BERT

BERT(Bidirectional Encoder Representation from Transformers),BERT模型在结构上简单来讲就是一个多层的transformer的Encoder
概述
Transformer模型自提出以来,已经在很多地方都取得了不错的成果,尤其是在nlp领域,它取得的成果是令人瞩目的,相比于之前的模型,transformer模型的attention机制更够更好地学习到句子当中单词与单词之间的联系,从而能够结合上下文语境来提高准确度。
更重要的是,transformer的这种attention机制是一种底层的方法,基于它可以构造出一些新的模型,而这些模型在nlp中往往有着出色的表现,BERT模型就是其中之一。
对于Transformer模型的结构,可以参考上一篇文章:Transformer | 威伦特 (voluntexi.github.io)
BERT的架构
BERT的模型架构是基于Vaswani et al. (2017) 中描述的原始实现multi-layer bidirectional Transformer编码器,并在tensor2tensor库中发布。
论文将Transformer blocks表示为L,将隐藏大小表示为H,将self-attention heads的数量表示为A。在所有情况下,将 feed-forward 的大小设置为 4H,即H = 768时为3072,H = 1024时为4096。论文主要报告了Bert两种模型大小的结果:

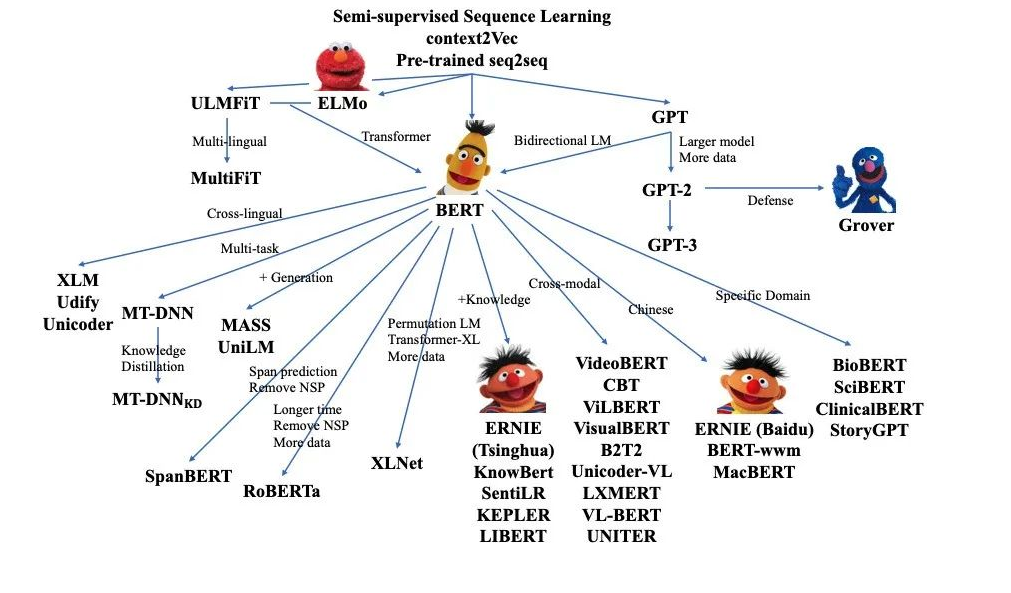
论文选择了BERT LARGE ,它与OpenAI GPT具有相同的模型大小。然而,重要的是,BERT 使用了双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能处理其左侧的上下文。研究团队注意到,在文献中,双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,因为它可以用于文本生成。BERT,OpenAI GPT和ELMo之间的比较如图
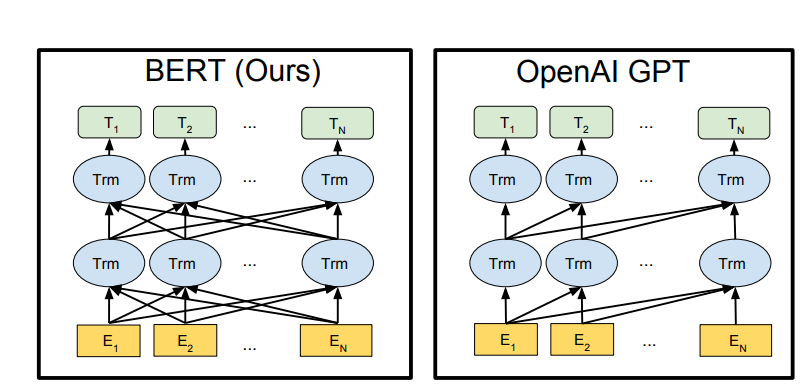
Embedding
