An Empirical Survey on Long Document Summarization,Part 2:Model

本文是论文《An Empirical Survey on Long Document Summarization》的阅读笔记第二部分,介绍了抽取式、生成式和混合式三种长文本摘要方法及其对应有哪些代表模型。
模型
在长文本摘要领域,主要包括三个方法:Extractive, Abstractive, 和 Hybrid,分别代表抽取式文本摘要、生成式文本摘要和混合式文本摘要。
- 抽取式文本摘要直接从源文本复制突出句子并将它们组合为输出
- 生成式本文摘要是根据源文本而生成一种新的文本作为摘要的方法。
- 混合式文本摘要则是从长文本进行抽取出重要句子再进行生成式文本摘要的方法
由于抽取式文本摘要仅提取和排列其认为是显著的原始文本并且不改变原始文本,因此其享有生成与源文本事实上一致的摘要的益处。然而,由于基于人类的总结通常涉及将想法和概念改写为更短,简洁的句子,因此这种方法提取的句子通常包含冗余和无信息的短语。虽然存在将源文本分解成比句子更低的词汇单元的提取摘要模型(例如,基本话语单元),由于输入文本的长度太长,它们通常不应用于长文本摘要领域。
生成式本文摘要,由于是模仿人类如何编写摘要,该方法呈现了生成流畅,简洁且与源文本相关的摘要的潜力。它还可以根据用户的需求将外部知识并入摘要。然而,在目前的开发阶段,由最先进的抽象模型生成的摘要通常包含大量事实不一致的问题,限制了其在商业环境中的应用。
最后,为了响应当前模型架构和设计的限制,混合式文本摘要与抽象摘要方法的不同之处仅在于它采用原始输入文本的精心选择的子集,而不是原始形式的整个输入文本。这个额外的步骤减少了抽象摘要模型的负担,抽象摘要模型必须同时生成抽象摘要和选择重要内容。这种方法更常用于长文本摘要领域,因为当前的模型仍然无法在非常长的文本上进行推理和或遭受内存复杂性问题和硬件限制,这阻止了它处理长输入文本;下图为抽取式、生成式和混合式文本摘要模型结构类型。
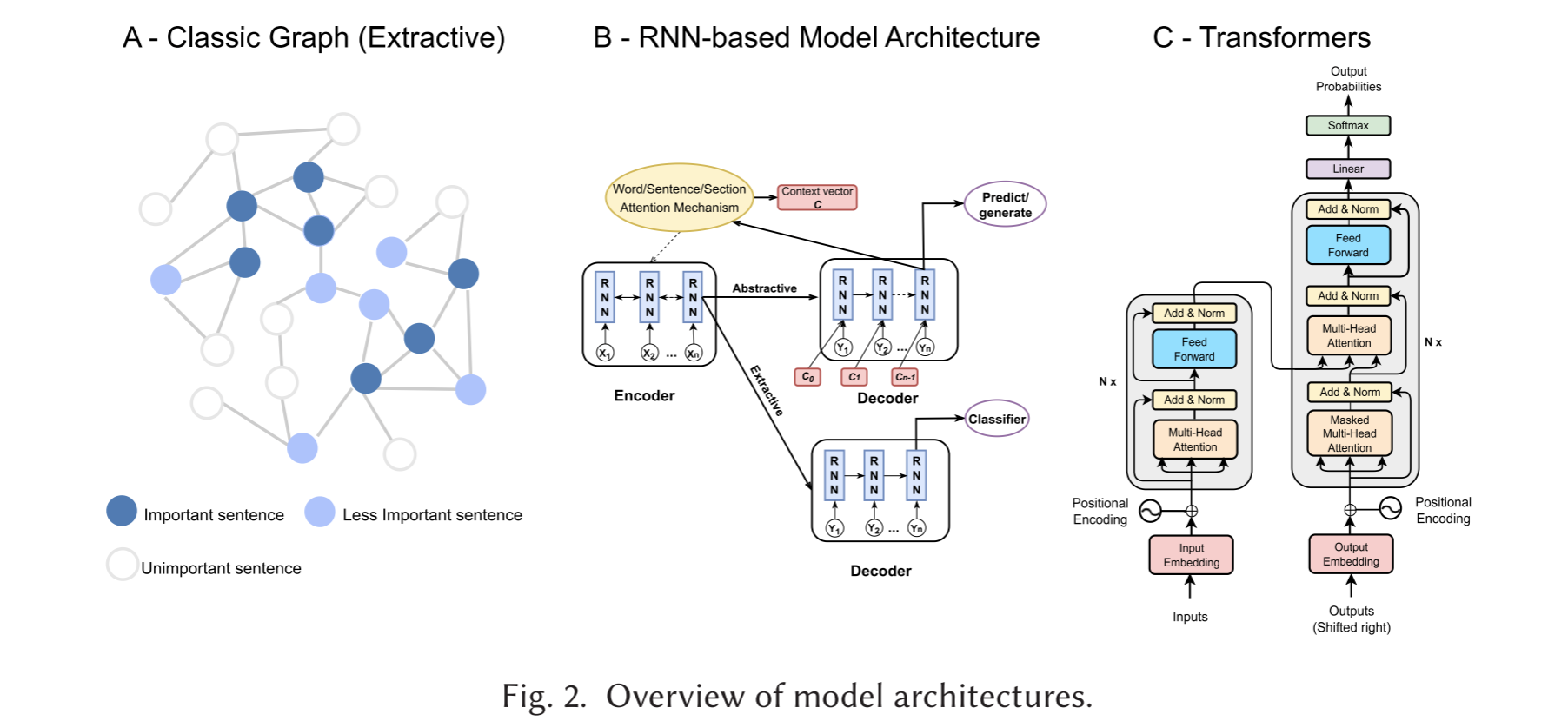
模型的主要结构
目前来说,摘要模型主要分为四个结构:图结构、传统机器学习结构、神经网络结构、Transformer 结构
图结构
对于抽取式摘要,经典的就是用图结构了,这其中涉及两个阶段的过程映射一个文本到一个“图”,其中顶点是句子,边缘是其他句子这些句子之间的相似性,根据图中心每个句子得分进行排序,然后提取前K个相似的句子。图结构的研究主要表现在两个方面上。
