An Empirical Survey on Long Document Summarization,Part 1:Introduction and Datasets

论文《An Empirical Survey on Long Document Summarization》对长文本摘要领域通过模型、数据集和评价指标三个方面进行了全面的概述,文本是该论文阅读笔记第一部分,描述了长文本的概念,介绍了目前的数据集。
介绍
文本摘要就是一个缩短源文本,同时保持主要思想不变的过程,在当今数据大爆炸的时代,这有助于减少处理信息所需的时间,有助于更快地搜索信息。文本摘要目前已经引起了研究界的极大兴趣和关注,但文本摘要仍然是一项具有挑战性的任务,特别是在长文本摘要方面。直观上,长文本摘要比短文本摘要更难,这是由于短文本和长文本之间的词汇量之间的差异。随着长度的增加,文本中重要的内容也会增加,这导致自动摘要模型在有限的输出长度中捕获所有突出信息的任务更具挑战性(通常大模型输入大小限制为1024个token)。此外,短文本通常是通用文本,例如新闻文章,而长文本通常是特定领域的文章,包含了复杂公式和术语的论文。
什么是长文本
为了更好的区分短文本和长文本,论文从三个不同的基本方面对摘要任务问题进行了概念化:
文本的长度
文本被认定为“长”,那肯定是因为源文本中的词语的数量是巨大的,并且对于普通人来说阅读全文需要相当多的时间。虽然这个定义是“直观”的意义,但在传统机器学习时期中,由于硬件和模型限制,当文本内容超过了模型一次能处理的数量时,文本被认为是长文本的。例如,以前将新闻领域的CNN/DM和NYT数据集视为长文本,而在目前的研究背景下,它们现在则被认为是短文本数据集。
目前来说,平均源文本长度超过3000个词汇的数据集则被认为是“长文本”,这是由于目前的摘要模型仅能一次处理512~1024个词汇的文本。
文本的信息
通常来说,非冗余的信息内容将随着文本长度的增加而增加。但对于长文本的摘要不一定如此,随着源文本长度的增加,摘要相对于源文本的相对长度呈指数级地变短。由于这种约束,长文本的摘要将不可避免地丢失对原文本的中心思想,由于用户偏好差异性,用户无法就短文本新闻领域中给定摘要的内容达成一致。当涉及到长文本摘要时,这个问题会加剧,因为摘要相对于源文本的相对长度较短,以及文本随着内容广度的增加,用户偏好差异性将会增加,使得长文本摘要任务明显比短文本更难。
文本相关度
与短文本相比,长文本通常被构造成便于用户理解的部分。尽管都是围绕着长文本的关键点叙述,但每一节的内容都有一定程度的不同。这使得长文本摘要任务更加繁重,因为摘要模型不能在不考虑其对最终摘要输出的流畅性、冗余性和语义一致性的影响的情况下连接不同部分的文本。
数据集
数据集用于评估一个长文本模型的性能,但是不同的数据集具有不同的内在特征,这些特征往往会使得不同的模型在不同数据集性能有不同的差异性。因此,只有对数据集进行一个全面的理解,才能更好的评估模型真正的性能和适用性。
Short-document datasets: 主要有CNN-DM, NWS, XSUM,Reddit-TIFU和 WikiHow这几种公开数据集,前三个数据集是因为它们的流行程度,而Reddit-TIFU和WikiHow则是来确保来自其他领域的短文本也被包括在内。
CNN-DM、NWS和XSUM数据集是新闻领域的摘要,其中源文本表示新闻文章,而摘要表示人工生成的摘要。
Reddit-TIFU是从reddit子版块r/TIFU 中收集的数据集,而WikiHow是使用WikiHow网页段落的第一句作为摘要,其余部分作为文本而创建的。
