Agent 三大构建范式解析

今年年初Manus引爆了Agent概念,随着越来越多的厂商开发发布自己的Agent,Agent逐渐的走进了大众的视野,今年可谓是Agent元年。而对于我们想要尝试构建自己的Agent,除开从Coze、Dify、星辰智能体平台等平台构建,还可以通过调用API通过提示词来进行进行构建。(微调不起了...)为了让大家更好的做出自己的Agent,本文主要讲解构建Agent 的经典三大范式:ReAct、Plan-and-Solve和Relection。
概述
一个现代的Agent,其核心能力在于能将大语言模型的推理能力与外部世界联通。它能够自主地理解用户意图、拆解复杂任务,并通过调用代码解释器、搜索引擎、API等一系列“工具”,来获取信息、执行操作,最终达成目标。 然而,Agent并非万能,它同样面临着来自大模型本身的“幻觉”问题、在复杂任务中可能陷入推理循环、以及对工具的错误使用等挑战,这些也构成了智能体的能力边界。
为了更好地组织智能体的“思考”与“行动”过程,业界涌现出了多种经典的架构范式。本文将聚焦于其中最具代表性的三种经典构建范式:
-
ReAct (Reasoning and Acting): 一种将“思考”和“行动”紧密结合的范式,让智能体边想边做,动态调整。
-
Plan-and-Solve: 一种“三思而后行”的范式,让智能体首先生成一个完整的行动计划,然后严格执行。
-
Reflection: 一种赋予智能体“反思”能力的范式,通过自我批判和修正来不断优化结果。
ReAct
ReAct框架[1]于2022年首次提出,在ReAct诞生之前,主流的方法可以分为两类:
-
一类是“纯思考”型,如思维链 (Chain-of-Thought),它能引导模型进行复杂的逻辑推理,但无法与外部世界交互,容易产生事实幻觉;
-
另一类是“纯行动”型,模型直接输出要执行的动作,但缺乏规划和纠错能力。
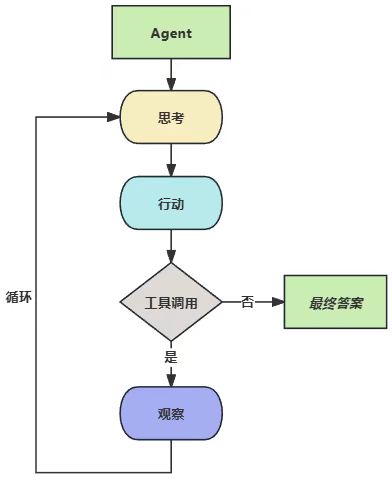
ReAct 架构的则将语言模型的思考能力与行动能力结合起来,通过思考、行动、观察形成一个协同系统,让思考指导行动,而行动的结果又反过来修正思考,知道它在思考中认为已经找到了最终的答案。
-
Thought(思考): Agent会分析当前情况、分解任务、制定下一步计划,或者反思上一步的结果。
-
Action (行动): 这是智能体决定采取的具体动作,通常是调用一个外部工具,
-
Observation (观察): 这是执行Action 后从外部工具返回的结果。
如下图所示:
这种机制特别适用于以下场景:
-
需要外部知识的任务:如查询实时信息(天气、新闻、股价)、搜索专业领域的知识等。
-
需要精确计算的任务:将数学问题交给计算器工具,避免LLM的计算错误。
-
需要与API交互的任务:如操作数据库、调用某个服务的API来完成特定功能。
实现
以构建网页搜索Agent为例:
首先需要提供一个网页搜索工具,这里选用SerpApi,它能直接返回Google搜索结果
- 安装该库
pip install google-search-results
- 前往SerpApi官网注册账户,获取API密钥,然后构建
search工具函数
from serpapi import SerpApiClient
def search(query: str) -> str:
"""
解析搜索结果,优先返回直接答案或知识图谱信息。
"""
params = {
"engine": "google",
"q": query,
"api_key": "your_api_key",
"gl": "cn", # 国家代码
"hl": "zh-cn", # 语言
}
client = SerpApiClient(params)
results = client.get_dict()
if "answer_box_list" in results:
return "\n".join(results["answer_box_list"])
if "answer_box" in results and "answer" in results["answer_box"]:
return results["answer_box"]["answer"]
if "knowledge_graph" in results and "description" in results["knowledge_graph"]:
return results["knowledge_graph"]["description"]
if "organic_results" in results and results["organic_results"]:
# 如果没有直接答案,则返回前三个有机结果的摘要
snippets = [
f"[{i+1}] {res.get('title', '')}\n{res.get('snippet', '')}"
for i, res in enumerate(results["organic_results"][:3])
]
return "\n\n".join(snippets)
return f"没有找到关于 '{query}' 的信息。"
- 构建工具执行器
class ToolExecutor:
def __init__(self):
self.tools: dict[str, dict[str, any]] = {}
def registerTool(self, name: str, description: str, func: callable):
self.tools[name] = {"description": description, "func": func}
print(f"工具 '{name}' 已注册。")
def getTool(self, name: str) -> callable:
return self.tools.get(name, {}).get("func")
def getAvailableTools(self) -> str:
return "\n".join(
[f"- {name}: {info['description']}" for name, info in self.tools.items()]
)
- 为Agent设计提示词:提示词是整个 ReAct 机制的核心,它为大语言模型提供了行动的操作指令。
REACT_PROMPT_TEMPLATE = """
请注意,你是一个有能力调用外部工具的智能助手。
可用工具如下:
{tools}
请严格按照以下格式进行回应:
Thought: 你的思考过程,用于分析问题、拆解任务和规划下一步行动。
Action: 你决定采取的行动,必须是以下格式之一:
- `tool_name[tool_input]`:调用一个可用工具。
- `Finish[最终答案]`:当你认为已经获得最终答案时。
- 当你收集到足够的信息,能够回答用户的最终问题时,你必须在Action:字段后使用 finish(answer="...") 来
输出最终答案。
现在,请开始解决以下问题:
Question: {question}
History: {history}
"""
- 构建
ReActAgent类,实现ReAct框架,大模型调用采用的siliconflow的API
import re
from langchain_openai import OpenAI
class ReActAgent:
def __init__(
self,
tool_executor: ToolExecutor,
max_steps: int = 5,
):
self.llm_client = OpenAI(
model="Qwen/Qwen2.5-7B-Instruct",
temperature=0.5,
base_url="https://api.siliconflow.cn/v1",
api_key="your_api_key",
streaming=False,
)
self.tool_executor = tool_executor
sel.max_steps = max_steps
self.history = []
def run(self, question: str) -> str:
self.history = [] # 每次运行时重置历史记录
current_step = 0
while current_step < self.max_steps:
current_step += 1
print(f"--- 第 {current_step} 步 ---")
# 格式化提示词
tools_desc = self.tool_executor.getAvailableTools()
history_str = "\n".join(self.history)
prompt = REACT_PROMPT_TEMPLATE.format(
tools=tools_desc, question=question, history=history_str
)
response_text = self.llm_client.invoke(prompt)
thought, action = self._parse_output(response_text)
if thought:
print(f"思考: {thought}")
if not action:
print("警告:未能解析出有效的Action,流程终止。")
break
# 执行Action
if action.startswith("Finish"):
# 如果是Finish指令,提取最终答案并结束
final_answer = re.match(r"Finish\[(.*)\]", action).group(1)
print(f"最终答案: {final_answer}")
return final_answer
tool_name, tool_input = self._parse_action(action)
if not tool_name or not tool_input:
# 无效Action格式
continue
print(f"行动: {tool_name}[{tool_input}]")
tool_function = self.tool_executor.getTool(tool_name)
if not tool_function:
observation = f"错误:未找到名为 '{tool_name}' 的工具。"
