BRIO

BRIO是2022年文本摘要领域SOTA,通过结合了对比学习解决了生成式摘要领域seq2seq自回归中的exposure bias问题
概述
在文本摘要抽取领域,通常利用深度模型监督学习的方式进行文本摘要,这类方法基本都是将摘要抽取看着是seq2seq自回归的生成任务,训练时基于极大似然估计,让模型生成的参考序列的概率最大近似参考摘要序列。
假设一篇文档的标注的参考摘要为 ,模型预测时可能产生多一个候选摘要序列,因为是按最大概率的方式输出,所以模型只能评估出候选序列 出现的概率,并不能衡量侯选摘要序列进行组合后,生成的句子的质量好坏。
可以看出这类方法存在一个明显的问题就是:exposure bias (曝光偏差),也就是说在模型进行训练的时候有参考摘要,然后在预测时候仅仅依靠上一个token,其token并不都跟参考序列中的一样,这样造成模型训练与预测时输入不一致性问题。
如果模型应能够对预测出来的可能的子序列进行准确的质量排序,就能有效的缓解exposure bias的问题。为此,论文提出新的训练范式,将摘要抽取模型训练的目标分布变成不确定的分布,其核心就是利用 对比学习(contrastive learning) 来构建一个评估模型,让候选的分布的也成为优化目标的一部分。
范式
自回归
传统的生成式摘要(Abstractive Summarization)的学习范式。其学习目标是,在给定一篇文档 D 下,训练一个模型 g ,生成一个合适的摘要序列 S ,即:
在极大似然估计(Maximum likelihood estimation, MLE)下,上述模型训练的优化目标为:
其中 个训练样本,为训练的分布对应的参数。对于一个具体的样本来说,采用交叉熵的方式,表示为
其中 为参考序列 的长度, 表示自回归解码的方式,代表j前面的token。每个token的真实值看是否跟参考序列一致而表示为1或0,而在实践操作中,会采用软标签(软标签的解释) 的方式
通过上述训练方式,模型 在预测阶段,采用自回归(autoregressive)产生候选摘要序列,因例举出所有可能的候选结果是很困难的,因此在实践中使用 beam search (beam search的解释) 减少搜索空间,其中搜索中最重要的就是根据前面预测的序列,来估计下一个token出现的概率,即:
公式(6)与公式(3)最大的不同模型在预测下一个token时,用的是之前预测的序列代替参考序列,这就导致出现exposure bias问题:即使模型 训练拟合的很好,一但在预测过程中出现偏移,跟不一致,模型预测的性能就会衰退、下降的问题。
BRIO(Bringing Order to Abstractive Summarization)
