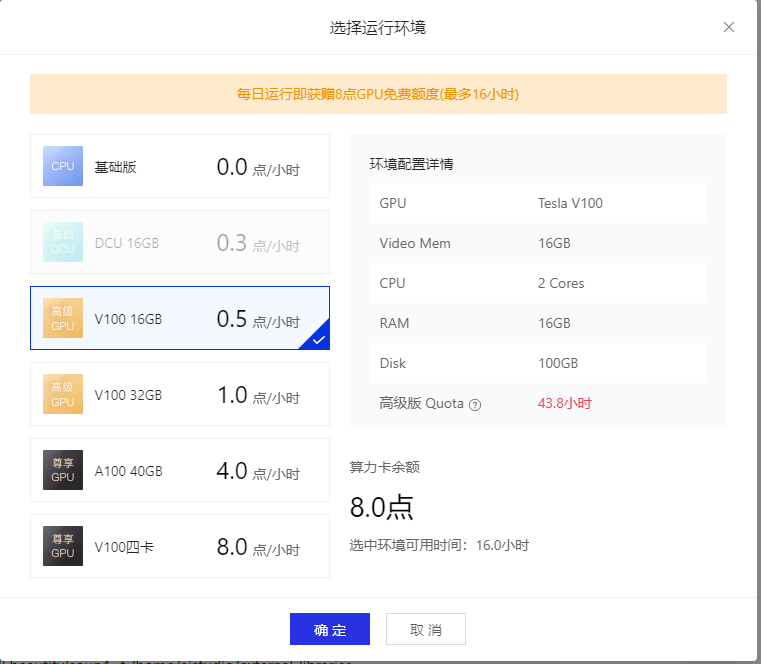
等待环境部署...
4.完善环境的搭建
在文本摘要任务中我们还需要"rouge_score"库来进行ROUGE的计算,wandb库来进行微调的可视化,只需要点击“+”号,进入终端用pip命令安装即可。
pip install rouge_score
pip install wandb
如此,我们的实验环境便搭建好了
模型的获取
回到飞桨AI Studio,进入模型库,内置了包含许多任务的模型
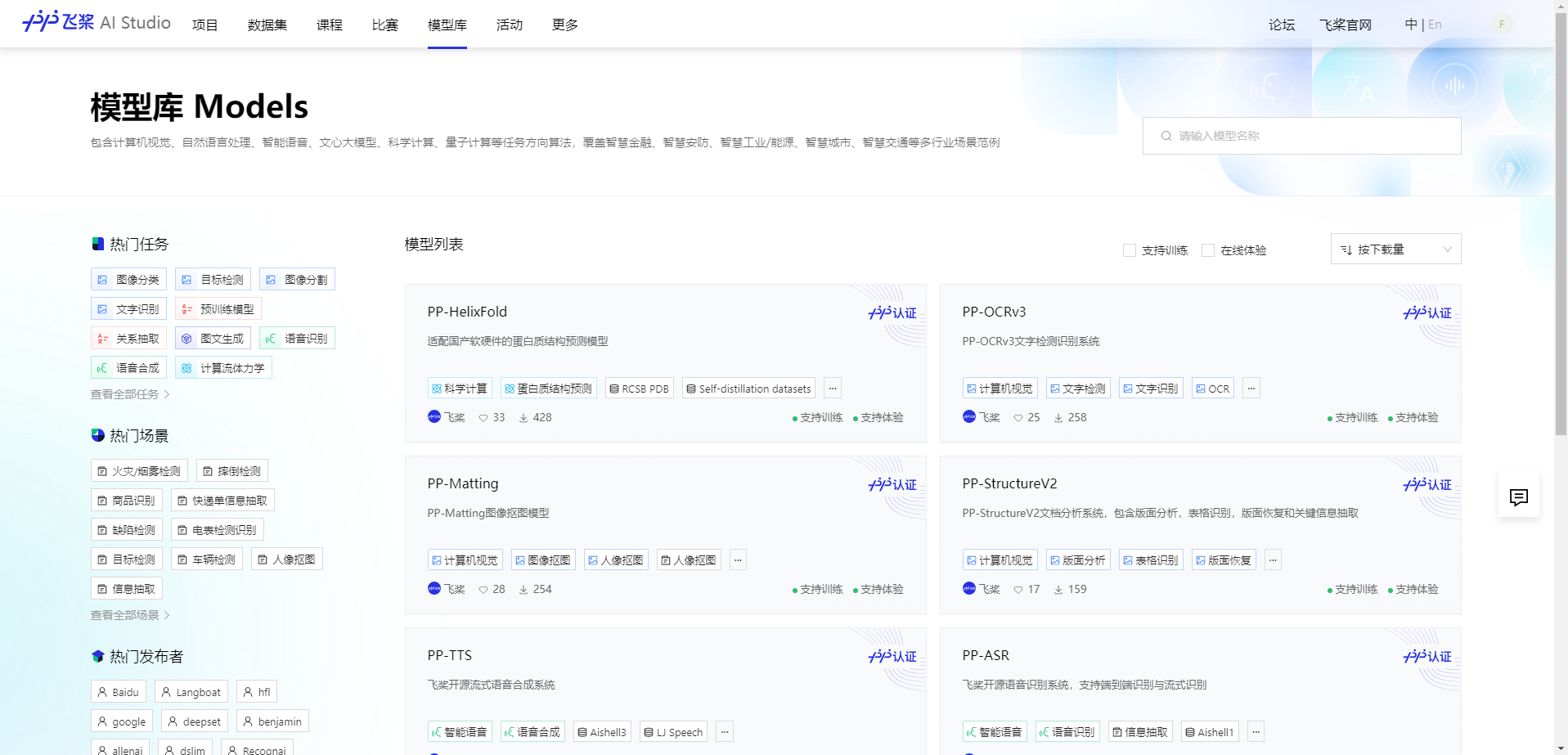
文本摘要是生成式模型,我们点击“自然语言处理->文本生成”查看是否有BART模型
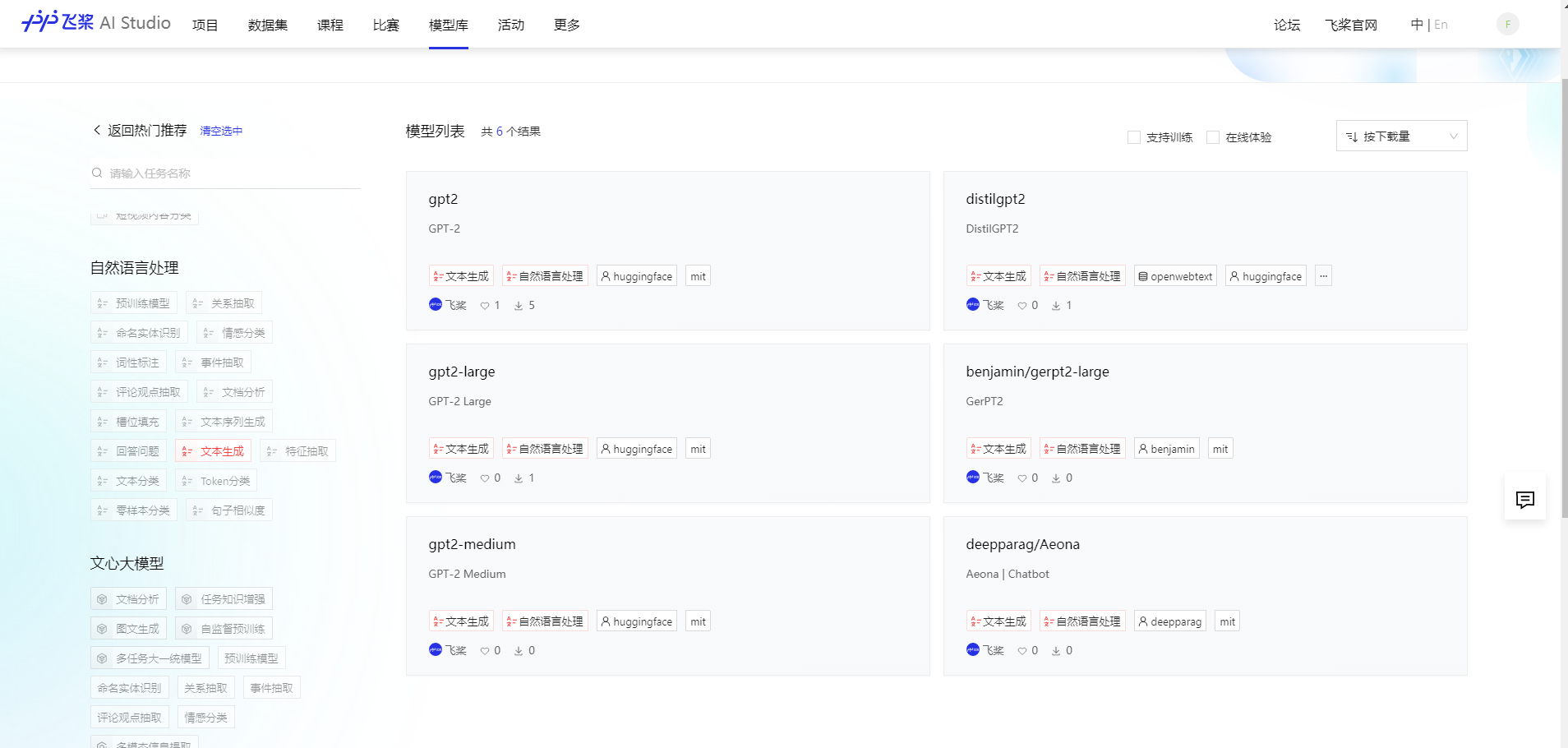
没有?其实我们在BART模型汇总 — PaddleNLP 文档,中可以看见,其实PaddleNlp已经内置了BART模型,不需要额外的进行下载。
我们只需要在训练的时候这么写就能导入 BART 了
from paddlenlp.transformers import BartForConditionalGeneration, BartTokenizer
model = BartForConditionalGeneration.from_pretrained('bart-base')