- 在计算句子之间的相似性之前对句子向量化阶段:使用 TF-IDF 来进行编码,当然今天可以采用 BERT 模型来进行编码。
- 改进中心句子得分的算法:PacSum 和 FAR 根据其他句子是否在它之前或之后来调整句子的中心性得分,而 HipoRank 通过调整位置和部分偏差的中心性得分来利用包含的话语结构等等,具体算法可查阅论文4.2节
传统机器学习结构
这方面的研究主要集中在抽取式摘要上。主要有:贝叶斯、支持向量机、决策树;在长文本方面有:SVD、SumBasic 等算法来抽取重要句子。
神经网络结构
Cheng 和 Lapata 提出了一个采用具有连续表示的神经网络模型来进行抽取式文本摘要,该模型实现了一个基于RNN 的 Encoder-Decoder 架构结合了注意力机制,以定位在句子提取过程中的重要区域。然而,该模型缺乏足量的长文本数据集以及RNN无法捕获长文本中的长时间的依赖关系,直到 Xiao 和 Carenini 提出了 LSTM-minus(RNN的变体)解决了这一问题。它作为长文本摘要的 Typical,它结合了源文本的语句信息(例如:section structure),通过将 section-level 和 document-level 分别 encode 到每个句子中,显着的提高了模型性能。Pilault 等人还提出了两种不同的 RNN 变体,用于长文本抽取式摘要。他们没有使用预先训练的单词编码,而是实现了一个分层的 LSTM 来分别编码单词和句子。
当涉及到生成式文本摘要方法时,Celikyilmaz等人提出了多个 communicating agents 来完成长文本摘要。然而,与其他更简单的体系结构相比,这种方法在引入第一个长科学领域的大规模长文本数据集之后效果并没有获得显著的提升。Cohan等人贡献了两个最常用的长科学文本数据集 arXiv 和 PubMed ,提出了一种 LSTM 的 Encoder-Decoder 架构,其中 Encoder 关注原文本的每个部分,以在关注每个单词之前确定部分级别的注意力权重。虽然类似的结构已经在先前的研究中被广泛使用,但是也有效地结合了长文本摘要任务的话语信息,发挥了不错的效果。
Transformer架构