else:
observation = tool_function(tool_input) # 调用真实工具
print(f" 观察: {observation}")
self.history.append(f"Action: {action}")
self.history.append(f"Observation: {observation}")
print("已达到最大步数,流程终止。")
return None
def _parse_output(self, text: str) -> tuple[str | None, str | None]:
"""解析LLM的输出,提取Thought和Action。"""
thought_match = re.search(r"Thought: (.*)", text)
action_match = re.search(r"Action: (.*)", text)
thought = thought_match.group(1).strip() if thought_match else None
action = action_match.group(1).strip() if action_match else None
return thought, action
def _parse_action(self, action_text: str) -> tuple[str | None, str | None]:
"""解析Action字符串,提取工具名称和输入。"""
match = re.match(r"(\w+)\[(.*)\]", action_text)
if match:
return match.group(1), match.group(2)
return None, None
总结
ReAct 的优点
-
高可解释性:ReAct 最大的优点之一就是透明。通过输出思考过程,我们可以清晰地看到智能体每一步的“心路历程”——它为什么会选择这个工具,下一步又打算做什么。这对于理解、信任和调试智能体的行为至关重要。
-
动态规划与纠错能力:与一次性生成完整计划的范式不同,ReAct 是“走一步,看一步”。它根据每一步从外部世界获得的观察结果来动态调整后续的过程。如果上一步的搜索结果不理想,它可以在下一步中修正搜索词,重新尝试。
-
工具协同能力:ReAct 范式天然地将大语言模型的推理能力与外部工具的执行能力结合起来。LLM 负责运筹帷幄(规划和推理),工具负责解决具体问题(搜索、计算),二者协同工作,突破了单一 LLM 在知识时效性、计算准确性等方面的固有局限。
不足:
-
对LLM自身能力的强依赖:ReAct 流程的成功与否,高度依赖于底层 LLM 的综合能力。如果 LLM 的逻辑推理环节产生错误的规划,或者在能力、指令遵循能力或格式化输出能力不足,就很容易在节生成不符合格式的指令,导致整个流程出现偏差。
-
执行效率问题:完成一个任务通常需要多次调用 LLM。每一次调用都伴随着网络延迟
和计算成本。对于需要很多步骤的复杂任务,这种串行的“思考-行动”循环可能会导致较高的总耗时和费用。 -
对提示词的过分依赖:整个机制的稳定运行建立在一个精心设计的提示词模板之上。模板中的任何微小变动,甚至是用词的差异,都可能影响 LLM 的行为。此外,并非所有模型都能持续稳定地遵循预设的格式,这增加了在实际应用中的不确定性。
-
可能陷入局部最优:步进式的决策模式意味着智能体缺乏一个全局的、长远的规划。它可能会选择一个看似正确但长远来看并非最优的路径,甚至在某些情况下陷入“原地打转”的循环中。
Plan-And-Solve
Plan-And-Solve由Lei Wang在2023年提出[2],名字就很直观的展示出了该方法的思想,即对任务先进行规划,将任务拆分成多个清晰、分步骤的计划,随后再严格按照计划中的步骤,逐一执行。如下图所示:
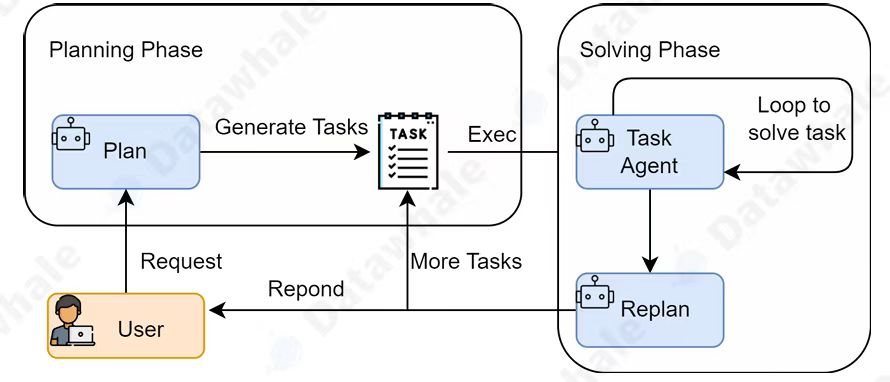
Plan-and-Solve 尤其适用于那些结构性强、可以被清晰分解的复杂任务,例如:
-
多步数学应用题:需要先列出计算步骤,再逐一求解。
-
需要整合多个信息源的报告撰写:需要先规划好报告结构(引言、数据来源A、数据来源B、总结),再逐一填充内容。
-
代码生成任务:需要先构思好函数、类和模块的结构,再逐一实现。
实现
实现Plan-and-Solve,我们需要调用两次大模型,第一次通过PLAN提示词让大模型生成对应的计划,然后再调用EXECUTOR提示词让大模型逐步执行对应的计划。
- 构建PLAN和EXECUTOR的提示词
PLANNER_PROMPT_TEMPLATE = """
你是一个顶级的AI规划专家。你的任务是将用户提出的复杂问题分解成一个由多个简单步骤组成的行动计划,针对数学题不需要进行计算。
请确保计划中的每个步骤都是一个独立的、可执行的子任务,并且严格按照下面的逻辑顺序排列。
注意:你的输出有且仅有必须是一个Python列表,其中每个元素都是一个描述子任务的字符串
问题:{question}
请严格按照以下格式输出你的计划,```python与```作为前后缀是必要的:
```python
[
"提供的步骤",
"提供的步骤",
"提供的步骤",
...
