Copy is All You Need

最近在paper with code刷论文的时候,看到了一个很唬人的文章“《Copy is All You Need》”,遂找来研读研读,发现内容还是很有意思,准备写一篇阅读笔记的,偶然发现了这篇文章作者的采访稿,将文章背后的故事都介绍的挺详细的。于是乎转载一下(不是偷懒)
省流版: 该文提出了一种将生成模型的生成过程由一字一词生成,改为了 “抄一抄” 的方法,即从语料库中抄抄这个片段,再抄抄那个片段,直到输出文本长度达到特定长度或者收到停止信号为止。并且作者通过实验发现这种方法具备更佳强大的泛化能力。同时,相比于字词级别的生成模型,它的推理过程更加高效,因为其每次都抄一个片段(多个token)从而减少了解码的次数。
概述
目前几乎所有语言模型的目标始终如一:即根据 上下文(context),来预测词表上下一个 token 的离散概率分布。
所以模型应该包括两部分,一个prefix编码器跟一个token embedding的集合。Prefix编码器通常采用的transformer结构,可以将prefix转化为一个固定维度的向量表征
而文本生成预测下一个token的概率分布为:
其中 是token w的词嵌入表示,而是预先定义好的词表。基于特定的解码算法,例如beam search或者nucleus sampling,根据整个词表上的概率分布就可以得到下一个token。
而作者带着 “让检索模型打次 C 位” 的执念,将文本生成的过程组织成一个不断从海量语料中搜索文本片段的过程,通过自回归式的文本片段搜索,实现大段文本的生成。一个更为直观的理解是:将语言模型中的下一个词的预测(next token prediction)过程变成了一系列的复制-粘贴操作。作者称这套方法为 CoG (Copy Generator)。
与普通的自回归语言模型相比,这套方法除了能让检索模型打 C 位以外,还有三个有趣的特点:
- 1)相对于单独的词表,CoG 的候选集合包含了大量的语义信息和上下文信息(既片段所在的文档信息也会存储进片段的表示中);
- 2)CoG 的候选集合可以以“即插即用”的方式进行更新,在 domain adaptation 的时候完全可以利用切换候选集合的方式实现一个 One-model-for-all domain 的效果;
- 3)由于片段一般包含多个 tokens,因此 CoG 生成同等长度文本所需的推理次数明显少于普通语言模型。
Copy is All You Need
假设语料包含个文档 ,对于每个文档 ,我可以提取一个长度为的片段 (下文称为 phrase,与原论文对齐),其中 和 代表了这个短语在文档中的起始位置和结束位置。
将源文本集合中的所有短语表示为 ,对于任意给定的句子前缀,目标都是选择一个合适的短语来续写这个前缀。模型会使用一个短语编码器 PhraseEncoder 为每个短语计算一个上下文化表示,那么所有可行的短语会形成一个 Phrase Table: 。在推理时,利用前缀的表示与短语表示的点积来计算前缀与短语的合适程度:
通过这样的方式,生成就变成了一个不断的根据句子前缀在 Phrase Table 中进行 最大内积搜索算法( Maximum Inner Product Search, MIPS) 的过程。另外,有的时候还是会遇到完全没有合适短语可选的情况,因此还是把所有的字嵌入加入到 Phrase Table 中,这些 embeddings 可以被看作是一堆长度为 1 并且没有上下文的 phrase 集合。
CoG 的生成过程如下图所示,大部分时候会选择合适的 phrase 作为 next phrase,如图中红黄蓝三色文本所示。有时候没有合适的 phrase 时,也会选择一些单一 token 进行生成,即如图中黑色中括号内内容。
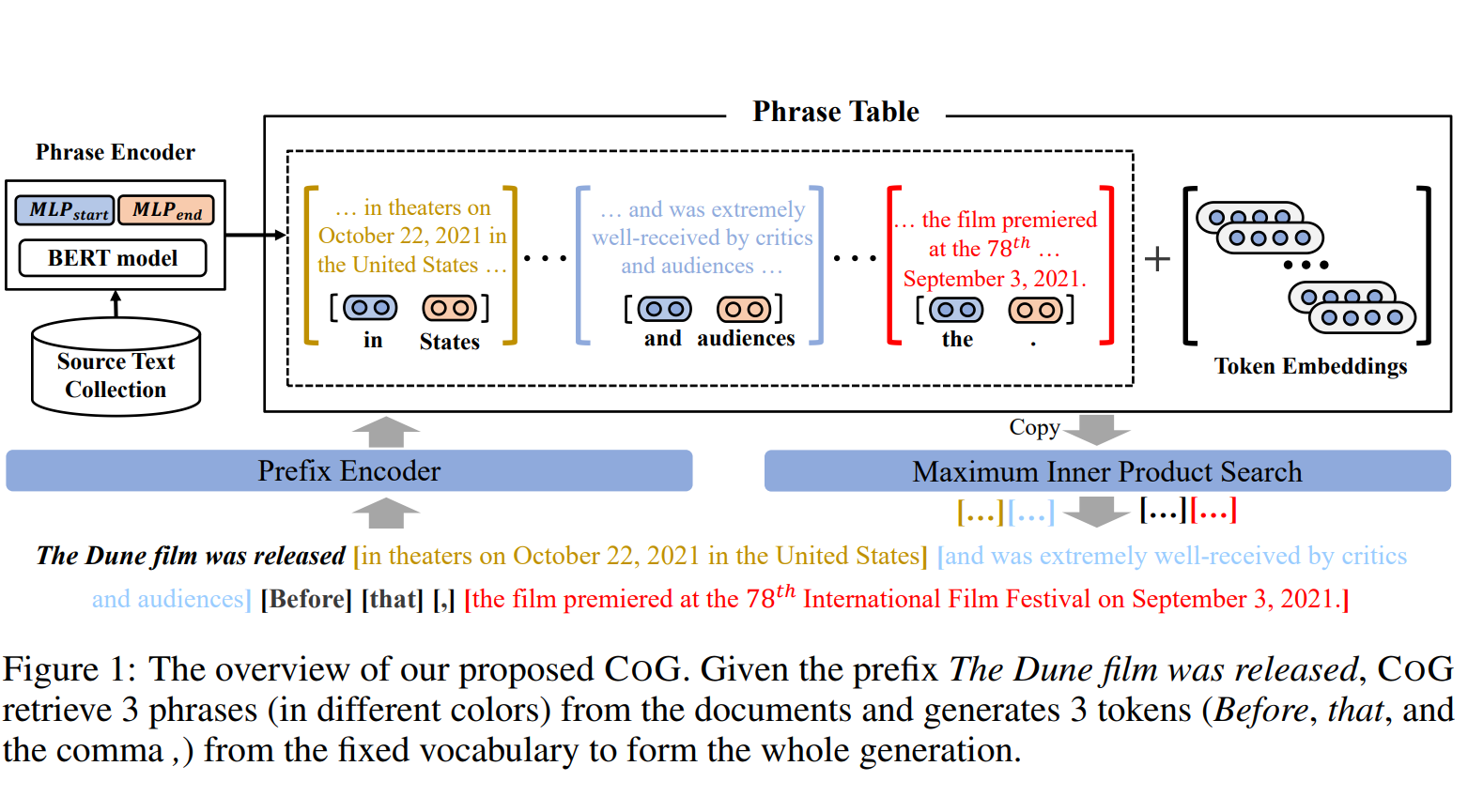
模型结构
模型由三个模块组成:
a) Prefix encoder: 将前面文本 prefix 编码成固定长度的向量表征。这里采用的是标准的 Transformer-decoder only(源码中作者使用的 GPT-2)结构,最终采用 prefix 最后一个 token 的隐层表示作为 prefix 的向量表征。
b) Phrase encoder: 将文本片段转化为固定长度的向量表征。这里采用的是双向Transformer(源码中作者使用的 BERT)结构,给定一个长度为 的文档,利用 Transformer 得到文档 每个位置的向量表征后,通过相互独立的两个 MLP 层, 分别得到以特定位置开始或者结束的向量表征(维度减为384维度):
假设某个 phrase 在该文档 D 中的开始位置跟结束位置分别是 s 跟 e,那么对应的向量表征就是位置 s 的开始表征跟位置 e 的结束向量表征直接拼接得到:
(也就是s和e拼接成784维)
c)一个不依赖于源文本的词表。虽然 CoG 可以从其他文档中 copy,但是为了保持原有的泛化能力,在生成过程同时也会依赖一个固定词表,这里采用的是传统语言模型的词表,每个 token 都可以视为一个长度为 1 的文本片段。当源文本语料中没有合适片段时,生成模型就只能选择固定词表里的token,所以这个词表就非常有用。
这其中 a) 和 c) 与标准语言模型的做法相同,而 b) 是本文的关键:这种获得 phrase 的向量表征方式的优势在于,其一 只需要对文档进行一次编码就可以获得所有文本片段的向量表征,其二在于只需要存储文档每个位置上的向量表征即可,而不需要存储具体的文本片段的向量表征。总而言之, 采用了一种可以在合理代价范围内为任意长度 phrase 进行向量表示并且建立 index 的方式,从而解决之前限制 的关键问题:"检索系统只能召回固定粒度的文档&句子,而无法召回其中未被提前索引的片段"。
训练