2017年提出的 Transformer 模型,以及基于 Transformer 模型本身的 BERT 模型,已经在 NLP 领域掀起了风暴(GPT 同样是Transformer 架构);到如今,基本 Transformer 结构“一统天下”了,不仅仅是摘要领域。其中,BERTSum 通过修改 BERT 的segmentation embeddings ,不仅可以捕获句子对输入,还可以捕获多句子输入。BERTSum 模型可以有效地解决抽取式和生成式摘要任务。
BertSum
论文地址:下见参考文献2
1.用于抽取式文本摘要
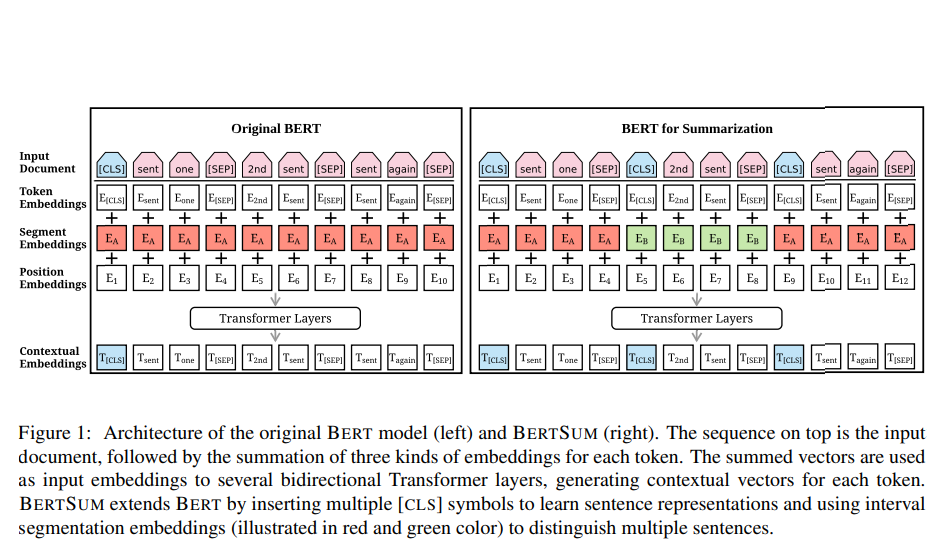
在编码阶段:
Token Embedding 中将多个句子通过 [CLS] 符号相隔开来
Segment Embedding 中奇数句子表示为1,偶数句子表示为0
在输出阶段:
将 BERT 的输出中的 [CLS] 作为整个句子的句向量表示,然后进入 transformer 用多头注意力机制(Multi-Head Attention)和层归一化(Layer Normalization),提取文本级特征。
h 是句向量的表示,LN是 layer normalization,MHAtt 是 multi head attention,FFN 就是前馈神经网络,其中是第一个句子的 [CLS] 向量加上位置编码。
再将输出的 ,进入到一个二分类 sigmoid 分类器:

训练抽取式模型
使用贪婪算法来计算生成的摘要与样本摘要有最大的 ROUGE-2 分数的句子。
预测过程
测试的过程中,使用模型来对每一个句子进行打分。同时对这些句子按分数进行排序,选择最高的3个句子作为 summary 。
2.用于生成式摘要
论文采用 encoder-decoder 的框架来生成摘要。编码器采用的是预训练好的BERTSUM,而解码器则是一个6层的随机初始化的 Transformer。
论文设计了一种将编码器和解码器的优化分开微调的机制。

由于 Transformer 作为最先进的模型已经有效地取代了两种摘要方法中的大多数主要架构,因此在长文本摘要上下文中应用的各种机制将在下一节中彻底讨论。
基于Transformer结构
基于 Transformer 的模型在 NLP 领域的各种任务中普遍存在。最近的长文本摘要模型的也涉及到了 Transformer 基础架构,但有不同的构建机制。再其添加了新的机制,可以确保可以有效地完成较长输入文本的摘要任务。下图描述了基于 Transformer 的生成式和混合式模型结构。
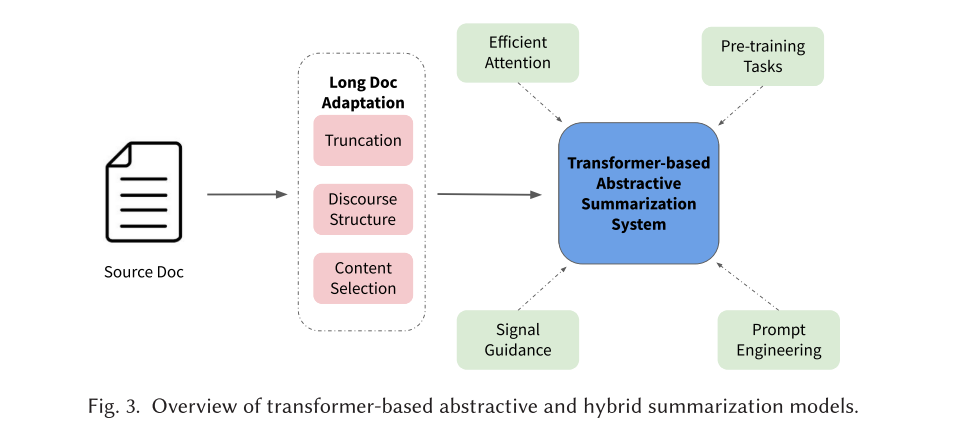
抽取式Transformer
