SimCSE

最近做实验需要用到Sentence Embeddings(句向量),特地研究了一下句向量相关模型算法,其中 SimCSE 模型是目前比较火、效果也比较好的一个模型。
概述
SimCSE(Simple Contrastive Learning of Sentence Embeddings) 是在 EMNLP 2021会议中提出基于对比学习(Contrastive Learning)的句向量模型。传统句向量的研究中,句向量基本是通过词向量求和而成(词向量通常是由 word2vec 等方法训练而成)。但这样的方法比较简单粗暴,而且直接加和的方式并没有利用到词与词之间的交互信息。随着 Bert 模型的提出,Bert为基础的各类模型算法初露头角,常见的有1.使用 Bert 最后一层输出层中的 [CLS] token的向量求和来表示整个句子的向量,2.取 Bert 倒数第二层输出然后求平均池化/最大池化,3.将 Bert 最后四层直接拼接,这些方法效果相较于传统的方法有所提升,但是没有 SimCSE 的效果好。
无监督SimCSE
对比学习的核心思想就是:将相似的样本拉近,将不相似的样本推远。
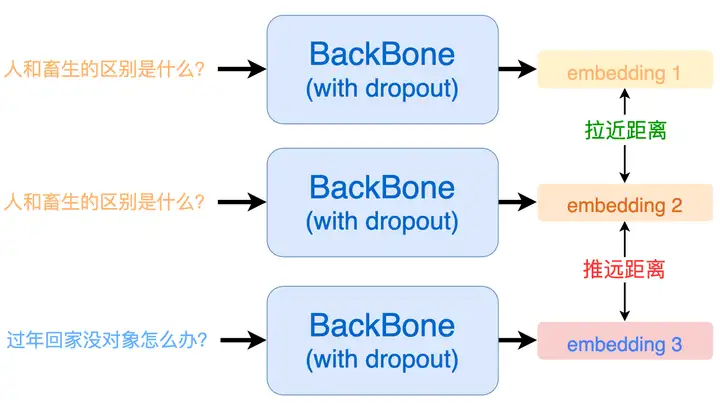
SimCSE利用自监督学习来提升句子的表示能力。由于SimCSE没有标签数据(无监督),所以把每个句子本身视为相似句子。说白了,本质上就是 ( 自己 , 自己 ) 作为正例、 ( 自己 , 别人 ) 作为负例来训练对比学习模型。但如果仅仅只是完全相同的两个样本作正例,那么泛化能力会大打折扣。一般来说,我们会使用一些数据扩增手段,让正例的两个样本有所差异,但是在NLP中如何做数据扩增本身也是一个问题,SimCSE 相出了一种很妙的办法,由于预训练模型在训练的时候通常都会使用 dropout 机制。直接把Dropout当做数据扩增
这就意味着:即使是同一个样本过两次模型也会得到两个不同的 embedding。而因为同样的样本,那一定是相似的,模型输出的这两个 embedding 距离就应当尽可能的相近;反之,那些不同的输入样本过模型后得到的 embedding 就应当尽可能的被推远。
过程如下:
- (1) 将同一个句子输入到模型两次,得到两个不同的特征向量。由于模型中存在dropout 层,某些神经元会随机停止工作导致同一个句子在训练阶段输入到模型中得到的输出都会不一样).
- (2) 在一个batch中,将同一个句子在模型中的两次输出当作正例,将其他句子的输出全部当作负例。
- (3) 优化对比损失,增加正例之间的相似度,减小负例之间的相似度。
具体来说,个句子经过带 Dropout 的 Encoder 得到向量,然后让这批句子再重新过一遍Encoder (这时候是另一个随机Dropout) 得到向量,我们可以将视为一对(略有不同的)正例了,那么训练目标为:
其中, 为超参数,论文中设定为0.05,那么这个 有什么用呢?
