抖音视频和用户评论爬虫

本文将详细的讲述关于抖音网络爬虫的实现过程。
由于抖音爬虫的反爬虫策略较为严格,本节将抖音网络爬虫用作详细介绍,主要详细介绍抖音网站的特点,对抖音网站进行分析,爬取抖音的用户评论所用到的具体实现思路过程
抖音网站分析
要抓取抖音中的用户评论等相关信息,首先要对抖音的网站页面整体布局以及网站所储存的信息的方式进行一个相对全面的理解和分析,才能逐个攻破,最终获取到我们所需要的有用信息。
首先,打开网页版的抖音,在搜索栏中输入想要进行分析的视频博主的视频,如图1。进入视频的详细页后,如图下拉评论页面,找到评论所存在的位置,如图2。
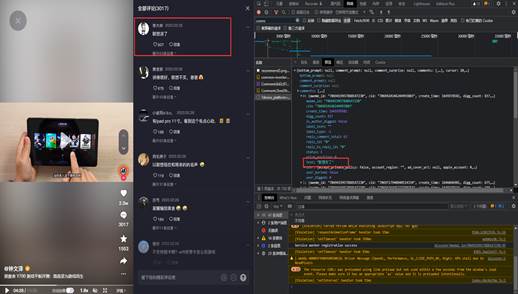
接下来在Google Chrome浏览器中按下F12,打开开发者模式,然后点击网络,在开发者模式窗口左方的文件中,点击预览来搜索评论存在的网页,来观察其存储的方式
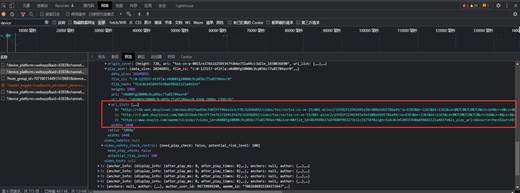
同时发现,每翻一页评论页面,该网络请求下的cursor参数就会增加20。
经过上诉分析,发现抖音用户评论以及用户的相关的数据是存储在?device_platform=webapp&aid=6383&channel=channel_p…iJquvs9LcUAKk2YMk3aKHHEubQFxlKDQOwtkPFZryFj6FS.99之中的,而且通过XHR的方式来进行加载的,存储的方式是通过JSON。于是我们就可以通过模拟请求头来模拟,向?device_platform=webapp&aid=6383&channel=channel_p…iJquvs9LcUAKk2YMk3aKHHEubQFxlKDQOwtkPFZryFj6FS.99进行请求,通过将cursor增加20的操作来进行翻页,然后将请求得到的信息通过json进行转化,最后再提取所需要的信息。
同理,我们也可以在开发者模式中,通过上述的操作同样找到视频的地址
抖音爬虫的实现
构造请求头向抖音模拟requests请求,提取网站存储的用户信息::
构造DouyinCrawler函数,并通过构造形参来接受请求的URL。并通过cursor增加20的操作来进行翻页。Hearders的请求参数如下:
params = (
('device_platform', 'webapp'),
('aid', '6383'),
('channel', 'channel_pc_web'),
('aweme_id', '70694199578814723'),
('cursor', str(0+cursor*20)),
('count', '20'),
('version_code', '170400'),
('version_name', '17.4.0'),
('cookie_enabled', 'true'),
('screen_width', '1920'),
('screen_height', '1080'),
('browser_language', 'zh-CN'),
('browser_name', 'Chrome'),
('browser_version', '96.0.4664.45'),
('browser_online', 'true'),
('engine_name', 'Blink'),
('engine_version', '96.0.4664.45'),
('os_name', 'Windows'),
('os_version', '10'),
('cpu_core_num', '8'),
('device_memory', '8'),
('platform', 'PC'),
('downlink', '3.4'),
('effective_type', '4g'),
('round_trip_time', '50'),
('msToken', 'xO8ykiImW4_y1P17rjjV82tkToK8sdVUSXsck7dqlo5egXnsLielL_-gNoh0eTlNzohikTmdqccSsY3Es0-we3HmgJYX-jaWe7rO1uKCGLQSCz4tUKiWsZwpNQ=='),
('X-Bogus', 'DFSzswVuuEtANasbSiKxme9WX7j6'),
('_signature',
'_02B4Z6wo00001cGgFBAAAIDBQaLuUEhgJOnBoBCAABHQa2zGW56-brVbd8zPJMMr5zV9wMRK.Fw-baUMHl14.I7n6EC4lETZbOyGYyoi08uVzPer1kHjbwJPWfXZBARPia3I0l-u0HyASZI012'),
)
接下来就可以对网站的数据进行获取,将数据通过一个数组保存下来
def Html(html):
# 获取所需内容
s=json.loads(html)
for i in range(20):
comment=s['data']['replies'][i]
floor = comment['member']['mid']
sex=comment['member']['sex']
