B站视频和用户评论爬虫

本文将详细的讲述关于B站网络爬虫的实现过程。
概述一下,其实B站的爬取过程就是:
对哔哩哔哩视频页面进行oid信息的提取,而oid的信息又与原网址的BV信息有关联,可以通过原网站进行解析出oid信息,然后在抖音爬虫的基础上即可完成哔哩哔哩爬虫的信息提取任务。
B站网站分析
首先,我们找到想要抓取的对应的哔哩哔哩视频,按下F12,在开发者模式中,进行观察评论、视频等信息的存储方式。发现哔哩哔哩视频的相关信息也是通过动态显示,且通过提取请求头中的有效信息,最终请求头为:
https://api.bilibili.com/x/v2/reply/main?&type=1&oid=725453240&mode=3
通过与哔哩哔哩网址其他视频评论进行对比,发现仅有oid参数有所不同,也就是说,每个视频下面对应有不同的oid,只需要找到视频的oid便可以实现视频相关信息的提取。
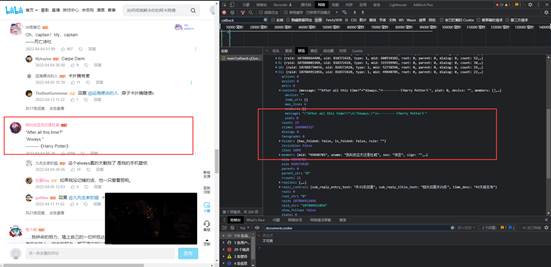
同时进一步发现,可以在请求地址后加入&page就可以进行翻页操作。
由此,哔哩哔哩的用户评论相关信息也就成功解析出来,剩下操作需要找到视频链接和oid之间的联系,而通过视频链接进行解析出oid信息。
而通过对视频网址源代码的分析,发现oid存在其中,不但如此,同样在网站源代码中找到了哔哩哔哩视频的地址。
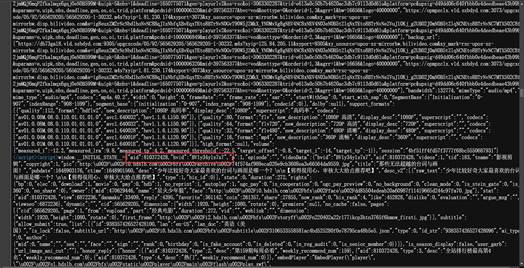
哔哩哔哩爬虫的实现
构造请求头向哔哩哔哩模拟requests请求,提取网站存储的用户信息:
通过构造BilibiliCrawler函数,并通过构造形参来接受请求的URL。并通过&page增加1的操作来进行翻页。
在使用Google Chrome浏览器访问哔哩哔哩的时候,浏览器页会向哔哩哔哩网页版的服务器自动的发送headers请求头。这时候可以在开发者模式中查看请求头,查看方式和上一文抖音爬虫中方式相同,具体标头如图所示。
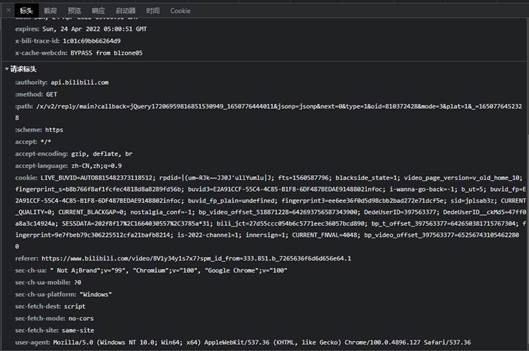
Hearders的请求头如下
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Connection': 'keep-alive',
'cookie':"填上自己的cookie"
}
接下来就可以对网站的数据进行获取,将数据通过一个数组保存下来
def Html(html):
# 获取所需内容
s=json.loads(html)
for i in range(20):
comment=s['data']['replies'][i]
floor = comment['member']['mid']
sex=comment['member']['sex']
ctime = time.strftime("%Y-%m-%d",time.localtime(comment['ctime']))
content = comment['content']['message']
likes = comment['like']
rcounts = comment['rcount']
username=comment['member']['uname']
content=comment['content']['message']
list=[]
print(floor)
list.append(floor)
list.append(username)
list.append(content)
list.append(ctime)
com.append(list)
biliVideo函数来获取当前页面下的哔哩哔哩视频,通过对哔哩哔哩源代码的的解析,分析出视频的网址。下载视频的函数bliVideo函数代码如下:
url=url.partition('?')[0]
print(url)
print('获取中')
response = requests.get(url, headers).text
pattern = '<script>window\.__playinfo__=(.*?)</script>'
list = re.findall(pattern, response, re.S)
list_json = json.loads(list[0])
title_pattern = '<span class="tit">(.*?)</span>'
try:
title = re.findall(title_pattern, response, re.S)[0]
except:
title = 'B站未知视频'
video_url = list_json['data']['dash']['video'][0]['baseUrl']
volume_url = list_json['data']['dash']['audio'][0]['baseUrl']
print(title[0:6] + '获取成功,准备下载')
video_headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.37',
'cookie': ''
}
video_param = {
'accept_description': '360P 流畅',
'accept_quality': 60,
}
print("视频url:"+video_url)
print('-----开始下载-----')
video = requests.get(url=video_url, headers=video_headers, params=video_param).content
# with open('../video/'+r'.\B站{}.mp4'.format(title), 'wb') as f:
with open('../video/BVideo.mp4', 'wb') as f:
f.write(video)
值得注意的是,哔哩哔哩相对于爬虫的环境相对较为轻松,但是其中在抓取数据的时候不要太快、太频繁,通过time.sleep()来进行暂停,防止被反爬虫程序所识别而封掉IP。
完整代码
import time
import xlwt
import requests
import re
import json
'''
功能:爬取B站ID、用户名、用户评论
使用方法:
在def BilibiliCrawler(Old_url)函数中 输入爬取的网站链接 即可实现信息的爬取和视频的下载,下载路径为video/Bvideo.mp4
在爬取完毕后会将数据以EXCEL表的形式存入当前目录,命名为:BilibiliComment.xls
'''
com=[]
def require(url):
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/39.0.2171.95 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'cookie': ""
}
try:
r=requests.get(url,headers=headers)
r.raise_for_status()
print(url)
return r.text
except requests.HTTPError as e:
print(e)
except requests.RequestException as e:
print(e)
except:
print("Unknow error")
def Html(html):
# 获取所需内容
s=json.loads(html)