在获得源文本语料所有文本片段后,就可以利用自监督的方式训练模型了。CoG 文本生成的每一步都是一个从 Phrase Table(包括固定词表)中进行一次 MIPS 的过程。
假定文档 D 可以被切分为 个 phrase: ,其中 是第 个phrase,假设 是 的可能的源文档, 是 在 中的起始和终止位置,那么 的向量表示可以通过计算得到,上文的表示 是通过 prefix encoder 得到的。
在训练时候 的目标就是通过优化 phrase encoder 和 prefix encoder 的参数,让正确的 next phrase 跟 的语义相似度足够接近,而错误的 next phrases 与 的语义相似度尽量远。采用了对比损失 loss InfoNCE,其中负样本采用的是 in-batch-negative 的方式:
其中 是可选 phrase 集合, 是 token embedding 集合。另外,为了保留模型的 token 级别生成能力, 还有一个标准的自回归模型损失函数:
最终模型的 loss 是前面两者之和:
实验结果
实验一:常规文本生成实验
在标准的文本生成 benchmark,wikitext-103,上测试并对比了各种模型。 以长度为 32 个 token 的 prefix 作为输入,让模型生成长度为 128 的句子补全结果,并与 Vanilla Transformer(GPT2), KNN-LM, RETRO 四种生成模型进行了对比。其中在 MAUVE(跟人工评判高度相关的自动评测方法),Rep(重复性),Diversity(多样性)三个指标上的自动评测如下:
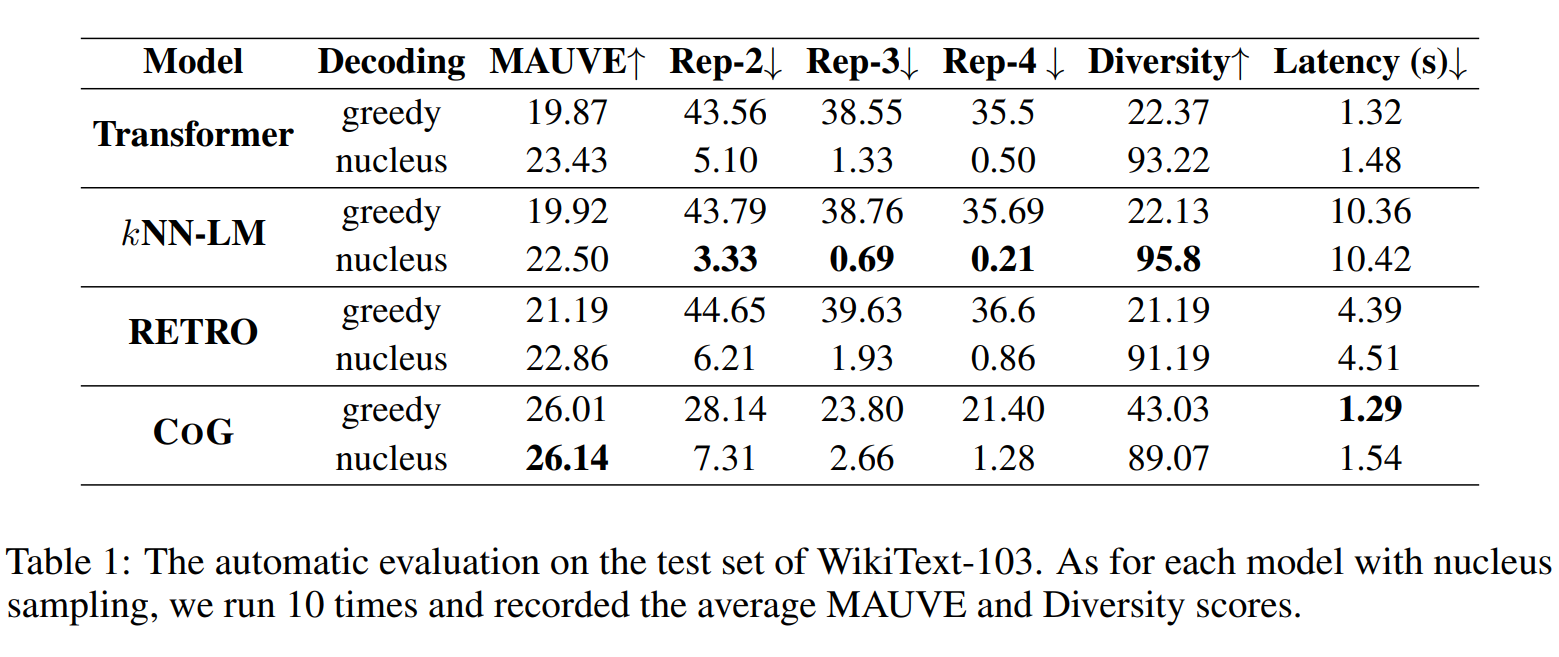
下面展示了一个使用该模型生成句子的示例图,其中红色为从语言模型词表的选择,蓝色为从文档选择的片段:
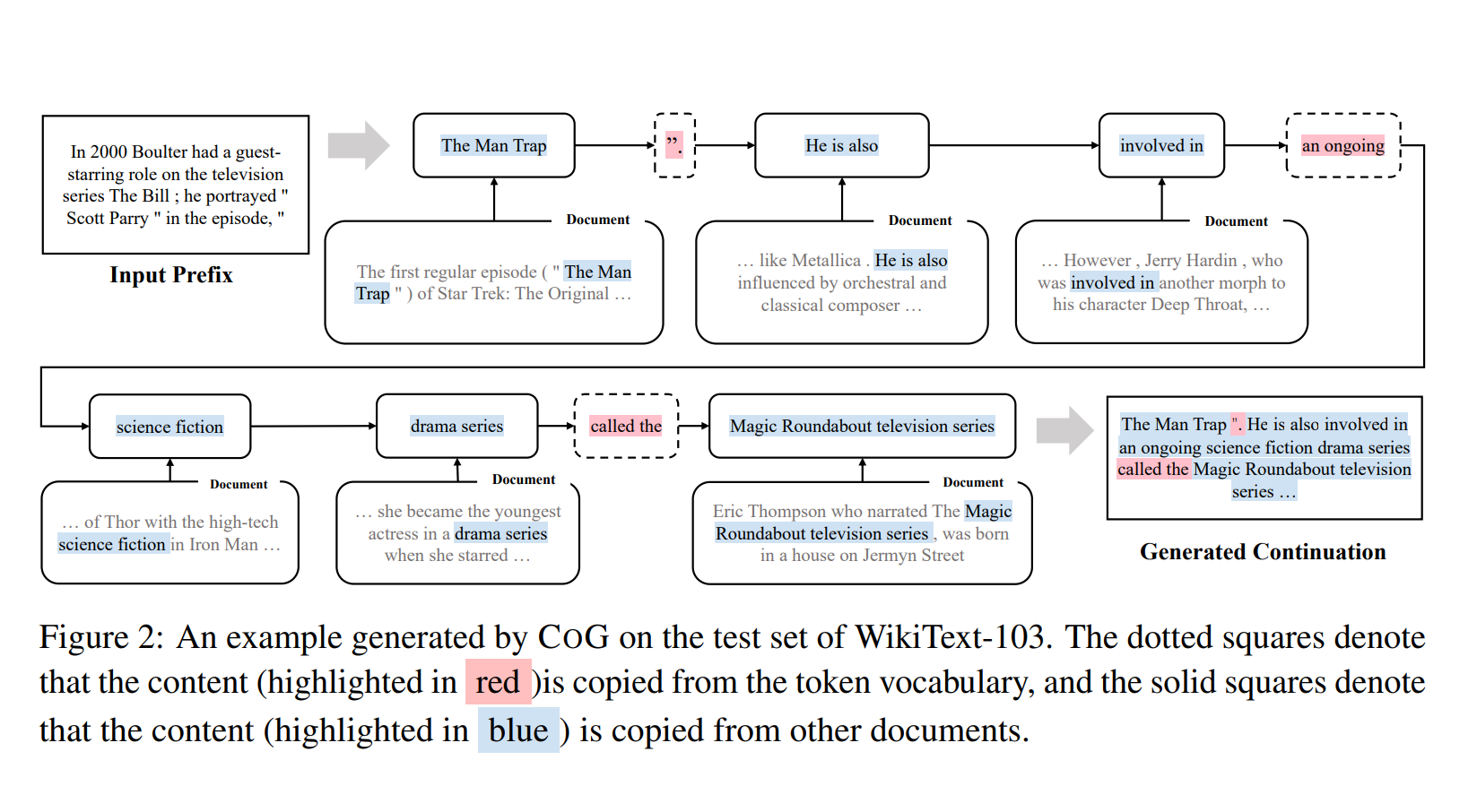
而在人工评测中, 模型也展示出了更为直观的优势