ctime = time.strftime("%Y-%m-%d",time.localtime(comment['ctime']))
content = comment['content']['message']
likes = comment['like']
rcounts = comment['rcount']
username=comment['member']['uname']
content=comment['content']['message']
list=[]
print(floor)
list.append(floor)
list.append(username)
list.append(content)
list.append(ctime)
com.append(list)
在使用Google Chrome浏览器访问抖音网页版的时候,浏览器会向抖音网页版的服务器自动的发送headers请求头。如果没有请求头,抖音网页版的服务器便会返回空值,这是识别爬虫的最基本策略。因此在使用爬虫向抖音网页版发起headers请求的时候,要模拟浏览器向抖音网页版服务器发送请求头headers。每个浏览器的请求头不同,以Google Chrome浏览器为例:按下F12,可在开发者模式下,点击标头,下拉在请求标头中查看headers请求头并复制。

构造自己的请求头:其中cookie,由于不同的用户的cookie不同,可以在开发者模式,控制台中输入document.cookie来获取自己的cookie,然后添加到请求头中。
headers={
'path': '/aweme/v1/web/comment/list/?device_platform=webapp&aid=6383&channel=channel_pc_web&aweme_id=7083293845496073510&cursor=80&count=20&item_type=0&rcFT=&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=1920&screen_height=1080&browser_language=zh-CN&browser_platform=Win32&browser_name=Chrome&browser_version=99.0.4844.51&browser_online=true&engine_name=Blink&engine_version=99.0.4844.51&os_name=Windows&os_version=10&cpu_core_num=8&device_memory=8&platform=PC&downlink=10&effective_type=4g&round_trip_time=0&webid=7082249047388145183&msToken=QWSrXp1LBsAJx5ebu3Xk7Ngwx3nHhQVsOCDXXYdq3e_pA-zZ9fJQjIUvVtcXRt1QsuhdrP-F47kapoadK_ZlMkYZbtgFHK6gO7Yvg5_FOLbVyvxugb_Azp-WjXGZ4w9q&X-Bogus=DFSzswVL9c0ANr98SlqafGUClL9E&_signature=_02B4Z6wo00001OaWiIgAAIDBzRzTTsCKJKzmlowAAFvuTAqjP5WE9ZlERwOQJsQRqw5IfPL3OR3ay.tAxct-hAEFfBTSSxfJPx4JOtmjEkqpbIbXVBKVk9.Q5JXAJ9XdKE.-VfGi5xy9Lrxg23',
'referer': 'https://www.douyin.com/search/%E6%88%90%E9%83%BD%E7%96%AB%E6%83%85%E6%9C%80%E6%96%B0%E6%B6%88%E6%81%AF?source=recom_search&aid=3e537954-a78f-4f98-8bd9-0c8b01cd977b&enter_from=search_result',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'cookie': "你的cookie"
调用解析函数require,通过模拟构造的请求头向目标URL发送requests请求,同时获取请求的状态,即:200为请求成功。在请求成功后,在python中json库中的loads函数可以方便的将字符串的信息转化为字典类型,可以方便的进行数据的处理和提取。接下来通过构建的Html函数和download函数来获取该请求链接中的所有内容,Html将内容通过json.loads转化为字典类型的格式并进行数据的提取。提取出用户ID、用户名、用户评论、用户评论时间以及当前页面的抖音视频的信息。 其中,视频通过you_get库进行下载到本地指定文件夹之中。
- you_get库是一个可以下载全网视频、音频、图像的开源库。它拥有非常强大的功能,能够支持下载的网站非常多,而且使用方法极其简单。仅仅需要一个命令便可实现下载