]
"""
EXECUTOR_PROMPT_TEMPLATE = """
你是一位顶级的AI执行专家。你的任务是严格按照给定的计划,一步步地解决问题。
你将收到原始问题、完整的计划、以及到目前为止已经完成的步骤和结果。
请你专注于解决“当前步骤”,并仅输出该步骤的最终答案,不要输出任何额外的解释或对话。
# 原始问题:
{question}
# 完整计划:
{plan}
# 历史步骤与结果:
{history}
# 当前步骤:
{current_step}
"""
- 分别构建 PLAN 大模型和 EXECUTOR大模型,我这里方便用了同一个模型。
from langchain_openai import OpenAI
class LLM:
def __init__(self):
self.llm = None
def chat(self, prompt: str) -> str:
response = self.llm.invoke(prompt)
return response
class ExecutorLLM(LLM):
def __init__(self):
super().__init__()
self.llm = OpenAI(
model="Qwen/Qwen2.5-7B-Instruct",
temperature=0.5,
base_url="https://api.siliconflow.cn/v1",
api_key="your-api-key",
streaming=False,
)
class PlanLLM(LLM):
def __init__(self):
super().__init__()
self.llm = OpenAI(
model="Qwen/Qwen2.5-7B-Instruct",
temperature=0.7,
base_url="https://api.siliconflow.cn/v1",
api_key="your-api-key",
streaming=False,
)
- 生成规划器和执行器
import ast
class Planer:
def __init__(self):
self.llm = PlanLLM()
self.PROMPT_TEMPLATE = PLANNER_PROMPT_TEMPLATE
def plan(self, question: str) -> list[str]:
prompt = self.PROMPT_TEMPLATE.format(question=question)
print("--- 正在生成计划 ---")
response = self.llm.chat(prompt)
return self.parsePlan(response)
def planWithHistory(
self, question: str, plan: list[str], history: str, failed_step_index: int
) -> list[str]:
"""
这个函数根据历史执行记录和失败步骤,对后续步骤进行动态重规划。
只修改或替换从失败步骤开始到末尾的后续步骤,保持已经完成步骤不变。
"""
prompt = f"""
原问题:{question}
原始计划:{plan}
历史执行记录(包括已完成步骤和对应结果):{history}
说明:在执行过程中第 {plan[failed_step_index]} 这一步遇到了问题,请根据历史和失败原因对后续步骤进行动态重规划。
要求:
- 保持已经完成步骤不变,只修改或替换从失败步骤开始到末尾的后续步骤。
- 输出格式严格为一个 Python 列表(```python ... ```),列表元素为新的后续步骤字符串(包含失败步骤的位置作为第一项)。
- 每个步骤要可执行、具体且按顺序排列。
请严格只输出计划列表,使用与原 plan() 相同的包裹格式(```python ... ```)。
"""
response = self.llm.chat(prompt)
return self.parsePlan(response)
def parsePlan(self, response: str) -> list[str]:
try:
planList = response.split("```python")[1].split("```")[0].strip()
planList = ast.literal_eval(planList)
return planList if isinstance(planList, list) else []
except Exception as e:
print("计划解析失败:", e)
return []
class Executor:
def __init__(self):
self.llm = ExecutorLLM()
self.PROMPT_TEMPLATE = EXECUTOR_PROMPT_TEMPLATE
def execute(self, question: str, plan: list[str]) -> str:
history = ""
response_text = ""
print(f"生成的计划如下:{plan}")
for current, step in enumerate(plan):
print(f"\n-> 正在执行步骤 {current+1}/{len(plan)}: {step}")
current_step = step
prompt = self.PROMPT_TEMPLATE.format(
question=question,
plan=plan,
history=history,
current_step=current_step,
)
response_text = self.llm.chat(prompt)
if self.failedStep(response_text):
print(f"步骤 {current+1} 执行失败,正在进行动态重规划...")