for i in range(20):
comment=s['data']['replies'][i]
floor = comment['member']['mid']
sex=comment['member']['sex']
ctime = time.strftime("%Y-%m-%d",time.localtime(comment['ctime']))
content = comment['content']['message']
likes = comment['like']
rcounts = comment['rcount']
username=comment['member']['uname']
content=comment['content']['message']
list=[]
print(floor)
list.append(floor)
list.append(username)
list.append(content)
list.append(ctime)
com.append(list)
def save_afile(alls,filename):
"""将一个评论数据保存在一个excle"""
f=xlwt.Workbook()
sheet1=f.add_sheet(u'sheet1',cell_overwrite_ok=True)
sheet1.write(0,0,'Comment_ID')
sheet1.write(0,1,'Comment_Name')
sheet1.write(0,2,'Comment_Content')
sheet1.write(0,3,'Comment_Time')
i=1
for data in alls:
for j in range(len(data)):
sheet1.write(i,j,data[j])
# print(i,j,data[j])
i=i+1
f.save(filename+'.xls')
def biliVideo(url):
headers = {
'Referer': 'https://www.bilibili.com/video/BV1bK4y19743?spm_id_from=333.5.b_64616e63655f6f74616b75.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
url=url.partition('?')[0]
print(url)
print('获取中')
response = requests.get(url, headers).text
pattern = '<script>window\.__playinfo__=(.*?)</script>'
list = re.findall(pattern, response, re.S)
list_json = json.loads(list[0])
title_pattern = '<span class="tit">(.*?)</span>'
try:
title = re.findall(title_pattern, response, re.S)[0]
except:
title = 'B站未知视频'
video_url = list_json['data']['dash']['video'][0]['baseUrl']
volume_url = list_json['data']['dash']['audio'][0]['baseUrl']
print(title[0:6] + '获取成功,准备下载')
video_headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.37',
'cookie': "“
}
video_param = {
'accept_description': '360P 流畅',
'accept_quality': 60,
}
print("视频url:"+video_url)
print('-----开始下载-----')
video = requests.get(url=video_url, headers=video_headers, params=video_param).content
# with open('../video/'+r'.\B站{}.mp4'.format(title), 'wb') as f:
with open('../video/BVideo.mp4', 'wb') as f:
f.write(video)
# print('视频下载中')
# audio = requests.get(url=volume_url, headers=video_headers).content
# with open('./audio.mp3', 'wb') as f:
# f.write(audio)
# print('-----视频合成中-----')
# print('-----请耐心等候-----')
# video_path = './B站视频.mp4'
# videoclip = VideoFileClip(video_path)
# audio_path = './audio.mp3'
# audio = AudioFileClip(audio_path)
# videoclip_3 = videoclip.set_audio(audio)
# path = r'.\B站{}.mp4'.format(title[0:6])
# videoclip_3.write_videofile(path)
# import os
# if os.path.exists(video_path):
# os.remove(video_path)
# else:
# pass
# if os.path.exists(audio_path):
# os.remove(audio_path)
# print('success!!!')
# else:
# pass
return title
def getOid(url):
bv = re.findall('https://www.bilibili.com/video/(.*?)\?', url, re.S)[0]
print(bv)
resp = requests.get("https://www.bilibili.com/video/" + bv)
obj = re.compile(f'"aid":(?P<id>.*?),"bvid":"{bv}"') # 在网页源代码里可以找到id,用正则获取到
oid = obj.search(resp.text).group('id')
return oid
def BilibiliCrawler(url):
videoName=biliVideo(url)
oid=getOid(url)
print(oid)
Old_url = 'https://api.bilibili.com/x/v2/reply?type=1&sort=1&oid=' + str(oid) + '&pn='
e=0
page=1
while e == 0 :
url = Old_url+str(page)
try:
html=require(url)
Html(html)
page=page+1
if page%10 == 0:
time.sleep(3)
if page>30:
break
except:
e=1
save_afile(com,"bilibili_comment")
return videoName