由于 Transformer 及其预训练模型针对短文本设置进行了优化,如果没有适当的微调,它们可能无法很好地推理长文本。为此,Cui 等人提出将神经网络模型与 BERT 结合起来,在整个文本中学习主题增强的句子间关系。尽管如此,内存的复杂性和输入令牌长度限制的问题仍没有得到解决,重要的句子片段被往往被截断。最近,Cui 和 Hu 提出了一种记忆网络,它结合了图注意力网络和门控递归单元,通过沿着整个源文本滑动窗口来动态选择重要句子。这种方法可以有效地集成预训练的BERT模型,用于长文本摘要任务,通过限制其在每个窗口内的使用,其中窗口大小被设置为小于或等于512个 Tokens 。
生成式Transformer
-
Sequence-Sequence 模型:代表有 BART、T5,其中 BART 是在重建任意损坏文本的自监督任务上进行预训练的,而 T5 是在无监督和有监督的目标上进行预训练的。但长文本摘要领域中并没有有监督的 Transformer 模型能像 T5 一样在短文本摘要领域那么成功。
-
Gap-Sentence Generation (GSG) 预训练任务:除了像 BART 和 T5 这样的预训练任务之外,PEGASUS 通过具有特定于摘要任务目标的大规模预训练来推进着抽象摘要领域的进展。我们知道,预训练目标与下游任务越接近,下游任务就会表现越好。那么,为了更好的完成文本摘要,可以mask掉文本中重要的一些句子,然后拼接这些 gap-sentences 形成伪摘要。相应位置的Gap-sentences用 [MASK1] 来替换。Pegasus在两个大规模数据集( C4 和 HugeNews )上进行了训练,并进行了 gap-sentences 预测任务的训练。在 PEGASUS 模型发布时,在12个不同的摘要数据集上取得了 SOTA 的结果,包括 arXiv 和 PubMed 数据集。
-
高效的注意力机制:使用完全注意力的初始 Transformer 模型的内存复杂度为 。此限制了它在许多领域的广泛使用,包括长文本摘要。例如,为了规避 PEGASUS 的输入长度限制,DANCER 分别总结了长文本的每个部分,并将它们连接起来形成最终摘要。由于并非所有数据集都包含节结构之类的信息,这限制了该模型在许多长文本摘要设置中的使用。为此,研究人员提出了各种巧妙的想法来降低 Transformer 模型的内存和时间复杂度。消耗较少内存的 Transformer 模型的变体通常被称为高效 Transformer ,其机制被称为高效注意力。