replan = Planer()
while True:
count = 0
new_plan = replan.planWithHistory(question, plan, history, current)
count += 1
if new_plan:
print(f"新的计划生成成功: {new_plan}")
plan = plan[:current] + new_plan
print(f"更新后的完整计划: {plan}")
break
elif count > 3:
print("动态重规划失败,无法继续执行。")
break
else:
continue
history += f"\n步骤{current+1}: {current_step}\n结果: {response_text}\n"
print(f"步骤 {current+1} 已完成,结果: {response_text}")
print("--- 计划执行完毕 ---")
return
def failedStep(self, response: str) -> bool:
if not response or "无法" in response or "不清楚" in response:
return True
- 现在已经分别构建了负责“规划”的 Planner 和负责“执行”的 Executor。最后一步是将这两个组件整合到一个统一的Agent PlanAndSolveAgent 中,并赋予它解决问题的完整能力。
class PlanAndSolveAgent:
def __init__(self):
self.planner = Planer()
self.executor = Executor()
def run(self, question: str) -> str:
print(f"\n--- 开始处理问题 ---\n问题: {question}")
plan = self.planner.plan(question)
final_answer = self.executor.execute(question, plan)
return final_answer
总结
Plan-And-Solve特点:
- 提高了结果的准确性:很好的避免了计算错误、遗漏步骤错误和语义理解错误的问题。
- 良好的通用性:Plan-And-Solve方法不仅适用于数学推理问题,还可以扩展到常识推理和符号推理等问题。
- 自我一致性评估:通过自我一致性方法减少了大模型输出的随机性,进一步提高了推理质量。
不足:
- 仍然是对提示词的过分依赖:引导LLMs生成正确推理步骤的提示需要精心设计,GPT-3模型对提示的表达非常敏感。
- 语义理解错误仍然存在:尽管Plan-And-Solve提示方法可以减少计算错误和遗漏步骤错误,但并没有完全解决语义理解错误的问题。
Reflection
之前的ReAct和Plan-and-Solve范式,Agent一旦完成了任务,那么整个工作流程便结束了。然而,它们生成的初始答案,无论是行动轨迹还是最终结果,都可能存在谬误或有待改进之处。
Reflection由Shinn在2023年提出[3],其核心思想,是为Agent引入了一种事后自我校正循环,使其能够像人类一样,审视自己的工作,发现不足,并进行迭代优化。核心工作流程可以概括为一个简洁的三步循环:执行 -> 反思 -> 优化。
-
执行:首先,使用我们熟悉的方法(如 ReAct 或 Plan-and-Solve)尝试完成任务,生成一个初步的解决方案或行动轨迹。这可以看作是“初稿”。
-
反思:接着,进入反思阶段。调用一个独立的、或者带有特殊提示词的大语言模型实例,来扮演一个“评审员”的角色。这个“评审员”会审视第一步生成的“初稿”,并从多个维度进行评估,生成“反馈”。
-
优化:最后,将“初稿”和“反馈”作为新的上下文,再次调用大语言模型,要求它根据反馈内容对初稿进行修正,如此循环,直至生成一个完善的“修订稿”。
与前两种范式相比,Reflection 的优势在于:
-
它为智能体提供了一个内部纠错回路,使其不再完全依赖于外部工具的反馈(ReAct 的 Observation),从而能够修正更高层次的逻辑和策略错误。
-
它将一次性的任务执行,转变为一个持续优化的过程,显著提升了复杂任务的最终成功率和答案质量。
-
它为智能体构建了一个临时的“短期记忆”。整个“执行-反思-优化”的轨迹形成了一个宝贵的经验记录,智能体不仅知道最终答案,还记得自己是如何从有缺陷的初稿迭代到最终版本的。
实现
Reflection 的核心在于迭代,而迭代的前提是能够记住之前的尝试和获得的反馈。因此,一个“短期记忆”模块是实现该范式的必需品。这个记忆模块将负责存储每一次“执行-反思”循环的完整轨迹。
- 实现简单的记忆类
from typing import Optional
class Memory:
def __init__(self):
self.storage: list[dict[str, any]] = []
def add_record(self, record_type: str, content: str) -> None:
self.storage.append({"type": record_type, "content": content})
print(f"记忆已更新,新增一条{record_type}记录。")
def get_trajectory(self) -> str:
trajectory = []
for record in self.storage:
if record["type"] == "execution":
trajectory.append(f"上一轮尝试:{record['content']}\n")
elif record["type"] == "reflection":
trajectory.append(f"反思与改进建议:{record['content']}\n")
return "\n".join(trajectory)
def get_last_execution(self) -> Optional[str]:
for record in reversed(self.storage):
if record["type"] == "execution":
return record["content"]
return None
- 构建提示词模板,以python编程任务为例,需要构建三个提示词,分别是执行、反思、改正。
INITIAL_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。请根据以下要求,编写一个Python函数。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