上面介绍了当前文本摘要下seq2seq框架处理的步骤,以及存在的曝光偏差的问题。接下来,便是BRIO这篇论文提出的工作:在seq2seq框架基础上,增加一个reference-free Evaluation Model组件。
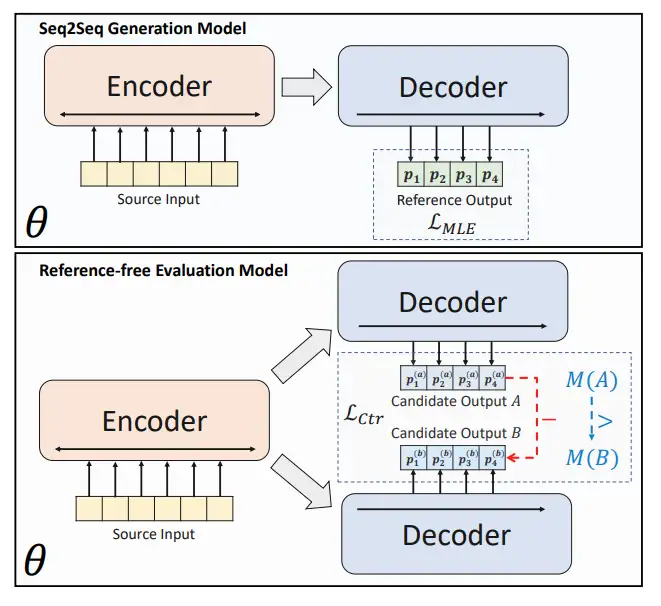
论文分析到:摘要抽取模型 应该具备给更好的候选摘要序列分配更高的概率,然而在MLE训练方式下,是达不到的。其反例就是:当一个模型获得MLE loss为0的时候,那应该在推测时,跟参考序列不一样的候选序列的概率应该都为0,然后实际中是不存在的(因为exposure bias的存在)。
因此,论文接着换一种假设:候选摘要出现的概率应该与它们的一个自动度量指标M密切相关。虽无法例举可能生成的所有候选摘要,然只需要能对产生的最可能的候选摘要(如来自beam search)进行准确的排序就可以。
为此,论文为达到上述想法,将公式(5)进行了微调,实现候选序列的排序
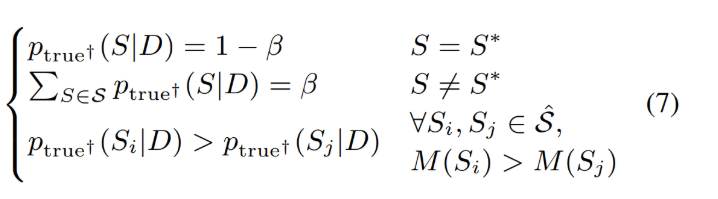
也就是:按照label smoothing的思想给每候选序列赋予一个概率值,且两个序列的概率值大小与其在评价指标M下是一致的,论文采用ROUGE作为M评价指标的一种形式,来评估候选摘要与参考摘要相似分数。这样有了对生成的候选摘要进行排序的方法与目标,那怎么训练模型也朝这个方向优化或者说受益。为接近这个问题,论文引入对比损失,将排序后的候选摘要形成对比样本,参与目标优化,即为:
其中 为长度正则化的解码概率, 为对比损失函数,为候选摘要排序后的索引,越小意味越好即 当 j>i, 。其中 ,为排名次数的边际调整参数。
最后,论文就将文本摘要抽取任务变成一个多任务学习框架,即将对比损失函数以一定权重和交叉熵进行结合最后最终的损失函数进行优化:
实验结果
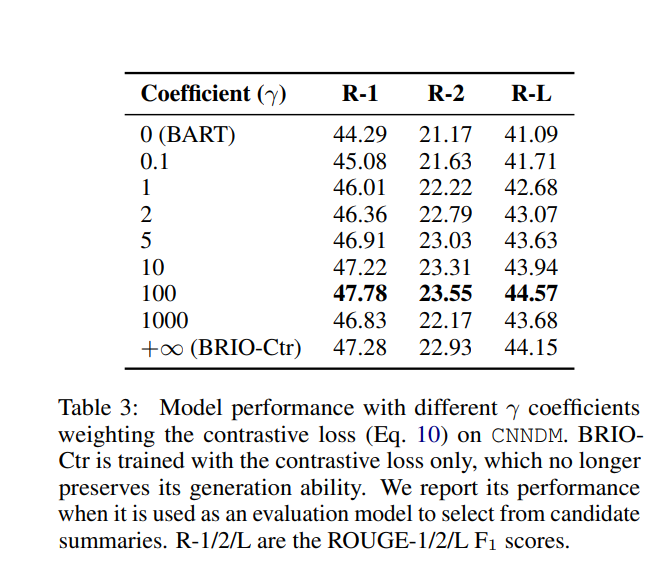
作者通过在CNNDM数据集通过BART模型进行实验,γ值设为100是最优值,获得了最高的ROUGE评分。
总结
作者提出了一个新的范式:对摘要生成的候选序列进行排序打分,形成对比样本,进而转化成对比损失,加入摘要抽取主任务中,形成多任务学习框架。提升了模型进行摘要抽取的效果。
参考文献
Bringing Order to Abstractive Summarization
BRIO:为抽象总结带来秩序 BRIO: Bringing Order to Abstractive Summarization
BRIO:给文本摘要抽取带来排序
BRIO:抽象文本摘要任务新的SOTA模型