Longformer 便由此产生了,其在微调的 BART 模型上结合了局部注意力,步幅模式和全局记忆力,可以一次性处理16384个词,而不是原始 BART 模型的1024个词的限制。该模型在长文本摘要和其他NLP任务方面取得了 SOTA 。BigBird 利用与 Longformer 相同的注意力修改以及额外的随机模式,在基于 Transformer 的抽取式摘要模型上实现了高效的注意力机制,以在 ROUGE 得分方面实现极高的性能结果。Huang 等人的一项重要工作,就是在长文本摘要的上下文中探索并比较了不同高效的注意力机制 Transformer 变体模型的性能。
-
Prompt-Engineering :GPT-3,以及最近的 ChatGPT、GPT4 有力地证明了大规模的预训练模型可以在 zero- shot 和 few-shots 的实验设置中对许多下游任务取得不错的结果。不是以传统方式微调特定任务的语言模型,而是为 GPT-3 创建 prompts 和 task demonstrations ,以推断和完成任务。重要的是,这不同于传统的标记方法,例如 <bos> 用于条件生成或从 BERT 中获取 [CLS] 标记用于分类任务。Prompt-Engineering 是指采取额外的步骤来设计 NLP prompt 或者 template,可以优化特定任务的预训练模型。在长文本摘要领域,CRTLSum 通过 prompt-engineering 在 arXiv 数据集上使得最初微调的 BART模型的性能获得了显著提高。该模型在关键字提示的帮助下更有效地使用预先训练的 BART 模型。此外,工作还表明,给定优化的 Prompt 而实现的 BART 摘要模型可以实现与测试数据集中的 Oracle (参考摘要)的 ROUGE 相匹配的分数。
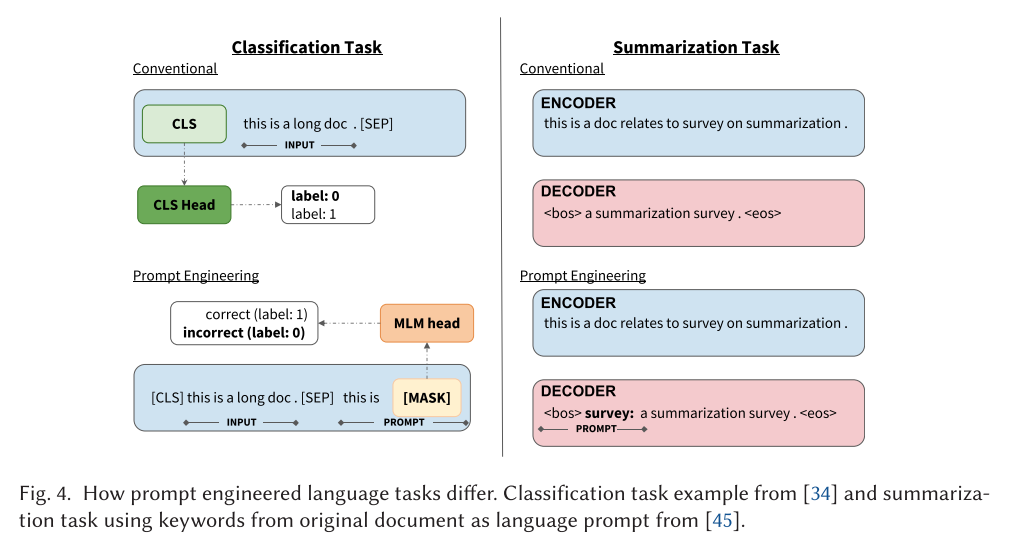
-
Signal Guidance:与需要针对特定任务的 Prompt-Engineering 不同,Signal Guidance 涉及利用信号作为输入来引导模型更好地识别和概括源文本的重要内容。使用这种方法,GSum 模型实现了一个具有双编码器的微调BART模型,一个用于输入文本,另一个用于提取信号,以及一个负责两种编码表示的解码器。类似的 Signal Guidance 的方法也被 Ju 等人使用,来实现基于无监督 pipeline-based 的长文本摘要模型。
-