要求: {task}
请直接输出代码,不要包含任何额外的解释。
"""
REFLECT_PROMPT_TEMPLATE = """
你是一位极其严格的代码评审专家和资深算法工程师,对代码的性能有极致的要求。
你的任务是审查以下Python代码,并专注于找出其在<strong>算法效率</strong>上的主要瓶颈。
#原始任务:
{task}
#待审查的代码:
```python
{code}
请分析该代码的时间复杂度,并思考是否存在一种<strong>算法上更优</strong>的解决方案来显著提升性能。
如果存在,请清晰地指出当前算法的不足,并提出具体的、可行的改进算法建议(例如,使用筛法替代试除法)。
如果代码在算法层面已经达到最优,才能回答“无需改进”。
请直接输出你的反馈,不要包含任何额外的解释。
"""
REFINE_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。你正在根据一位代码评审专家的反馈来优化你的代码。
# 原始任务:
{task}
# 你上一轮尝试的代码:
```
{last_code_attempt}
```
评审员的反馈:
{feedback}
请根据评审员的反馈,生成一个优化后的新版本代码。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
请直接输出优化后的代码,不要包含任何额外的解释。
"""
- 构建
ReflectionAgent类,实现执行、反思的循环过程,直到生成完美回复。
from PlanAndSolve import ExecutorLLM
#使用PlanAndSolve中实现的ExecutorLLM类
class RelectionAgent:
def __init__(self):
self.memory = Memory()
self.llm = ExecutorLLM()
def run(self, task: str) -> Optional[str]:
print(f"开始处理任务:{task}")
initial_prompt = INITIAL_PROMPT_TEMPLATE.format(task=task)
code = self.llm.chat(initial_prompt)
self.memory.add_record("execution", code)
for iteration in range(3): # 最多反思和改进三次
print(f"\n--- 反思与改进轮次 {iteration + 1} ---")
last_code = self.memory.get_last_execution()
reflect_prompt = REFLECT_PROMPT_TEMPLATE.format(
task=task,
code=last_code,
)
feedback = self.llm.chat(reflect_prompt)
print("反思反馈:", feedback)
self.memory.add_record("reflection", feedback)
if "无需改进" in feedback:
print("代码已达到最优,无需进一步改进。")
break
else:
refine_prompt = REFINE_PROMPT_TEMPLATE.format(
task=task,
last_code_attempt=last_code,
feedback=feedback,
)
refined_code = self.llm.chat(refine_prompt)
self.memory.add_record("execution", refined_code)
print("改进后的代码:", refined_code)
final_code = self.memory.get_last_execution()
print("\n--- 最终代码 ---")
print(final_code)
return final_code
总结
Reflection特点:
- 提高了解决方案质量:最大的收益在于,它能将一个“合格”的初始方案,迭代优化成一个“优秀”的最终方案。这种从功能正确到性能高效、从逻辑粗糙到逻辑严谨的提升,在很多关键任务中是至关重要的。
- 鲁棒性与可靠性:通过内部的自我纠错循环,智能体能够发现并修复初始方案中可能存在的逻辑漏洞、事实性错误或边界情况处理不当等问题,从而大大提高了最终结果的可靠性。
不足:
- 模型调用开销增加: 每进行一轮迭代,至少需要额外调用两次大语言模型(一次用于反思,一次用于优化)。如果迭代多轮,API 调用成本和计算资源消耗将成倍增加。
- 任务延迟显著提高:Reflection 是一个串行过程,每一轮的优化都必须等待上一轮的反思完成。这使得任务的总耗时显著延长,不适合对实时性要求高的场景。
- 提示词复杂度上升:Reflection 的成功在很大程度上依赖于高质量、有针对性的提示词。
应用场景总结
| 任务 | 选择 | 原因 |
|---|---|---|
| 不确定性,需要工具调用 | ReAct | 能根据调用结果动态调整路径 |
| 逻辑路径清晰,侧重内部推理和步骤分解 | Plan-and-Solve | 提供稳定、结构化的执行流程 |
| 对最终的结果的质量和可靠性有极高要求 | Reflection | 通过迭代,能回复极高可靠性的答案 |
参考文献
[1] Yao S , Zhao J , Yu D ,et al.ReAct: Synergizing Reasoning and Acting in Language Models[J].ArXiv, 2022, abs/2210.03629.DOI:10.48550/arXiv.2210.03629.
[2] Wang L , Xu W , Lan Y ,et al.Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models[J].Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023.DOI:10.18653/v1/2023.acl-long.147.
[3] Shinn N , Cassano F , Berman E ,et al.Reflexion: Language Agents with Verbal Reinforcement Learning[J]. 2023.
[4] GitHub - datawhalechina/hello-agents: 📚 《从零开始构建智能体》——从零开始的智能体原理与实践教程