tokenizer = BartTokenizer.from_pretrained('bart-base')
其实相较于Huggingface,Paddle包含的模型简直少得可怜,但是PaddleNLP并不能直接使用Huggingface里的模型,那怎么办呢?其实我们可以通过转换,将Huggingface里的模型转为PaddleNLP所支持的就可以了
数据集的获取
PaddleNLP内置了许多模型,当然也内置了许多的数据库,可以快速的使用API进行调用,具体的数据集可以在此查看:
PaddleNLP Datasets API — PaddleNLP 文档
我们在文本生成一类中发现了我们需要的摘要数据集
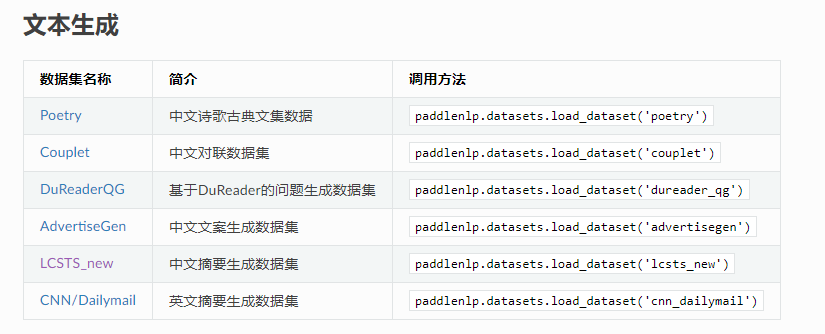
如此,便导入了本次训练的数据集LCSTS
from paddlenlp.datasets import load_dataset
train, val = load_dataset('lcsts_new', splits=["train", "dev"])
当然,如果有自己的数据集可以这样导入
from paddlenlp.datasets import load_dataset
train_ds, dev_ds = load_dataset("squad", data_files=("my_train_file.json", "my_dev_file.json"))