BERT的embedding由token embedding、segment embedding、position embedding进行求和组成
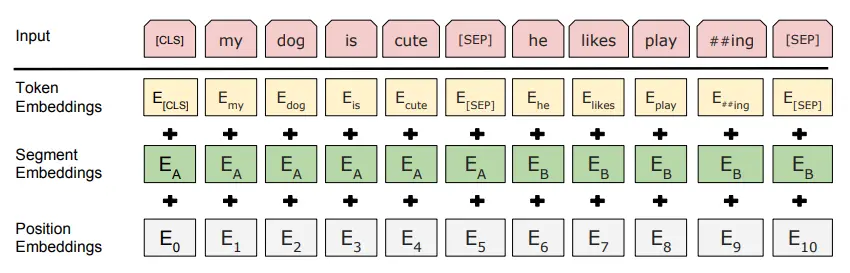
在句子开头和结尾加入 [CLS] 和 [SEP] 特殊符号,组成了输入的句子。
BERT对句子的长度进行了大小为512的限制,目前对这个问题的处理的方法有:
- head:保存前 510 个 token (留两个位置给 [CLS] 和 [SEP] )
- tail :保存最后 510 个token
- head+tail :选择前128个 token 和最后382个 token(文本在800以内)或者前256个token+后254个token(文本大于800tokens)
其中:
- Token Embeddings是词向量,对每个字符进行768维向量化
- Segment Embeddings用来区别两个句子,第一个句子全为0,第二个句子全为1,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,是通过不断学习得出的
预训练阶段
BERT是一个多任务模型,它的任务是由两个自监督任务组成,即MLM(masked language model )和NSP(next sentence prediction)。
Masked Language Model
Masked Language Model(MLM)和核心思想取自Wilson Taylor在1953年发表的一篇论文。所谓MLM是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。
在BERT的实验中,15% 的WordPiece Token会被随机Mask掉。
在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,80%的时候会直接替换为[Mask],10%的时候将其替换为其它任意单词,10%的时候会保留原始Token。
-
80%:
my dog is hairy -> my dog is [mask] -
10%:
my dog is hairy -> my dog is apple -
10%:
my dog is hairy -> my dog is hairy
