Generating EDU Extracts for Plan-Guided Summary Re-Ranking

这篇文章是在我之前介绍的BRIO模型(BRIO | 威伦特 (voluntexi.github.io))的基础上改进的,模型的整体框架也是采用两步式摘要,即结合生成候选摘要和评估候选摘要两个阶段来获得最佳摘要。
概述
作者提出了一种生成候选摘要的方法,以解决传统使用beam search、nucleus sampling和diverse beam search生成候选摘要所出现的冗余,质量低的问题。
该方法采用一种抽取后生成的框架,首先使用采取抽取拷贝机制(extractive copy mechanism)的BART来生成结构为EDU(基本篇章单元)的content plan。然后使用content plan生成器的top-k beam算法去引导语言模型,使得语言模型为每个不同的content plan生成候选摘要。在评估候选摘要阶段,作者采用了BRIO的评估器来获得最终摘要。
EDU是一种比句子更细粒度的子句,且比普通子句内容单元更加独立、更密集。类似于实体或者名词短语
方法
EDU
一般来说,参考摘要通常是对原文本多句话的合并。如果只选择相关的原文子句合并作为摘要,显然是一个理想的抽取计划。
作者首先参考修辞结构理论(Rhetorical Structure Theory)选择将文档句子分割成EDU。
接下来进行提取EDU,作者使用神经解析器(neural parser),微调 xlm-roberta-base 模型,在6种语言的 RST 树库上,将句子分割成不重叠的、连续的 EDU 片段,并通过贪婪策略选择在ROUGE-1,ROUGE-2平均指标最好的EDU。同时为了防止EDU碎片化,作者将长度小于5的EDU进行了合并,作为oracle plan。