Discourse Bias : 和 Signal Guidance 类似,Discourse Bias 将具有对话结构的源文本作为摘要模型的信号以更好地识别和对原始源文本中的重要内容进行摘要,这种机制可以在 Signal Guidance 下分类,由于其在基于 Transformer 和非 Transformer 的长文本摘要模型中的有效性和流行性而被单独提及。与短文本不同,长文本通常包含诸如目录、章节结构、参考文献等的结构信息,以引导读者理解原始文本,并且先前的工作已经利用这些信息来实现 SOTA 的结果。尽管如此,以前在长文本摘要领域的工作仅利用了数据集提供的文本信息,并且由于难以为过长长度的文本构建有效的表示方法,因此没有使用 RST 树和 coreference mentions 来实现自动文本分析。
混合式Transformer结构
混合式摘要方法与生成方法的不同之处仅在于它采用输入文本的部分重要句子而不是整个输入文本作为输入。这个步骤减轻了摘要模型的负担,因为摘要模型必须同时生成抽象摘要和选择文本重要内容。一些人还将采用混合方法的模型称为“检索-汇总模型”,因为它涉及在汇总之前检索长文本文本的子集。TLM+Ext 使用抽取式摘要方法仔细选择 arXiv 数据集中科学文章的句子的子集,最后,如果有剩余的额外空间用于基于 Transformer-based decoder ,则使用文本剩下未被选择的文本。然而,这项工作的一个局限性是它只利用 decoder 框架来生成最终摘要,而不是大多数混合摘要方法的后续工作所做的 encoder-decoder 框架。
LoBART 提出了一种混合摘要系统,其在两个单独的步骤中完成摘要生成,1.内容选择:使用 RNN ,从原始源文本中选择重要内容,直到重要内容长度达到序列到序列预训练 BART 模型一次性能处理的最大token,2.生成摘要:使用 BART 模型来总结所选择的重要内容。EAL 提出了一种用于基于Transformer 的长文本摘要的通用 encoder-decoder 框架,该模型选择重要内容并动态地选择所选内容的片段以供 decoder 以端到端的方式进行摘要。然而,该模型并没有利用大规模预训练模型。
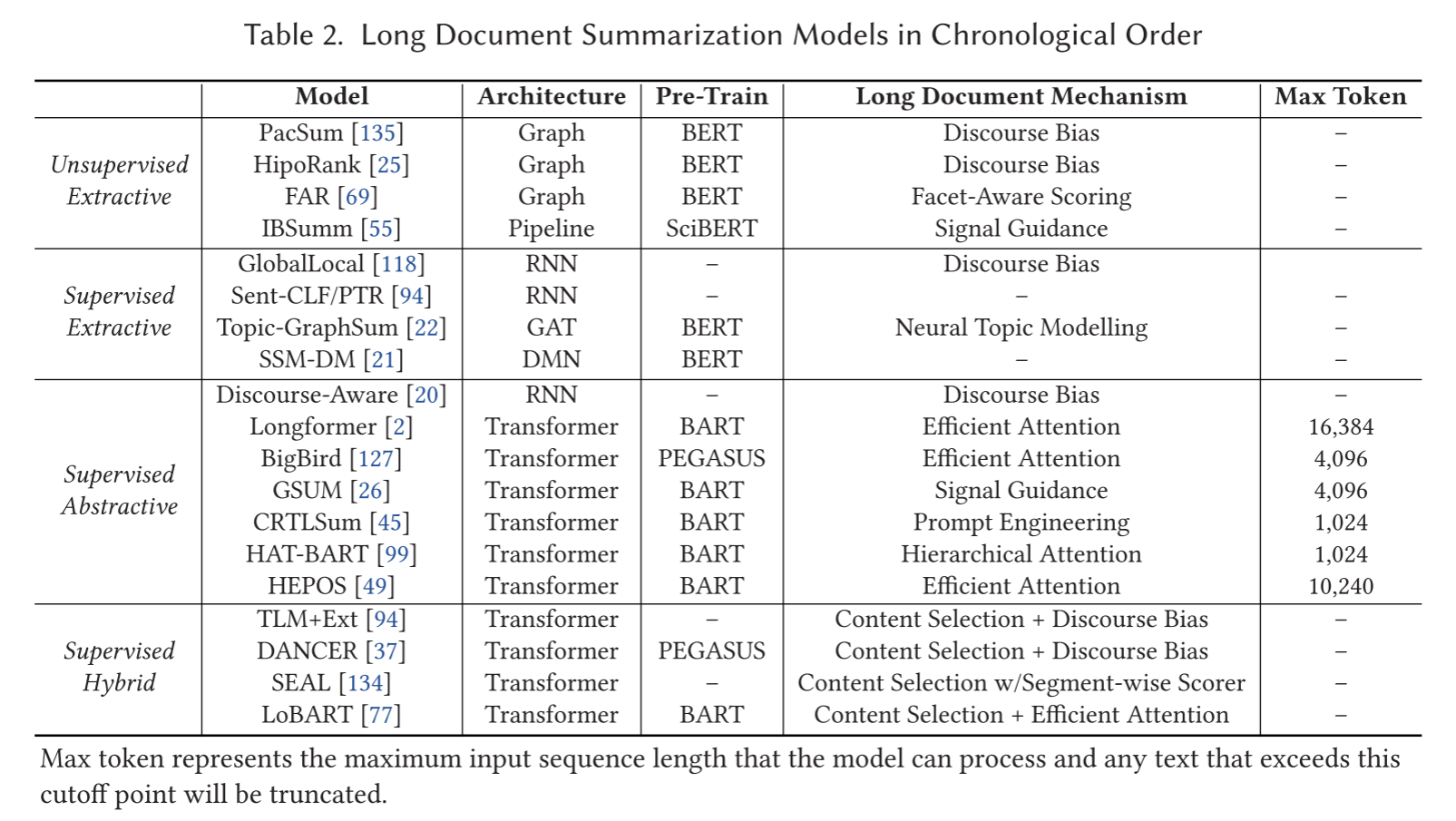
按时间顺序回顾长文本摘要模型
参考文献
《An Empirical Survey on Long Document Summarization: Datasets, Models and Metrics》