网上有一些解释:
1.如果直接使用余弦相似度作为logits输入到Softmax,由于余弦相似度的值域是[ − 1 , 1 ] ,范围太小导致 Softmax 无法对正负样本给出足够大的差距,最终结果就是模型训练不充分,因此需要进行修正,除以一个足够小的参数 r 将值进行放大。
2.超参数 r 会将模型更新的重点,聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与 距离越近,则分配到的惩罚越多。
有监督SimCSE
有监督版本的simcse中实验了什么样的数据更适合 sentence embedding 。作者直接采用NLI有监督数据集做对比学习训练。NLI,及自然语言推理,其任务是判断两句话之间的关系。其中可能的关系有entailment (相近), contradiction (矛盾)或neutral (中立)。因此,entailment sentence pair 就可以被天然的作为正例,此时如果我们继续把同 batch 中其他 embedding 作为负例,SimCSE 的第二个代理任务我们就构建好了。此外,作者还尝试了把 hard negative(及NLI dataset中的contradiction sentence pair)加到负例中,效果也有一定提升。
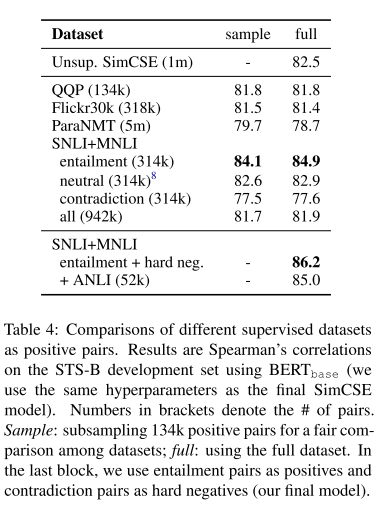
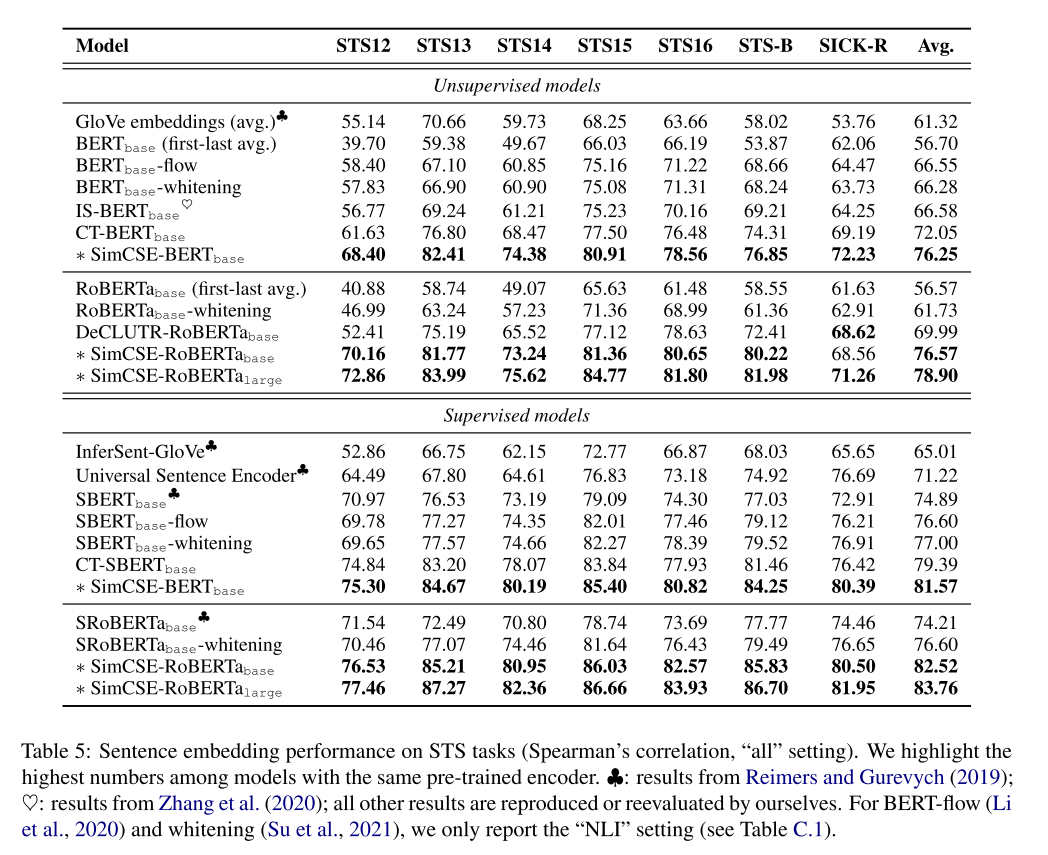
实验结果
最终结果如下。可以看到,无论是无监督的SimCSE还是有监督的SimCSE在各个数据集上基本都处于碾压的存在。
使用
HuggingFace有用中文语料训练好了的模型,可以直接拿来使用
cyclone/simcse-chinese-roberta-wwm-ext · Hugging Face
也可以在自己的中文数据集中训练
参考文献
SimCSE: Simple Contrastive Learning of Sentence Embeddings (arxiv.org)
中文任务还是SOTA吗?我们给SimCSE补充了一些实验 - 科学空间|Scientific Spaces (kexue.fm)