Plan-Guided Abstraction (PGA)
作者将一个BART转换成分层编码器,单解码器模型,将上步提取出的EDU作为目标对模型进行训练。然后,使用另一个encoder-decoder 模型(BART用于CNN/DM数据集和NYT数据集,PEGASUS用于Xsum数据集)以生成多个候选摘要。模型结构图如下所示

Generating EDU-Level Plans
作者采用了BART语言模型,使得它能够按照它们出现的顺序从左到右生成抽取的EDU。解码器使用一种对EDU的copy mechanism和特殊的提取结束标记。特殊标记使得EDU提取具有可变的长度。
符号表示: 文档 可以表示由个非重叠EDU列表组成:。content plan 是文档中的EDU的子集:.令表示以结尾的有序部分的抽取。将EDU 到的概率建模为:
作者实验了按照EDU提取顺序添加构建摘要和以EDU的概率从大到小来构建摘要的方式对结果的影响,发现前者效果优于后者。
为了对EDU进行编码,作者将每个EDU前后添加<e> 和<\e>的方式来将EDU进行标记。然后输入BART模型之中,将EDU的每个token进行平均池化以作为EDU的隐藏层状态。
然后,通过初始化的EDU级别的BART编码器对EDU表示进行建模:
其中,表示<eoe>结束标记的嵌入表示。中添加了位置嵌入,为了在通过Transformer层之前表示其在文档中的位置。在解码器时间步长处,具有隐藏状态和部分提取,由单层MLP评分为有效的下一个输出()进行评分,这个步骤可以被描述为:
Learning to Abstract from EDU Plans