损失函数: 将模型被MLM掉的词向量,与正确的词向量进行交叉熵
Next Sentence Prediction
Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50% 保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
损失函数: 将模型最后输出的[CLS]向量,接一个线性层(768*2)进行一个二分类任务,与正确结果进行交叉熵
模型的损失函数
MLM和NSP是一起训练的,总体的损失函数=MLM损失函数+NSP损失函数。
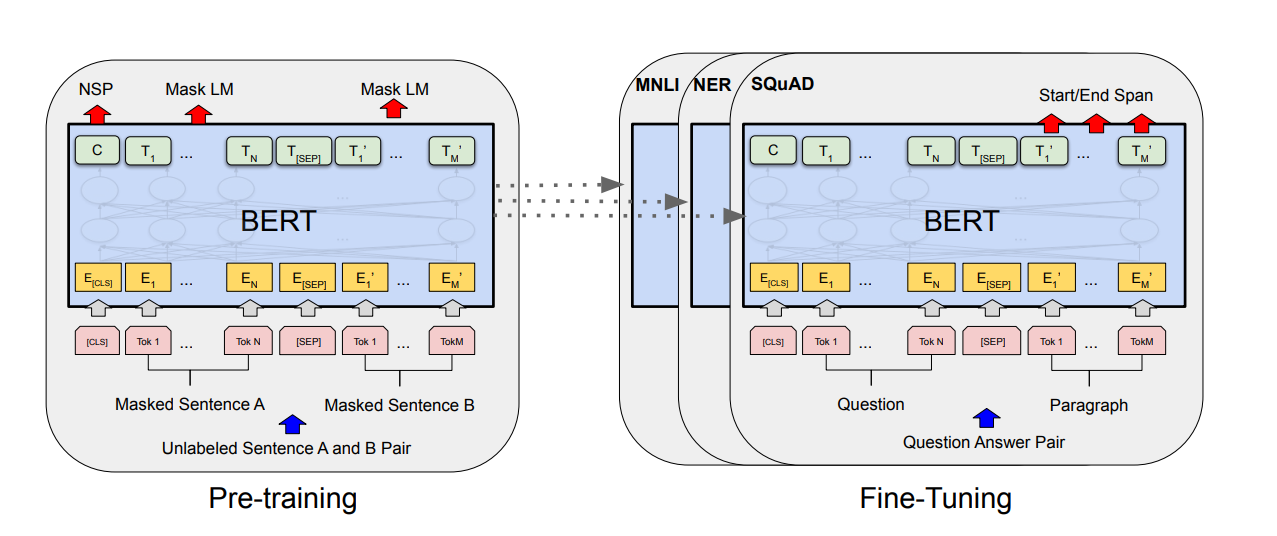
Fine-tuning
Bert模型在预训练完成后,对模型进行微调,带入对应NLP任务的数据集再进行训练,就完成了Fine-tuning过程。
-
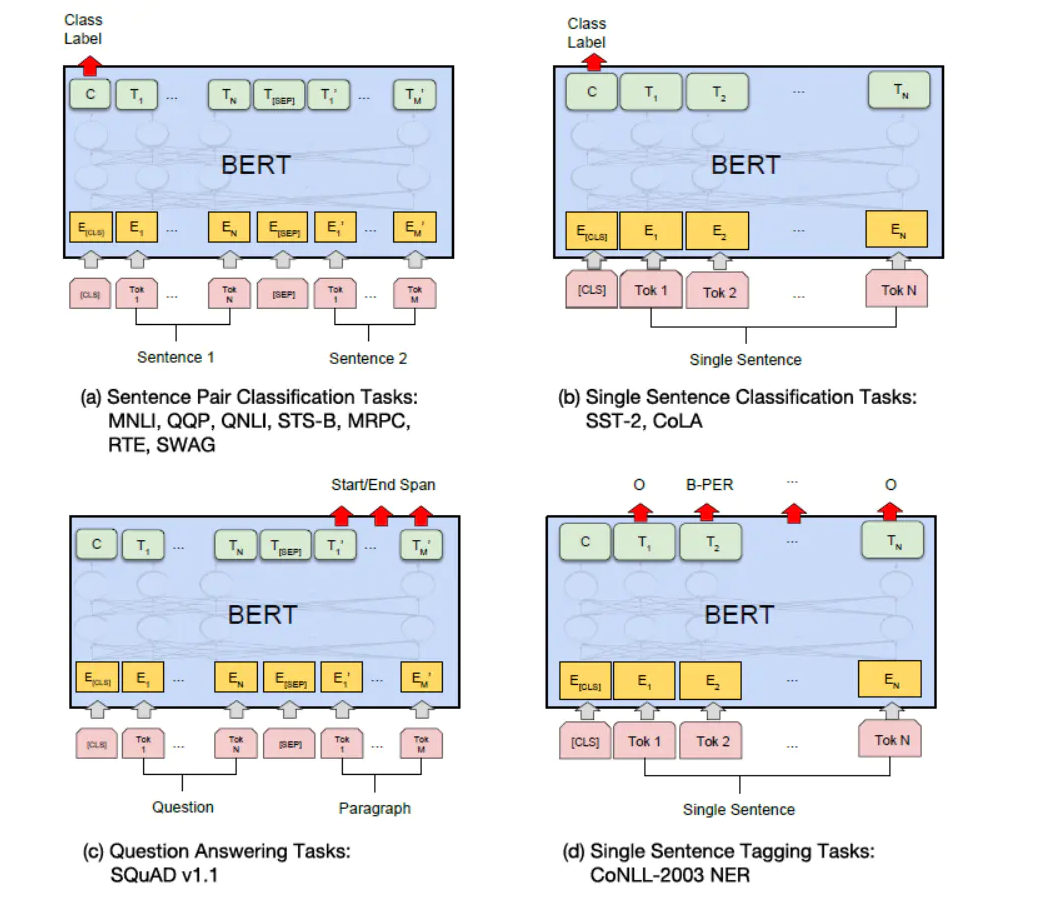
两个句分类任务: 例如自然语言推断 (MNLI),句子语义等价判断 (QQP) 等,只需要将两个句子传入 BERT,然后使用 [CLS] 的输出值 C 进行句子对分类。
-
单个句子分类任务: 例如句子情感分析 (SST-2),判断句子语法是否可以接受 (CoLA) 等,只需要输入一个句子,无需使用 [SEP] 标志,然后也是用 [CLS] 的输出值 C 进行分类。
-
问答任务: 样本是语句对 (Question, Paragraph),Question 表示问题,Paragraph 是问题的答案。而训练的目标是在 Paragraph 找出答案的起始位置 (Start,End)。将 Question 和 Paragraph 传入 BERT,然后 BERT 根据 Paragraph 所有单词的输出预测 Start 和 End 的位置。
-
单个句子标注任务: 例如命名实体识别 (NER),输入单个句子,然后根据 BERT 对于每个单词的输出 T 预测这个单词的类别,是属于 Person,Organization,Location,Miscellaneous 还是 Other (非命名实体)。
BERT家族
现在几个出名的预训练模型基本都是Transformer架构,了解了Transformer其他模型就能够比较快的掌握。