从肉眼评测来说,还有一个有趣的现象值得说明:所有的 baseline 模型都需要基于 sampling 的方法才能避免严重的 degeneration 问题(从表一中两种 decoding 方法的对比可以看得出来),而 CoG 方法则不需要依赖 sampling,即使只用 greedy search 就能取得非常好的效果。
在许多应用中,deterministic 的文本生成能力是非常重要的,能显著降低知识幻想和有害内容的生成,这也是 CoG 方法独特的优势之一。由于篇幅和时间关系, 没有仔细深入的研究为何 CoG 方法能大幅缓解 degeneration 问题产生。
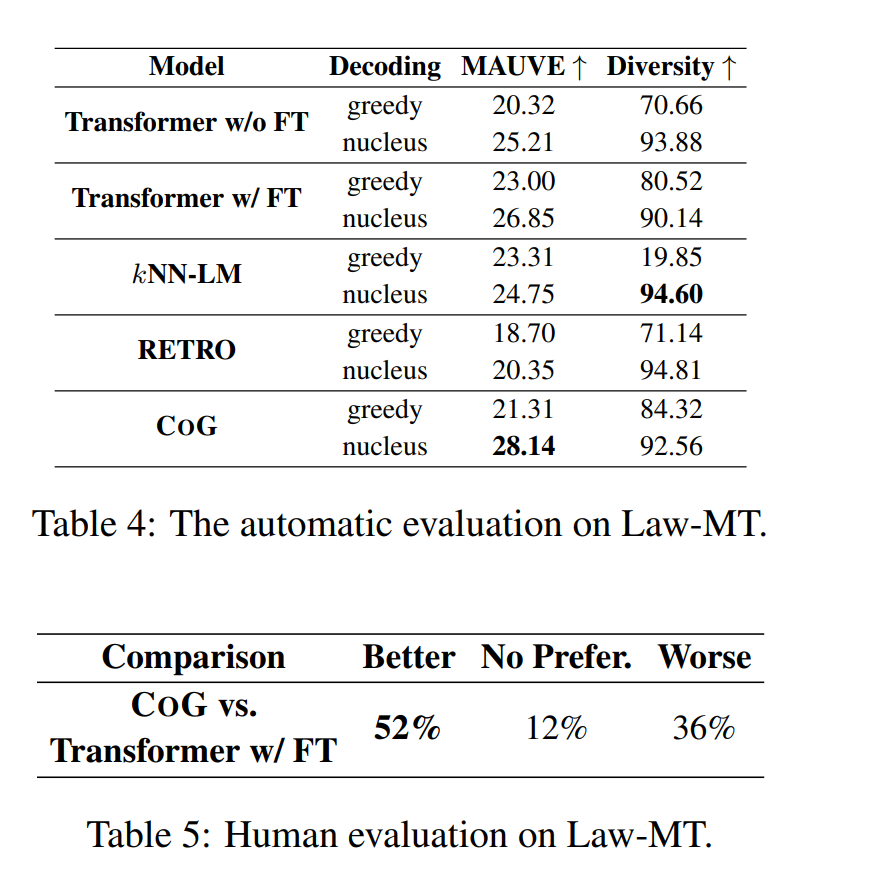
实验二:领域自适应
在之前的论文 Neural Machine Translation with Monolingual Translation Memory 就发现,基于检索增强的生成模型的一大独特优势就是能进行**“即插即用的领域自适应”**。在实验二中, 也测试了各模型的该项能力,对比了在 Law-MT 数据集上 fine-tune 过的 GPT2,和没有 fine-tune 仅仅切换检索 Index 的 CoG。 惊奇的发现,未在特定领域数据训练过的 CoG,竟然能在评测中击败经过了领域自适应训练的 GPT2!
原作者总结:
网络上有一些人指出这套方法有鼓励抄袭的嫌疑,但其实作为这个方法的提出者,我们的目标是让模型能够正确的给自己生成的内容打上 reference,清晰的展示出每一段是来自于哪个文本,构造一个更加白盒的文本生成模型,而不是像现在的黑盒模型,生成出大量有抄袭嫌疑的文本,却甚至没有能力判断哪些是抄袭哪些是原创。
我们在原文中也对道德问题提出了建议:首先,模型使用者需要确保自己拥有检索库中所有内容的版权,比如腾讯新闻->腾讯;网文数据->阅文集团;歌词->腾讯音乐。其次,强烈建议模型使用者显式的为每个片段标记上 reference,即它们的来源,从而避免抄袭问题。