作者微调了一个单独以token级别的语言模型,在给定oracle plan情况下生成摘要,同时阻止它在给定随机plan的情况下生成相同的摘要,模型以MLE (最大似然)为损失函数。在推理期间,模型输入EDU使用beam search来为每一个EDU生成摘要。
修饰输入:作者用特殊的开始<e>和结束</e>token简单地划分plan中的EDU,这与PGA操作相似但不同。因为当训练生成plan的时候,所有EDU都被标记,然而在这个阶段,仅对plan中的EDU标记特殊的开始和结尾。作者指出这种方法是比修改模型编码器-解码器注意力机制更灵活的提取的方法,并且比单独对所提取的文本生成摘要更有效率。
损失函数表示如下:
其中表示来自参考文本的oracle plan,随机是来自非oracle的EDU的集合的相同长度的随机采样。前两个表达式时为了鼓励模型在生成抽象时依赖于plan,而最后一个表达式是标准的MLE,充当正则化项。和是控制损失函数上的计划服从性与正则化分量的相对权重。
实验结果
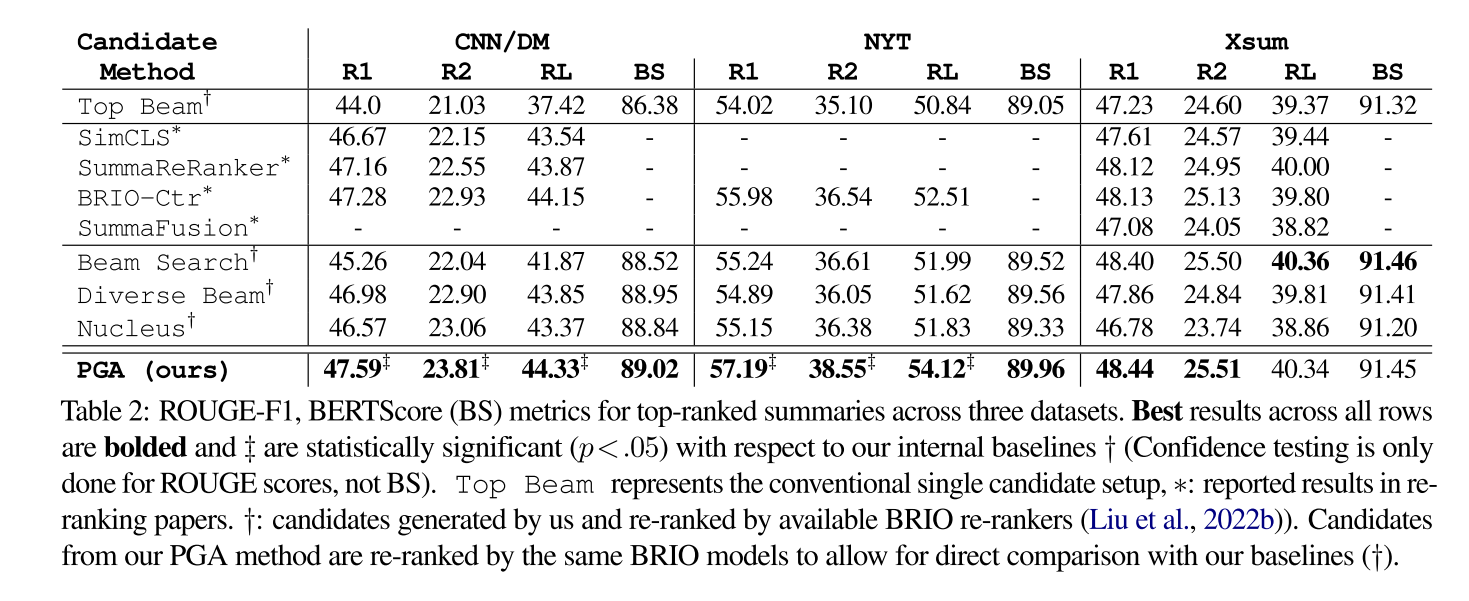
作者对比了PGA方法和不同生成候选摘要方法(beam search, diverse beam,nucleus sampling)在ROUGE和BERTScore得分上均显著提高。同时PGA方法也优于目前两步式摘要方法(SimCLS、SummaReRanker、BRIO-Ctr、SummaFusion)。
Prompting GPT-3.5 with PGA、
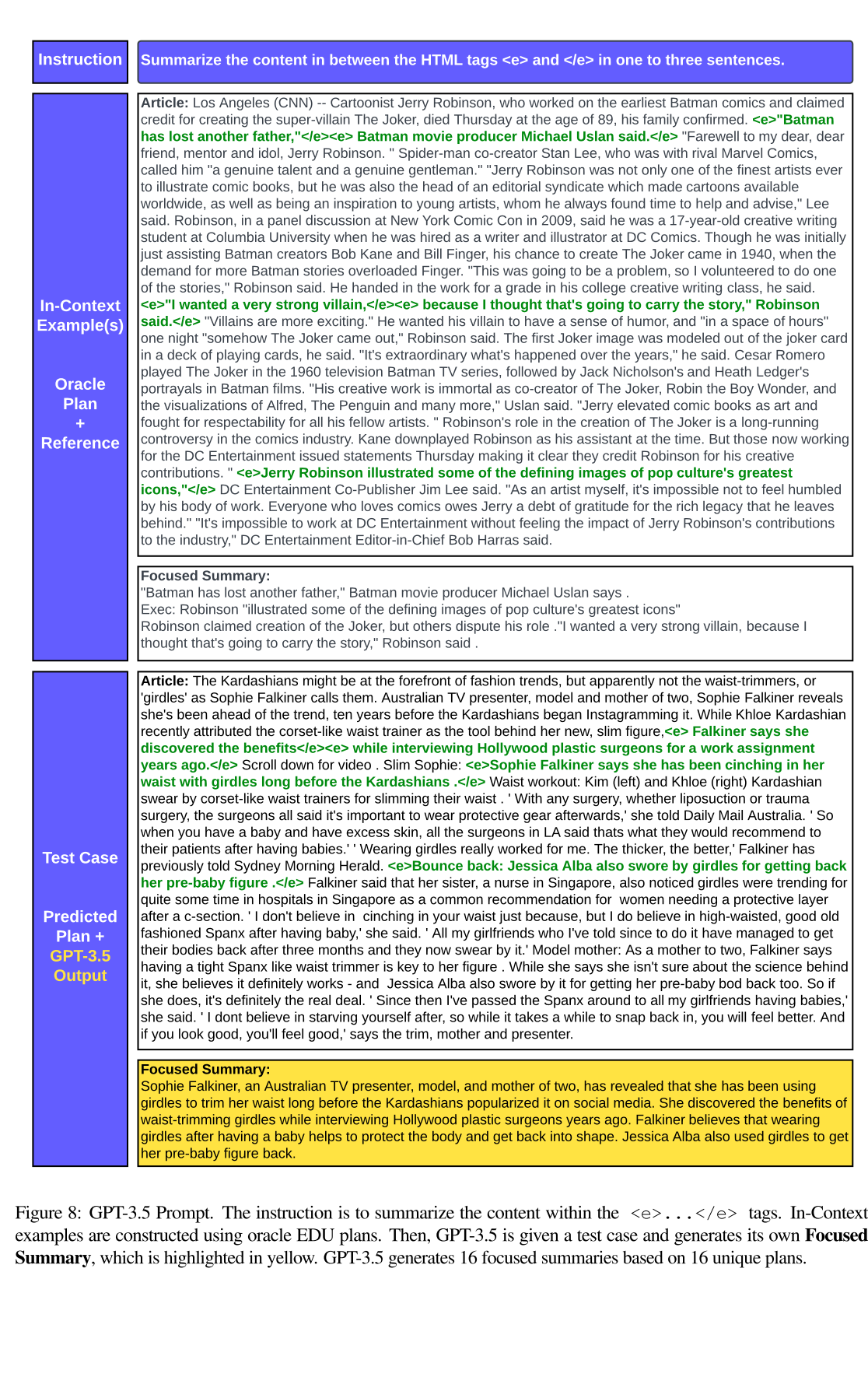
作者还使用in-context learning在ChatGPT中进行了实验,实验过程如下图所示:
参考文献
[2305.17779] Generating EDU Extracts for Plan-Guided Summary Re-Ranking (arxiv.org)