Long document datasets: 主要有arXiv、PubMed、BIGPATENT、BillSum和GovReport这几种公开数据集,arXiv、PubMed是从arXiv.org和PubMed.com中收集到的科研论文,这两个数据集也是早期长文本摘要的主要数据集。BIGPATENT拥有超过130万份美国的文本摘要记录、专利文献的摘要数据集。BillSum 是一个总结国会和加州州法案的数据集,其中写作的内容结构和风格特征与其他领域的文本有很大不同。GovReport是收集美国政府的报告而成,明显长于其他长文本数据集。
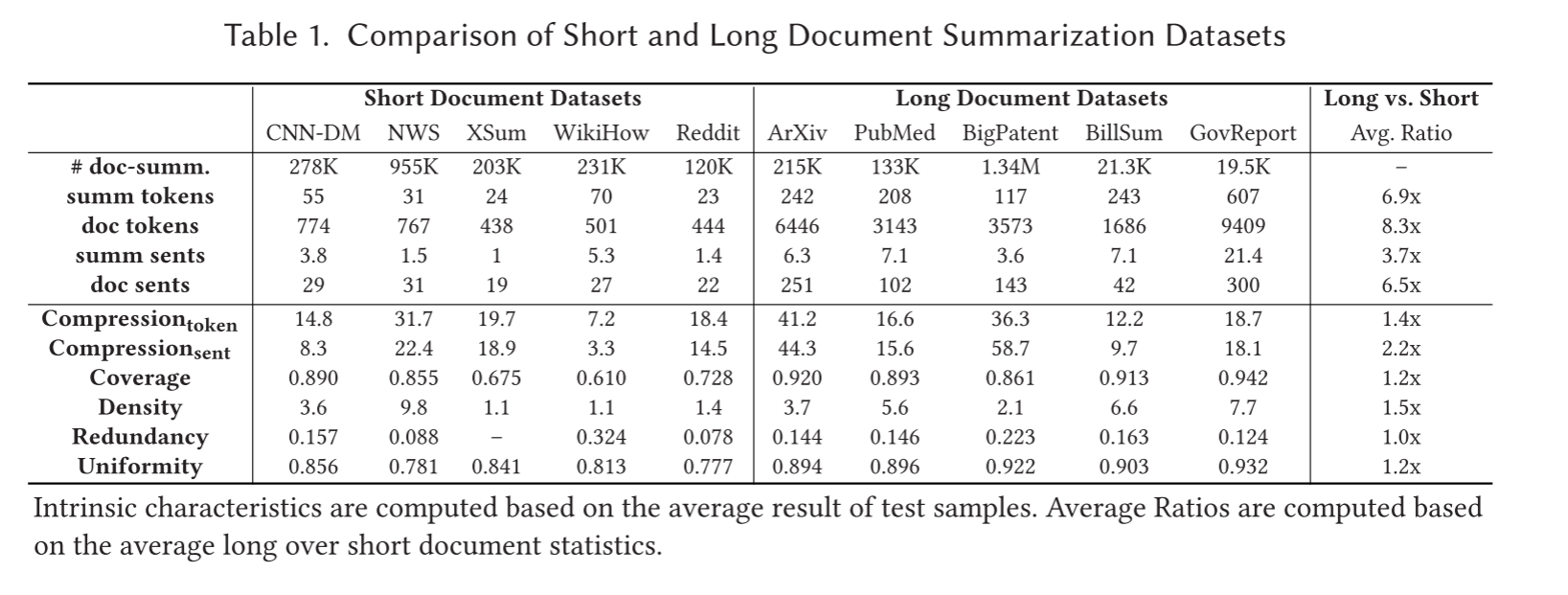
以上是对上述数据集的统计具体统计标准可在原论文3.2小节中查看,同时上述数据集均可在Hugging Face – The AI community building the future.中下载
数据集的内在特征
发现1.长文本数据集的长度: 除了BillSum之外,所有其他长文本数据集的平均源文本长度至少为3000。而一个基于Transformer的预训练模型,通常具有1024长度的输入限制,也就是说需要在长文本数据集中截断至少一半的源文本。因此,如果在短文本数据集效果良好的预训练模型,它们不太可能为长文本生成高质量的摘要。
发现2.高压缩比的意义: 长文本摘要数据集的词语级和句子级压缩比分别比短文本数据集大1.4倍和2.2倍。这表明长文本摘要数据集在摘要中存在更大的信息损失,这增加了长文本摘要任务的相对难度,因为模型将必须清楚地识别来自源的关键信息,同时排除文本中不太重要的内容。此外,如果在长文本的摘要中存在更大的信息损失,则所生成的摘要将不可避免地错过重要的信息,从而降低了摘要方法满足生成的摘要的有效性。
发现3.数据集的抽象性和多样性: 除了BIGPATENT,所有长文本数据集比短的文本数据集有更大的覆盖范围和密度值,这表明一个长文本摘要模型,只是提取词汇从原始源文本的文本片段仍然可以生成一个摘要,参考总结更相似。
发现4.长文本有更小的Layout偏差: 与短文本摘要领域的实践不同,短文本领域的模型通常通过利用布局偏差而受益,而长文本摘要模型实现截断策略以仅处理长文本的主要内容的一小部分,可能会遭受显著的性能下降。
发现5.固有特性之间的关系: 论文发现作者在撰写不受约束的生成式摘要时会更加冗长,并且撰写摘要内容时不会添加信息。而假设当作者必须写简明摘要时,他们会被迫更多地解释原始内容,以确保摘要可以在受约束的摘要长度内覆盖显著内容。
总结
从长文本数据集之间的内在特征来看,arXiv和BIGPATENT具有比其他数据集更高的压缩比,但提取密度值更低,这表明其中两个数据集需要一个摘要模型来生成一个明显更短的摘要,该摘要与源文本的编写方式不同。如上所述,这可能是因为对于在受约束的摘要长度内覆盖更多内容的摘要,必须更多地解释原始内容。arXiv基准数据集的提取覆盖率和密度度量之间的差异值也证明了这一点,这表明arXiv科学论文的摘要具有与源文本高匹配的标记和术语(高覆盖率),但具有低匹配短语(低密度)。总的来说,BIGPATENT数据集是最适合长文本监督训练的抽象摘要的基准数据集,因为它的覆盖率和密度低,大量的训练样本对作为监督信号,以及重要内容的高度一致性。然而,只有少数完全监督的抽象长文本摘要工作在BIGPATENT上评估了他们的模型。
参考文献
An Empirical Survey on Long Document Summarization: Datasets, Models and Metrics