test_ds = load_dataset("squad", data_files="my_test_file.json")
微调
以上,我们完成了环境的搭建、模型和数据集的导入,接下来就正式进入微调环节
本次微调我们需要三个文件:
train.py:训练接口文件,对参数的设置
train_utils.py:模型的加载及其训练具体代码
csl_title_public.py:数据集的加载与处理
代码在此:voluntexi/Pre-trainedForSummarization (github.com)
运行
打开train.py,config中的参数
config = {
'seed': 2022,
'pretrained_model': 'bart-base',
'dataset_name': 'lcsts_new',
'train_batch_size': 18,
'eval_batch_size': 16,
'save_steps':3000,
'logging_steps':200,
'max_source_length': 512,
'max_target_length': 128,
'min_target_length': 0,
'max_steps': -1,
'warmup_proportion': 0.1,
'warmup_steps': 0,
'num_train_epochs': 30,
'learning_rate': 1e-5,
'adam_epsilon': 1e-6,
'weight_decay': 0.01,
'use_amp': False,
'scale_loss': 2**15,
'output_dir': './output',
'device': 'GPU',
'ignore_pad_token_for_loss': True
}
执行代码
python train.py
就可以开始训练了,wandb能够将训练过程可视化
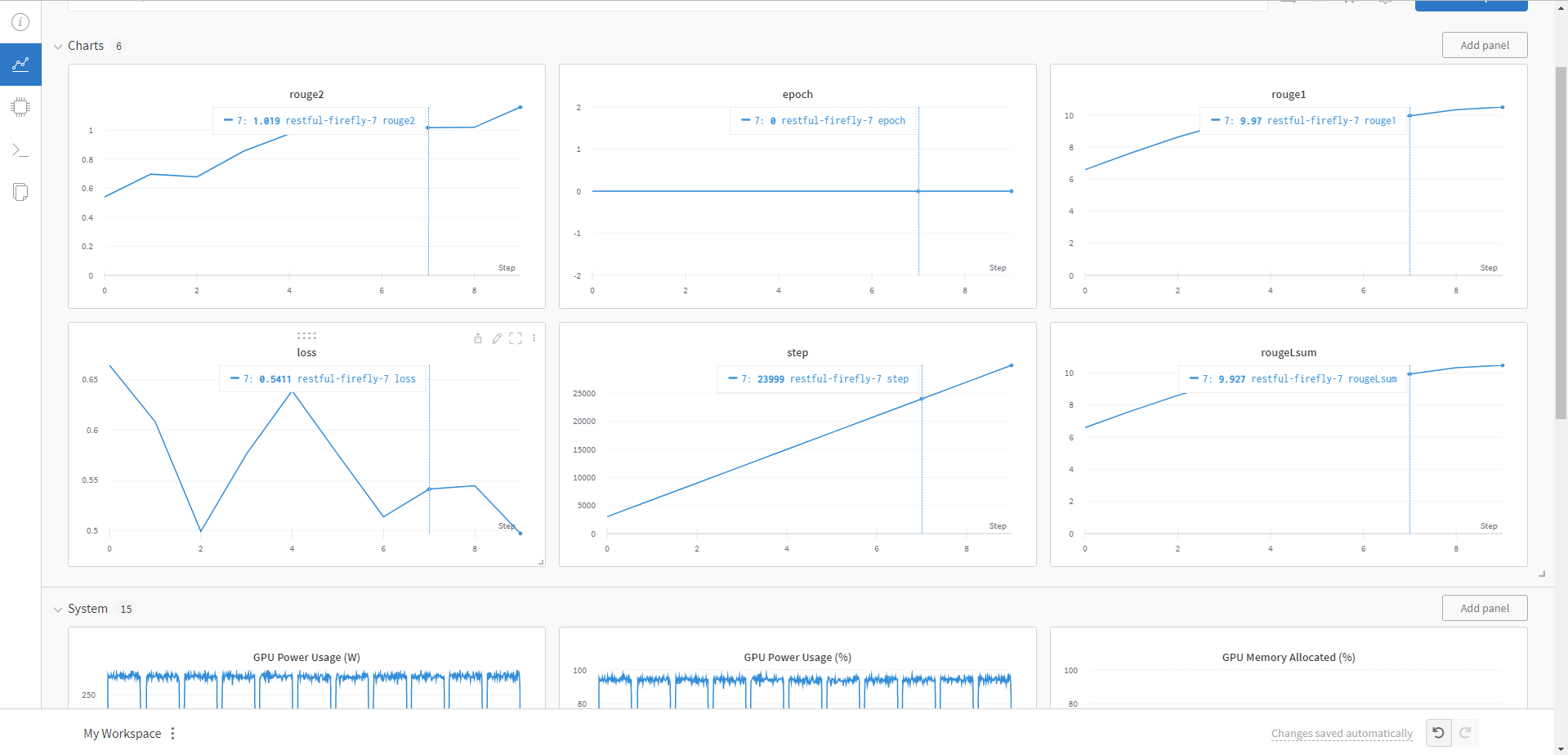
可以看到训练完成后的效果并不好,主要有以下几个原因:
- 训练Epoch太少,例子中我只设置的1代的Epoch,当然效果不是很好,在正式的任务中建议还是加大Epoch的数值
- 本文采用的BART-BASE是在英文上进行预训练的,用于中文肯定效果不好,在正式的任务中对于中文数据集还是需要在Huggingface中寻找使用中文训练的模型
总结
以上就是对预训练模型进行微调的形式,使用到的工具有:百度云平台、PaddlePaddle、PaddleNLP、wandb、NLTK等工具/库
掌握后,后续就可以在此基础上加上其他模型,以更好的提升模型的性能,如BERT+LSTM+ATTEN等模型的拼接训练。